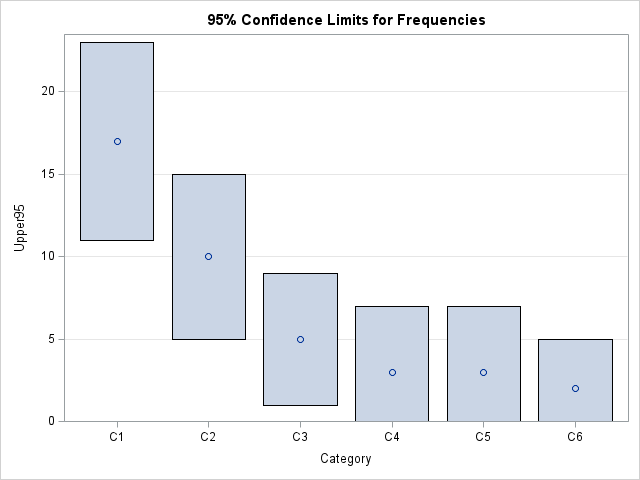
An alternative Pareto chart in SAS

Pareto charts are used by quality engineers to visually display a set of causes that produce defects in a manufacturing process. The chart is based on the famous Pareto Principle (the 80/20 rule), which states that 20% of the causes often produce 80% of the defects. If you focus on