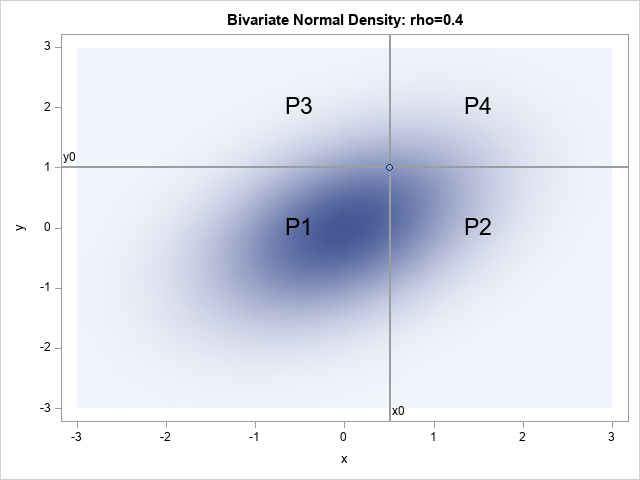
Compute the orthant probability for the 4-D multivariate normal distribution

This is the last article in a series about computing probabilities for the multivariate normal distribution. A previous article shows how to compute the probability of a standardized multivariate normal (MVN) distribution in an orthant for dimensions k=1, 2, and 3 by using the Childs-Sun formulas. The formulas are exact