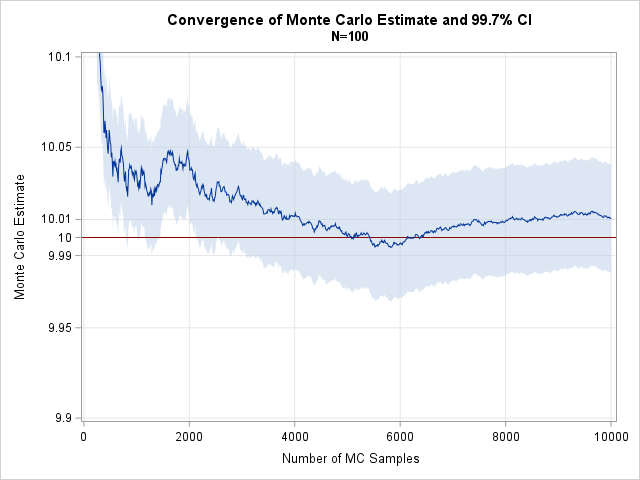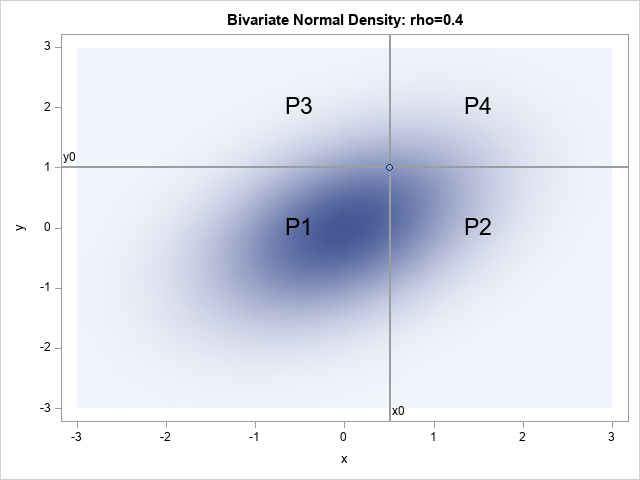
On standardizing multivariate normal probabilities

A course in elementary statistics always introduces the "Z-score." A Z-score is the result of standardizing a normally distributed random variable. By subtracting the distribution's mean and dividing by its standard deviation, you transform a general normal random variable into a standardized variable that has zero mean and unit standard