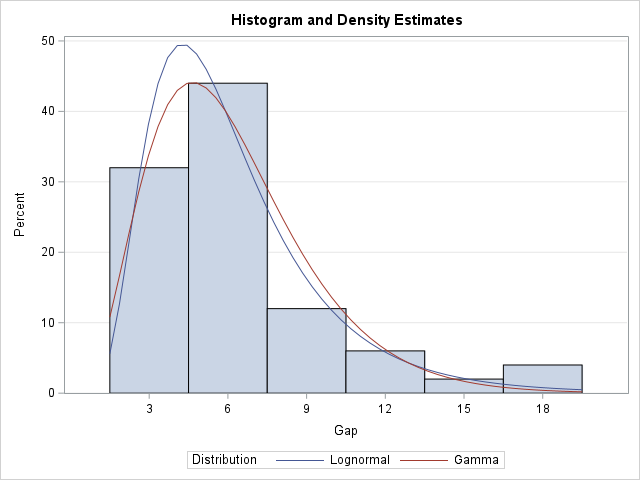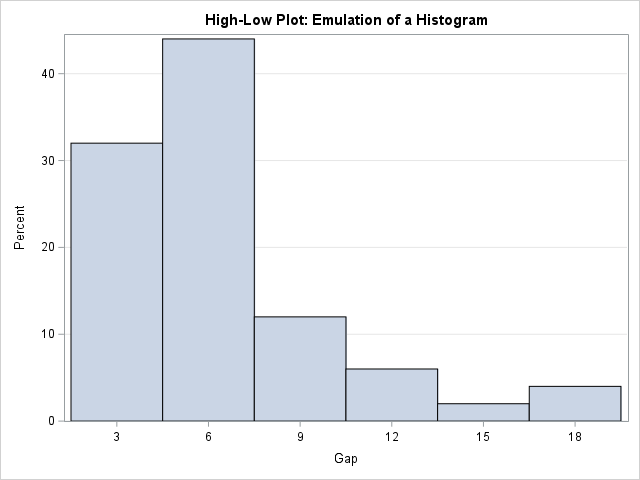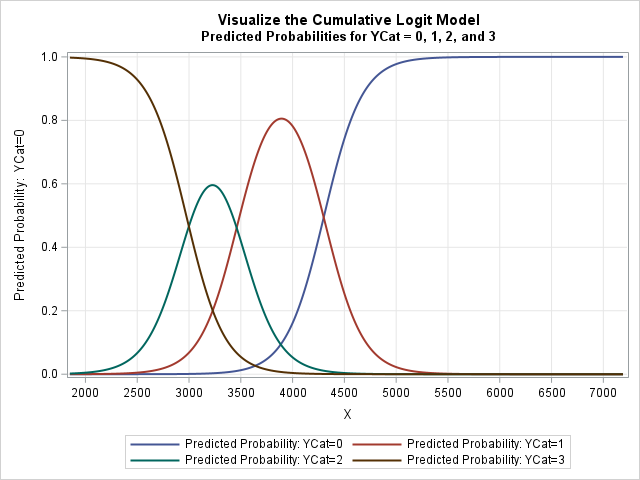
Visualize an ordinal response regression model

Many data analysts are familiar with logistic regression, where the response variable, Y, has two observed values, often represented as Y=0 and Y=1. The case Y=0 encodes that an event did not happen. For example, a patient did not experience some disease or did not die. The opposite case (Y=1)