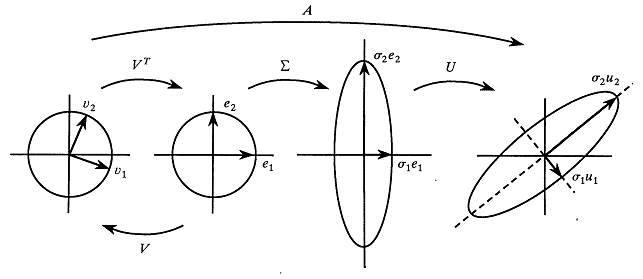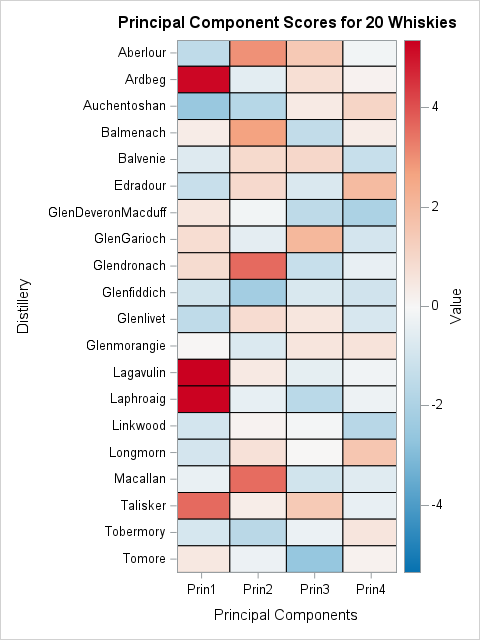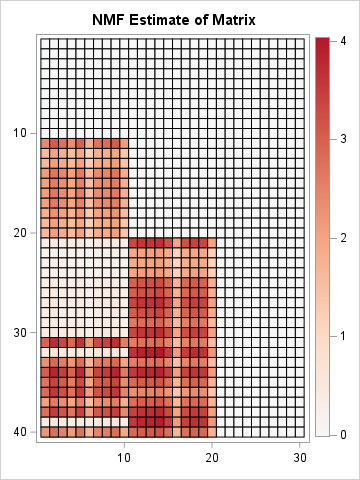
A comparison of SVD and NMF factorizations

The classical singular value decomposition (SVD) has a long and venerable history. I have described it as a fundamental theorem of linear algebra. Nevertheless, the mathematical property that makes it so useful in general (namely, the orthogonality of the matrix factors) also makes it less useful for certain applications. In