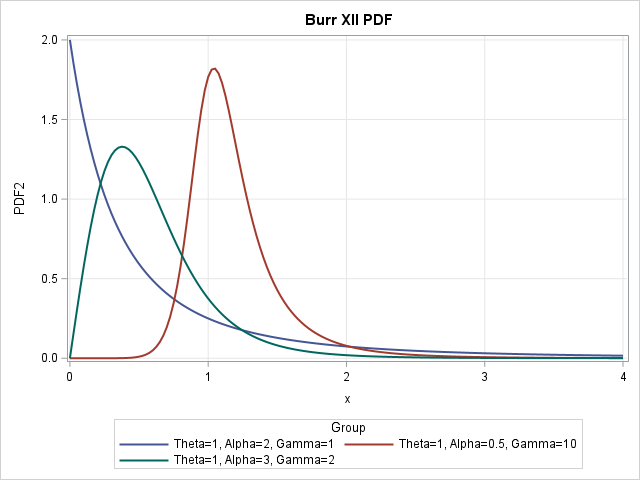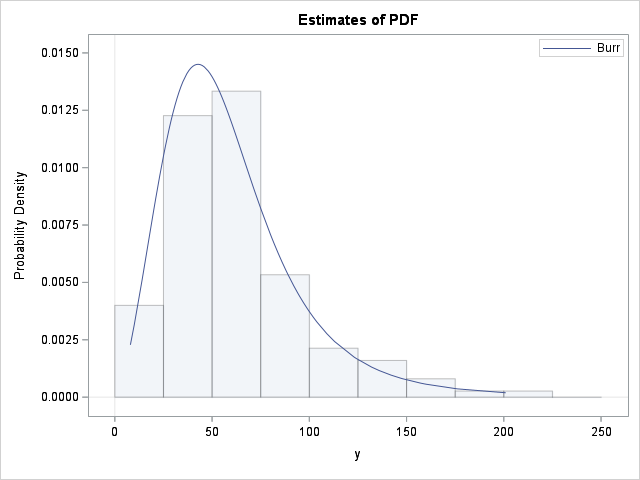
Fit the Burr distribution in SAS

A previous article shows how to use PROC FCMP to define the PDF, CDF, and quantile functions for the three-parameter Burr XII distribution. I also defined the log-PDF function, which is used during maximum likelihood estimation (MLE) of parameters. This article shows how to fit the Burr distribution to data