On The DO Loop blog, I write about a diverse set of topics, including statistical data analysis, machine learning, statistical programming, data visualization, simulation, numerical analysis, and matrix computations. In a previous article, I presented some of my most popular blog posts from 2020. The most popular articles often deal with elementary or familiar topics that are useful to almost every data analyst.
However, among last year's 100+ articles are many that discuss advanced topics. Did you make a New Year's resolution to learn something new this year? Here is your chance! The following articles were fun to write and deserve a second look.
Machine learning concepts
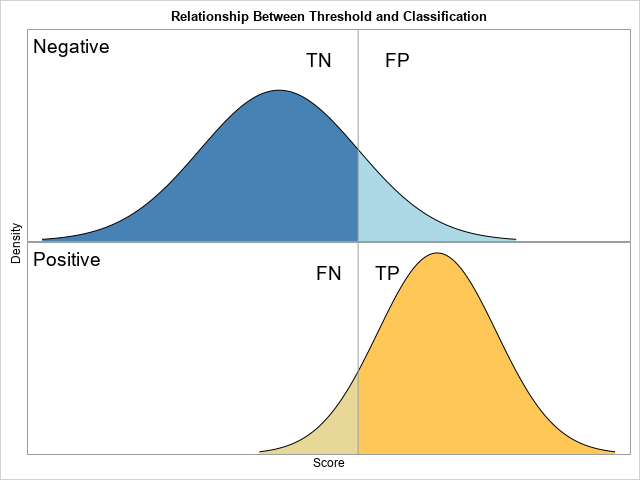
- Binary classification models: An important part of machine learning is classification, and the simplest classification problem is a binary classification. (For example, is this email spam or not?) There is a marvelous theoretical model, called the binormal model, which illuminates a lot of the concepts in binary classification, including true/false positives and negatives, and the all-important ROC curve. The ROC curve for a binormal model has an explicit formula, so you can compare the empirical ROC curves for random samples of data to the known curve for the population.
- The Kullback-Liebler divergence: The Kullbak-Liebler (K-L) divergence is a fancy-sounding name for a familiar idea: How can you measure when one distribution is "close to" another? You can use the K-L divergence to measure the similarity between two observed distributions or between a distribution and a model. The Kullback-Liebler divergence is fast to compute for a discrete distribution. If a model has parameters, you can choose the parameters to minimize the K-L divergence, which is equivalent to maximizing the likelihood between the model and the data. Although the discrete K-L divergence is used most often in machine learning, you can also consider the K-L divergence between two continuous distributions.
Statistical smoothers
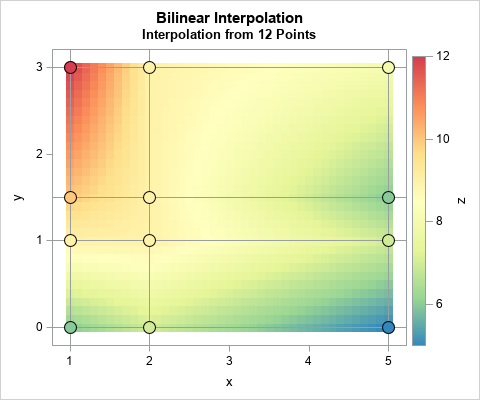
I write a lot about scatter plot smoothers, which are typically parametric or nonparametric regression models. But a SAS customer wanted to know how to get SAS to perform various classical interpolation schemes such as linear and cubic interpolations:
- Linear interpolation in SAS
- Cubic spline interpolation in SAS
- What is bilinear interpolation and how can you compute bilinear interpolation in SAS?
SAS Viya and parallel computing
SAS is devoting tremendous resources to SAS Viya, which offers a modern analytic platform that runs in the cloud. One of the advantages of SAS Viya is the opportunity to take advantage of distributed computational resources. In 2020, I wrote a series of articles that demonstrate how to use the iml action in Viya 3.5 to implement custom parallel algorithms that use multiple nodes and threads on a cluster of machines. Whereas many actions in SAS Viya perform one and only one task, the iml action supports a general framework for custom, user-written, parallel computations:
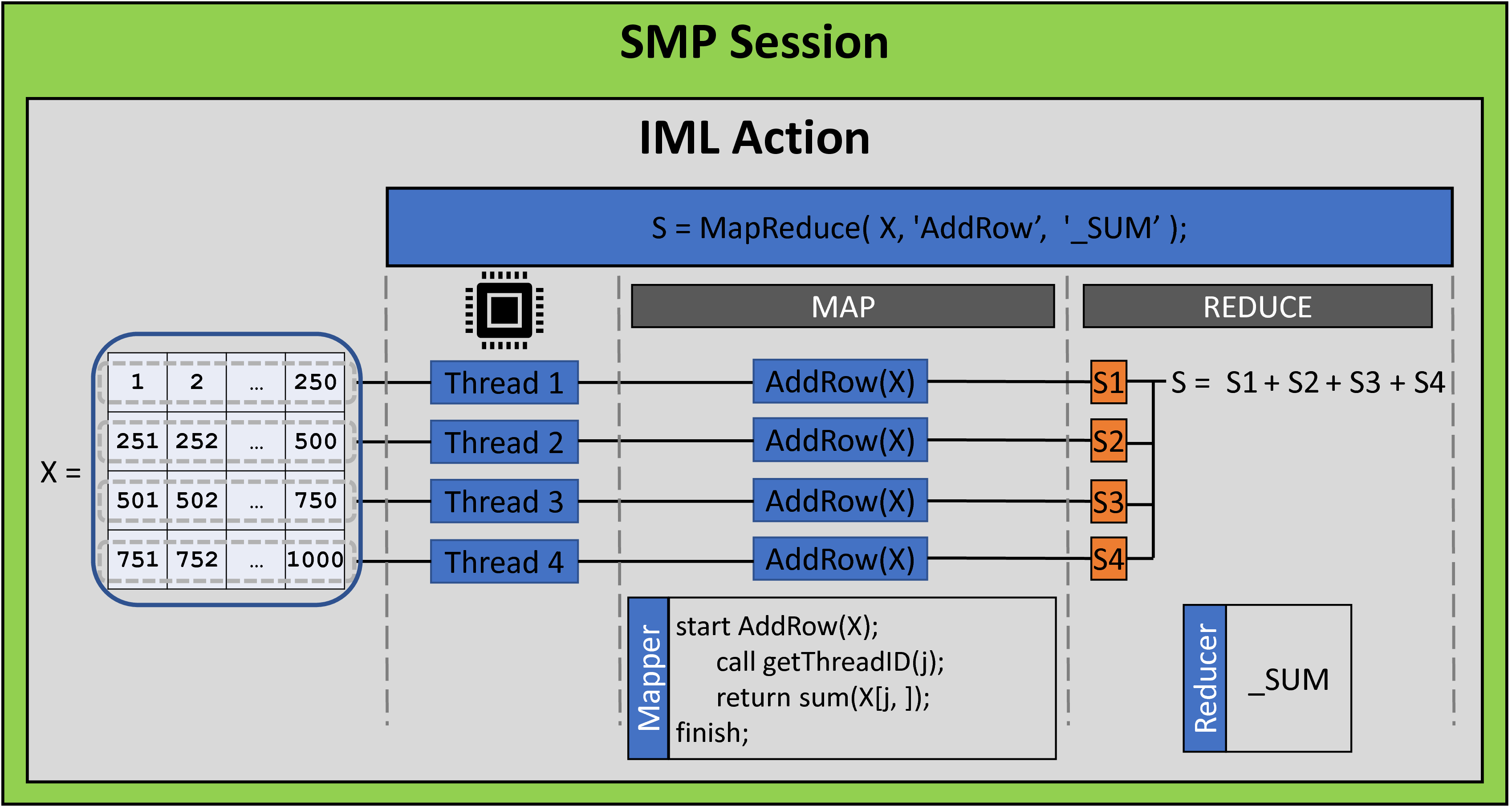
- The map-reduce paradigm is a two-step process for distributing a computation. Every thread runs a function and produces a result for the data that it sees. The results are aggregated and returned. The iml action supports the MAPREDUCE function, which implements the map-reduce paradigm.
- The parallel-tasks paradigm is a way to run independent computations concurrently. The iml action supports the PARTASKS function, which implements the map-reduce paradigm.
Simulation and visualization
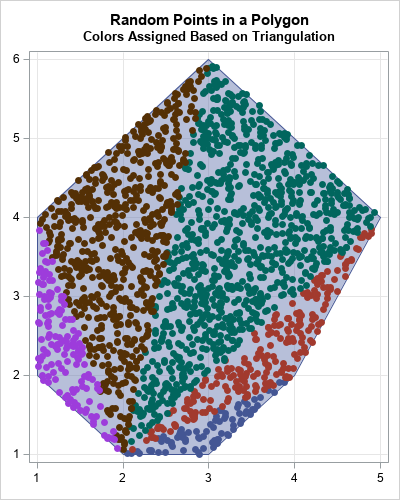
- I wrote many articles about statistical simulation, but a fun one is the article about how to generate random points in an arbitrary polygon.
- In some fields, a decile plot is a standard way to visualize agreement between the data and a regression model. It can be used to diagnose an incorrectly specified model. I show how to generate a decile plot in SAS and discuss alternative visualizations that are more powerful.
- Many statistical methods include ways to assess the uncertainty that is inherent in analyzing a random sample of data. Most SAS procedures include an option to display a 95% confidence band for the mean predicted value. However, it can be illuminating to display a continuous band plot that overlays multiple confidence bands, such as 5%, 10%, 15%, ..., 95%,
Your turn
Did I omit one of your favorite blog posts from The DO Loop in 2020? If so, leave a comment and tell me what topic you found interesting or useful. And if you missed some of these articles when they were first published, consider subscribing to The DO Loop in 2021.

1 Comment
A second look is always worthwhile with interesting reading :) Thanks for your excellent blog. Personally, I'll add the *Rewinding random number stream* to your list ; this 2-Factor authentication (2FA) explanation setup was absolutely revealing, especially for a feature now so common as to be required by law in some countries, for instance, in the EU retail banking sector (PSD2).
https://blogs.sas.com/content/iml/2020/08/26/rewind-random-number-stream.html