The iml action was introduced in Viya 3.5. As shown in a previous article, the iml action supports ways to implement the map-reduce paradigm, which is a way to distribute a computation by using multiple threads. The map-reduce paradigm is ideal for “embarrassingly parallel” computations, which are composed of many independent and essentially identical computations. I wrote an example program that shows how to run a Monte Carlo simulation in parallel by using the iml action in SAS Viya.
The map-reduce paradigm is often used when there is ONE task to perform and you want to assign a portion of the work to each thread. A different scenario is when you have SEVERAL independent tasks to perform. You can assign each task to a separate thread and ask each thread to compute an entire task. The iml action supports the PARTASKS function (short for "parallel tasks") for running tasks in separate threads. This article shows a simple example.
Three tasks run sequentially
Suppose you have three tasks. The first takes 2 seconds to run, the next takes 0.5 seconds, and the third takes 1 second. If you run a set of tasks sequentially, the total time is the sum of the times for the individual tasks: 2 + 0.5 + 1 = 3.5 seconds. In contrast, if you run the tasks in parallel, the total time is the maximum of the individual times: 2 seconds. Running the tasks in parallel saves time, and the speed-up depends on the ratio of the largest time to the total time, which is 2/3.5 in this example. Thus, the time for the parallel computation is 57% of the time for the sequential computation.
In general, the largest speedup occurs when the tasks each run in about the same time. In that situation (ignoring overhead costs), the time reduction can be as much 1/k when you run k tasks in k threads.
Let's run three tasks sequentially, then run the same tasks in parallel. Suppose you have a large symmetric N x N matrix and you need to compute three things: the determinant, the matrix inverse, and the eigenvalues. The following call to PROC IML runs the three tasks sequentially. The TOEPLITZ function is used to create a large symmetric matrix.
proc iml; N = 2000; A = toeplitz( (N:1)/100 ); /* N x N symmetric matrix */ det = det(A); /* get det(A) */ inv = inv(A); /* get inv(A) */ eigval = eigval(A); /* get eigval(A) */ |
The previous computations are performed by directly calling three built-in SAS/IML functions. Of course, in practice, the tasks will be more complex than these. Almost surely, each task will be encapsulated into a SAS/IML module. To emulate that process, I am going to define three trivial "task modules." The following statements perform The same computations, but now each "task" is performed by calling a user-written module:
start detTask(A); return det(A); finish; start invTask(A); return inv(A); finish; start eigvalTask(A); return eigval(A); finish; det = detTask(A); /* get det(A) */ inv = invTask(A); /* get inv(A) */ eigval = eigvalTask(A); /* get eigval(A) */ |
The syntax of the PARTASKS function
You can use the PARTASKS function to run the three tasks concurrently. To use the PARTASKS function, each task must be a user-defined SAS/IML function that has exactly one input argument and returns one output argument. For our example, the detTask, invTask, and eigvalTask modules satisfy these requirements. (If a task requires more than one input argument, you can pack the arguments into a list and pass the list as a single argument.)
The syntax of the PARTASKS function is
result = PARTASKS( Tasks, TaskArgs, Options );
where
- Tasks is a character vector that names the SAS/IML functions. For our example, Tasks = {'detTask' 'invTask' 'eigvalTask'};
- TaskArgs is a list of arguments. The i_th argument will be sent to the i_th module. In this example, each module takes the same matrix, so you can create a list that has three items, each being the same matrix: TaskArgs = [A, A, A];
- Options is an (optional) vector that specifies how the tasks are distributed. The documentation of the PARTASKS function gives the full details, but the first element of the vector specifies how to distribute the computation to nodes and threads, and the second element specifies whether to print information about the performance of the tasks. For this example, you can choose options = {1, 1};, which will distribute tasks to threads on the controller node and print information about the tasks.
Parallel tasks
Suppose you are running SAS Viya and you use the have access to a machine that has at least four CPUs. You can use the CAS statement to define a session that will use only one machine (no worker nodes). The CAS statement might look something like this:
cas sess0 host='your_host_name' casuser='your_username' port=&YourPort; /* SMP, 0 workers */
Then you can run the PARTASKS function by making the following call to the iml action. If you are not familiar with the iml action, see the getting started example for the iml action.
proc cas; session sess0; /* SMP session: controller node only */ loadactionset 'iml'; /* load the action set */ source partasks; /* put program in SOURCE/ENDSOURCE block */ start detTask(A); /* 1st task */ return det(A); finish; start invTask(A); /* 2nd task */ return inv(A); finish; start eigvalTask(A); /* 3rd task */ return eigval(A); finish; /* ----- Main Program ----- */ N = 2000; A = toeplitz( (N:1)/100 ); /* N x N symmetric matrix */ Tasks = {'detTask' 'invTask' 'eigvalTask'}; Args = [A, A, A]; /* each task gets same arg in this case */ opt = {1, /* distribute to threads on controller */ 1}; /* display information about the tasks */ Results = ParTasks(Tasks, Args, opt); /* results are returned in a list */ /* the i_th list item is the result of the i_th task */ det = Results$1; /* get det(A) */ inv = Results$2; /* get inv(A) */ eigval = Results$3; /* get eigval(A) */ endsource; iml / code=partasks nthreads=4; run; |
The results are identical to the sequential computations in PROC IML. However, this program executes the three tasks in parallel, so the total time for the computations is the time required by the longest task.
Visualize the parallel tasks computations
You can use the following diagram to help visualize the program. (Click to enlarge.)
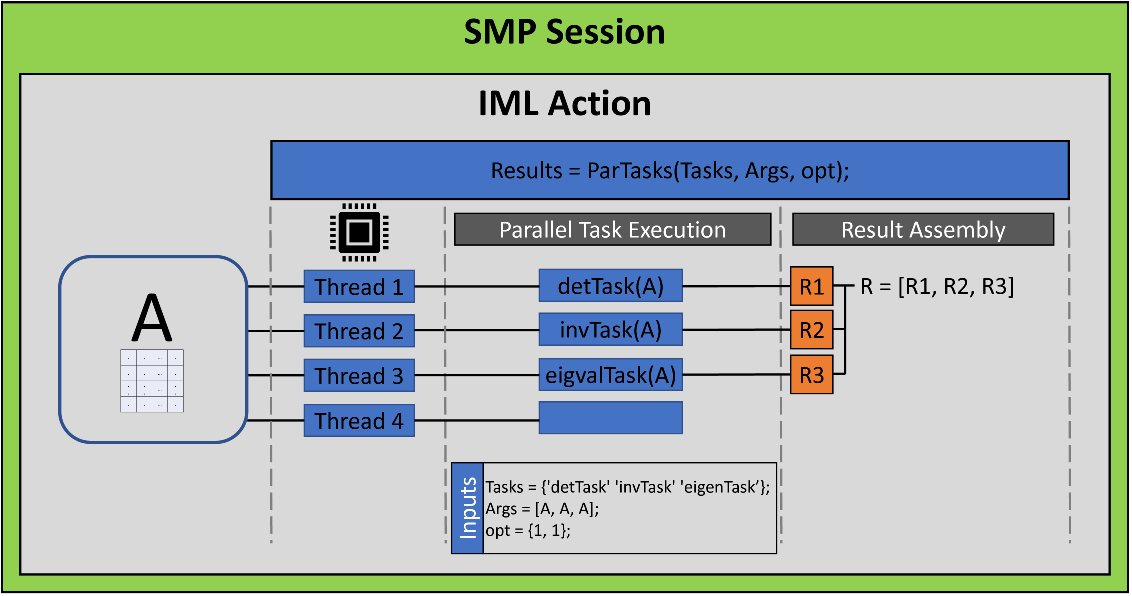
The diagram shows the following:
- The CAS session does not include any worker nodes. Therefore, the iml action runs entirely on the controller, although it can still use multiple threads. This mode is known as symmetric multiprocessing (SMP) or single-machine mode. Notice that the call to the iml action (the statement just before the RUN statement) specifies the NTHREADS=4 parameter, which causes the action to use four threads. Because there are only three tasks, one thread remains idle.
- The program defines the matrix, A, the vector of module names, and the list of arguments. When you call the ParTasks function, the i_th argument is sent to the i_th module on the i_th thread.
- Each thread runs a different function module. Each function returns its result. The results are returned in a list. The i_th item in the list is the result of the call to the i_th function module.
Summary
This article demonstrates a simple call to the PARTASKS function in the iml action, which is available in SAS Viya 3.5. The example shows how to distribute tasks among k threads. Each thread runs concurrently and independently. The total time for the computation depends on the longest time that any one thread spends on its computation.
This example is simple but demonstrates the main ideas of distributing tasks in parallel. In a separate article, I present a more compelling example: How to estimate a power curve in parallel.
For more information and examples, see Wicklin and Banadaki (2020), "Write Custom Parallel Programs by Using the iml Action," which is the basis for these blog posts. Another source is the SAS IML Programming Guide, which includes documentation and examples for the iml action.
