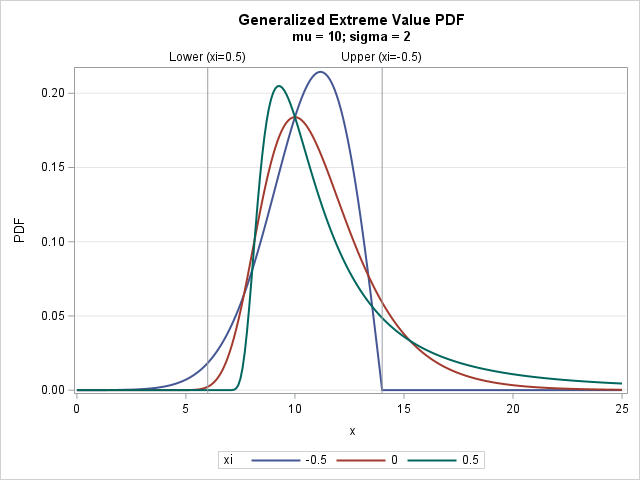
Implement the generalized extreme value distribution in SAS

SAS supports more than 25 common probability distributions for the PDF, CDF, QUANTILE, and RAND functions. If you need a less-common distribution, you can implement new distributions by using Base SAS (specifically, PROC FCMP) or the SAS/IML language. On the SAS Support Communities, a SAS programmer asked how to implement