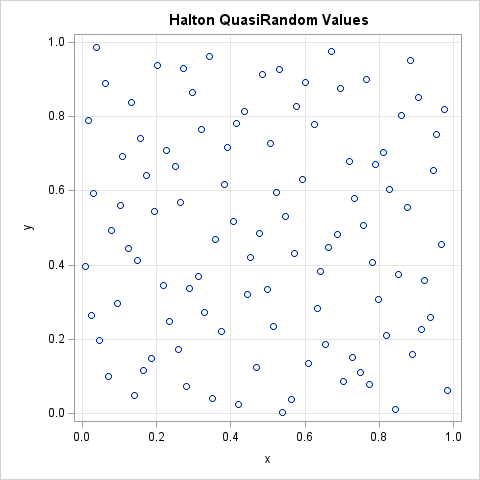
Create a Halton sequence in SAS

A previous article shows how to convert a positive integer from base 10 to any other arbitrary base. For example, 15 (base 10) = 120 (base 3) because 15 = 1*32 + 2*31 + 0*30. Representing integers is probably familiar to many readers. But did you know that you can



