Incentivize AI development and reduce administrative overhead! This article is co-authored by Sundaresh Sankaran, Reza Nazari and Suneel Grover from SAS Institute.
We all need easy and smooth!
Reinforcement Learning (RL) models seek to maximize a given objective throughout many sequential transactions and require an environment to retain the context (activity, time, stage and status) around such transactions. SAS RL algorithms use environments built-in Python for training and scoring exercises.
Multiple environments carry opportunity and complexity costs beyond just the additional infrastructure required. Users must understand and translate RL environment requirements for administrators to stand up, which poses a hurdle to rapid development. Significantly, pre-requisites to set up and serve this Python environment inhibit data scientists from even trying out SAS RL. Data scientists get deterred from exploiting our powerful algorithms.
Wouldn’t it be cool if we establish a mechanism that provides more data scientists easy access to SAS Reinforcement Learning capabilities, from a centralized location and using a standardized approach?
Sometimes, the answer lies outside...
From the beginning, we looked to use appropriate technology beyond the current programming-heavy approaches that call SAS Viya Cloud Analytic Services (CAS) actions through Python. Therefore, we exploited the container orchestration platform supporting Viya – Kubernetes.
We encapsulated the Python RL environment into a container and deployed it on the same Kubernetes cluster serving Viya 4. This ensures that both the RL environment and CAS (engine running RL algorithms on SAS Viya) are part of the same environment.
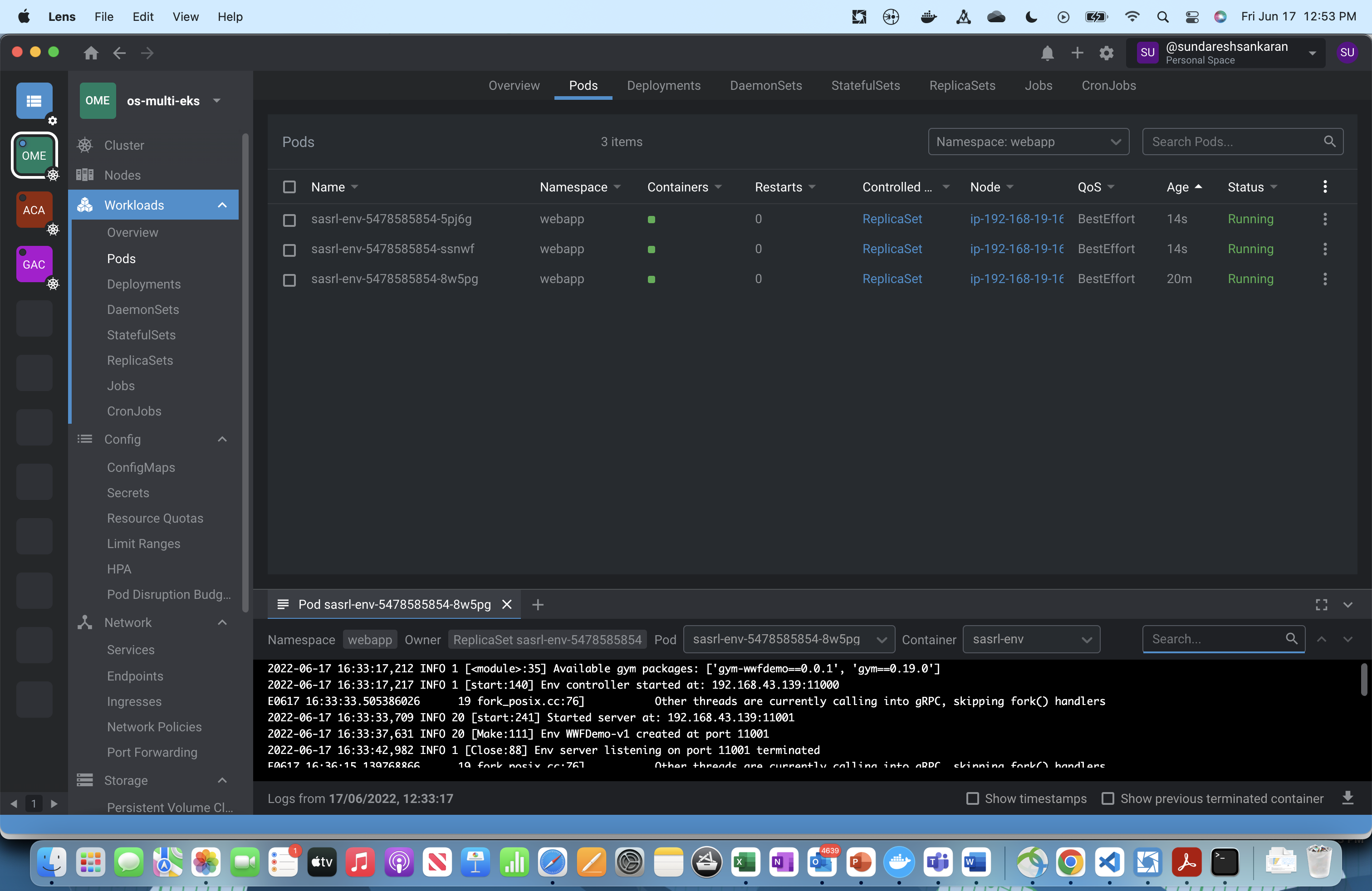
Users now have an easy option to build reinforcement learning models inside SAS Studio. Look at the screenshot below. All that data scientists need to specify is a standard URL pattern, which is known in advance and need not be modified. Data scientists can focus on activities relating to training an RL model and related analysis, instead of having to worry about setting up an environment from scratch!
This solves the issue of users requiring a Python environment on a Linux server and establishing communication with SAS Viya. Such steps are of light to moderate complexity for application administrators but are not the core competencies of data scientists! With our solution, all users need is a single shared resource - a Kubernetes deployment- which can be scaled up (through replicas) to accommodate higher demand.
The solution also offers resilience since the cluster manages itself and maintains its state. Therefore, if the environment were to fail for any reason, the same can be easily restarted with minimal user disruption.
Furthermore, this deployment is exposed to users as a Service, which makes sure that irrespective of the (internal) IP of this container, there is always one common point of reference (a common, standard URL) that users can refer to during their RL training exercises.
The net result? A much more enjoyable analytical experience and no need to change or remember multiple URLs or port numbers!
How do you do this?
This section is intended for those interested in the technical details of how we carried out the steps necessary to establish a single RL environment. Feel free to skip this section and move to the summary in case all you are interested in is the main message. We plan to follow up with information and repositories which provide more technical details.
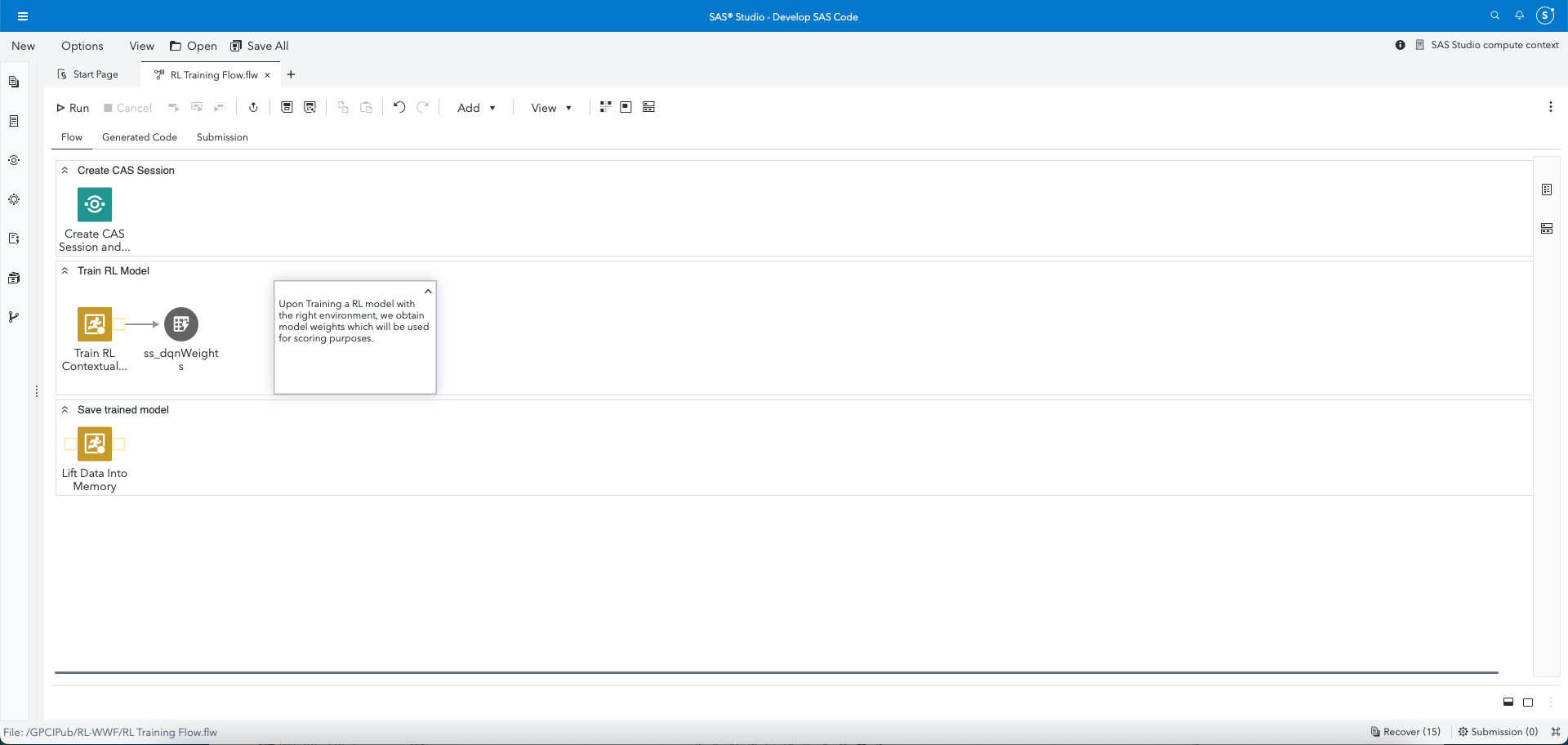
As we outlined the technical steps involved, we realized the great thing about this solution was that the user community really needn’t be bothered with the administrative details of setting up an RL environment. A huge productivity boost, this allows users to concentrate on their core task – train (and score) RL models. Administrators and the overall organization would like things this way. For one, they have only one centralized environment to worry about. Also, ownership of the RL environment at an early stage makes them better prepared to handle failure events.
The following steps are one-time activities that can also accommodate new future environments.
- First, the data scientist identifies the environment they wish to package. Obviously dependent on the use case, a typical environment to build packages is “gym”, widely used as a standard API for reinforcement learning. When you try out this activity, we suggest starting off with a pre-built environment such as Cart-Pole, etc. which is provided by gym.
- Next, tool up your environment controller. For this purpose, SAS has published a GitHub package – sasrl-env, which helps communicate with the Python RL environment. After installation and startup, the server makes a controller service available at a specified port (11000). This controller service accepts requests and based on the environment requested, will direct control to other environment-specific services that have been set up.
- The administrator builds an image through a Dockerfile. This is the act of packaging all the necessary components into an image that can be run as a container on Kubernetes.
- Time to promote! Promote your image to a registry. In the SAS Viya environment, Kubernetes will be directed to pull this image from the registry through a Deployment file.
- Administrators expose this deployment as a Kubernetes service, steps for which are part of the same manifest file. The service is referred through a standard URL pattern on the lines of other Kubernetes services, which is made available to the data scientist user community!
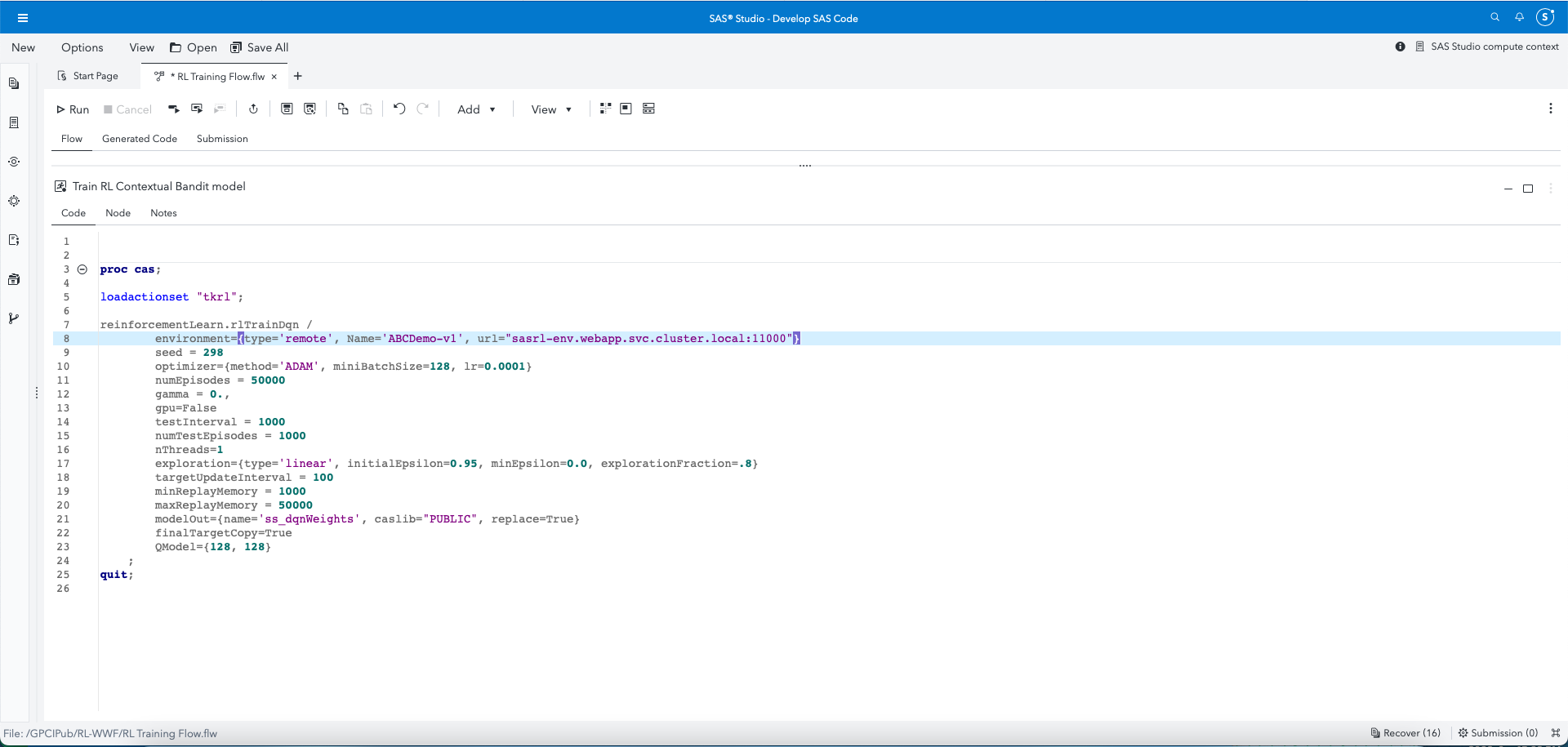
Following this, the data scientist needs only refer to the URL pattern within CAS actions to train and score RL models. For example, here’s how a data scientist would refer to an environment while training a Deep-Q network RL model.
reinforcementLearn.rlTrainDqn /
environment= {type='remote', Name='ABCDemo-v1', url="sasrlenv.
webapp.svc.cluster.local:11000"} |
Summing up
Analytics and AI flourish when easy user experiences are prioritized and barriers to adoption are removed! Containerization and orchestration technologies like Kubernetes are excellent and convenient mechanisms through which we can package third-party applications for appropriate use alongside SAS Viya.
Regarding the specific area of Reinforcement Learning, several other opportunities exist to ease access and promote adoption, such as providing capabilities for environment definition and adding newer custom environments on the fly. We’ll continue to investigate such areas and hope others do, too!
References
- DNS for Services and Pods: Kubernetes documentation
- Reinforcement Learning for SAS Visual Data Mining and Machine Learning, SAS Communities blog
- Gym documentation
- Sasrl-env documentation
- SAS Viya Cloud Analytic Services
- SAS Studio Flows
- How to use a Dockerfile
- Promoting your image to a registry
- Exposing deployments and services