Editor's note: This article is followed up by Toxicity, bias, and bad actors: three things to think about when using LLMs and Three ways NLP can be used to identify LLM-related private data leakage and reduce risk.
When you think about modeling and data quality, the first thing that often comes to mind is rows and columns and standardizing fields. Maybe it’s something straightforward like ensuring address fields are in the same format, or maybe it’s more complex like examining distributions of important numeric fields and identifying outliers. Often people don’t think about the quality of their unstructured text data. How do you standardize text? What do you look for, and why does it matter in the realm of generative AI?
How does data quality affect LLMs?
Large language models (LLMs), the heart of generative AI, require tremendous amounts of data to pretrain—trillions of tokens. This provides them with a linguistic base so they can answer general questions using coherent, syntactically and grammatically correct language. To have an LLM answer domain-specific questions effectively, it needs to be exposed to data related to that domain. This is where the quality of an organization's unstructured data becomes important.
With text-related models like LLMs, more data isn't necessarily better. If the text data has a lot of noise, duplication, or ambiguity, it can increase compute and storage costs and skew results. LLMs are high-powered probabilistic next word generators, so the quality of the data they’re exposed to has a direct impact on the results that they generate. This is an area where semantic rules-based natural language processing (NLP) techniques and the ability to profile text data can add value to LLMs.
NLP as a data quality engine
Natural language processing is a domain rich with capabilities that can be used to manage all aspects of unstructured text data, well beyond text generation. Over the past 10 years or so, linguistic rules-based approaches have widely been discarded in favor of black-box machine learning techniques, but they still have a tremendous amount of merit in being able to understand deep nuance in language, incorporate subject matter expertise, and blazing-fast performance. Some rules-based models can run 9000 times faster machine learning techniques, making them perfect for real-time analysis.
SAS NLP has a comprehensive suite of linguistic rules called LITI—Language Interpretation for Textual Information. LITI can be used to do everything from basic information extraction at keyword levels to complex fact extraction based on deep relationships between terms and phrases. LITI offers a wealth of capabilities to address text data quality issues and help users target appropriate data, reducing the noise in text.
LLMs in action
Consider a call center for a large financial services company. They may receive half a million calls a month. The calls are transcribed to text, and they’d like to be able to use a LLM to better understand trends. They could take a year's worth of data and feed it into the LLM in a fine-tuning step—roughly 6 million call records. Not only would that data have duplication and similarity across records, but it could have hidden privacy concerns. There might be mentions of names, account numbers, and other elements of personally identifiable information (PII).
The data could contain contextual ambiguities and inconsistencies. For example, a customer might say, “I’d like to close my account” without a mention of the type of account. It could also have inconsistencies—particularly in entity names like financial products or services. In some conversations product names may be referred to in different ways. In these cases, the model may return vague or incomplete information or struggle to generate appropriate responses to questions about product related tasks.
Addressing bias and privacy concerns
Finally, there’s the topic of bias. Bias exists everywhere in a variety of forms and can be subtle. LLMs can amplify or project bias that exists in both the pre-training data (that organizations don’t have control over) and in data being used to fine-tune. It’s important to do due diligence to ensure that organizations aren’t perpetuating bias in their models.
LITI can be used to build models that can identify and target records that contain PII, not just traditional entities like names, addresses, or social security numbers, but also patterns of PII that may be specific to an organization or business unit. Once identified, the choice can be made to either redact the PII or exclude entire records containing PII from the corpus used to fine-tune the LLM.
Managing ambiguity
Because LITI can be used to capture deep nuance in language, disambiguation at the word sense level and higher levels like business related jargon or terms can be simplified. Ambiguities and inconsistencies can be identified and automatically accounted for or flagged for deeper examination. Records without enough context to properly disambiguate can be discarded from the corpus. The ability to capture deep nuance doesn’t just help with disambiguation but can also help differentiate between benign language and biased or harmful language.
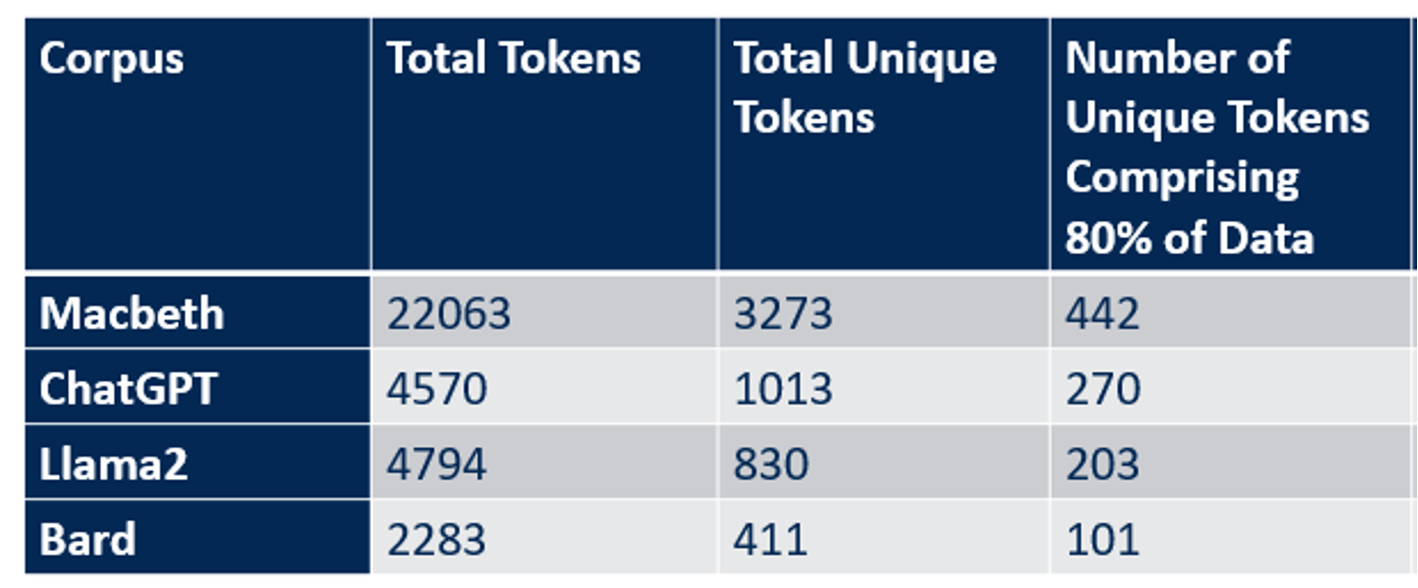
SAS has patented text profiling options that generate descriptive statistics about text corpora starting with the number of tokens, which is valuable for estimating the per-token cost of using the corpus with an LLM. Understanding the composition of a corpora can help with duplication and similarity detection. Once identified, the duplicate or near-duplicate documents can be filtered out, reducing the size of the corpus to be used for fine-tuning.
The power of SAS NLP
These examples just scratch the surface of what’s possible when you add the finesse of linguistic methods in SAS NLP with LLMs. These techniques not only help address quality issues in text data, but because they can incorporate subject matter expertise, they give organizations a tremendous amount of control over their corpora. In some cases, it’s possible to reduce the size of the corpus being used to fine-tune by as much as 90%. By curating better data for fine-tuning, you can realize better responses from LLMs, minimize the incidence of hallucination, and create a method to validate the responses.







1 Comment
I find it fascinating how combining SAS NLP with LLMs can significantly improve text data quality and reduce the corpus size for fine-tuning by up to 90%. It’s impressive how this approach enhances LLM performance, reduces hallucinations, and allows for better validation of responses. Very insightful!