DataOps is rapidly turning from a fragmented usage of some tools popular in the software development world into a modern approach to data & analytics engineering with its own best practices and recommended technologies.
While the goal of DataOps – delivering data and analytical insights of the highest quality faster – remains quite clear, it may not be obvious where DataOps fits into the existing data and analytics landscape. More importantly, what are the key areas to foster and invest in developing a successful DataOps strategy?
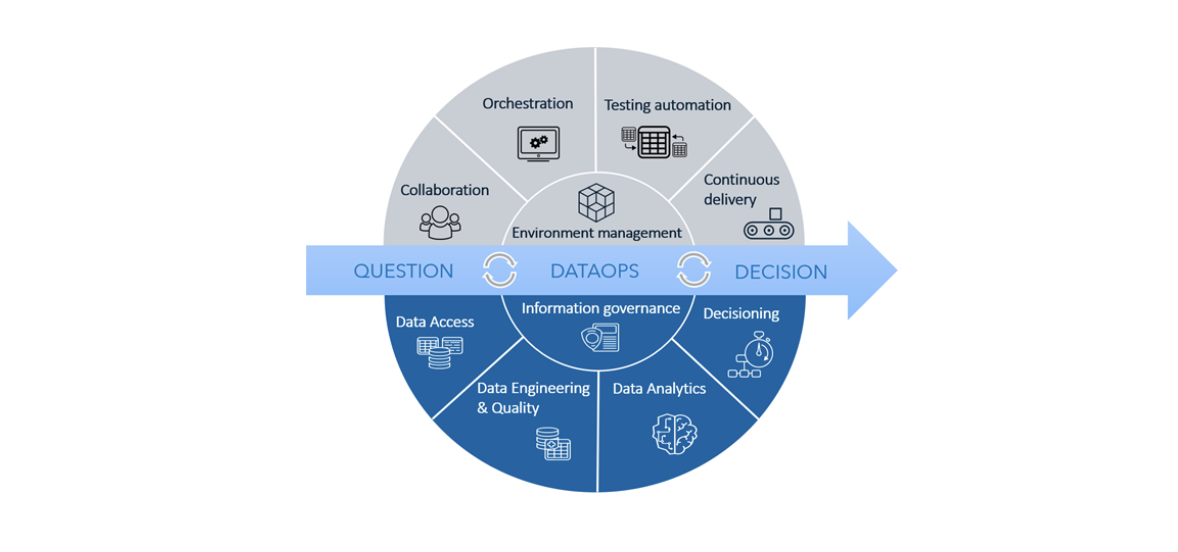
How DataOps fits into data and analytics lifecycle
Over the years, technologies for data access, data transformation, building machine learning models and decisioning have proven their value and become a must-have for a data-driven organization. These technologies belong to the data processing layer, everything that resides in the blue lower semi-circle in the diagram.
What DataOps adds, in turn, is a set of practices and respective technologies aimed to make this data processing layer operational and automate as many routines and manual processes as possible. The grey-colored semi-circle that accompanies the whole data & analytics lifecycle is the DataOps layer.
It’s all groups of users who participate in and benefit from DataOps: data engineers, data scientists, business intelligence analysts, DevOps engineers (operationalists) as well as business consumers. DataOps helps data engineers to automate and make data pipelines more reliable and agile. It frees data scientists to spend time on high‑value initiatives like model development and optimization instead of working on embedding models into business processes. It provides transparency and helps business consumers to better understand data flow behind different indicators and reports. DataOps allows all users to collaborate more efficiently together.
Many practices of DataOps have been around for quite some time in the software development world. However, it's crucial to understand that data dimension does not exist in the software development workloads. Thus, even though DevOps laid the foundation for software development principles, these practices should be tailored explicitly for data-focused applications to reflect the unique needs of DataOps. Some other principles come from the evolution of existing data processing stacks.
In addition, some technologies do not necessarily fall into the DataOps domain but work alongside it in a single framework. Data governance is located at the edge of data processing and DataOps areas and is a glue between them. In support of DataOps, it allows for finding, unambiguously identifying and classifying data that delivers value and guarantees data privacy and security.
5 pillars of DataOps
In one way or another, DataOps focuses on the following main areas:
- Collaboration.
- Orchestration.
- Continuous delivery.
- Testing automation.
- Environmental management.
Collaboration
With the growing demand for faster analytical insights, it's now relatively common for a few team members – whether data engineers or data scientists – to work on the same project or even the same artifact together. But accelerating the development also requires introducing proper and robust means of collaboration. One of the essential requirements when introducing a collaboration framework is the ability to track the history of changes, compare and restore different versions of artifacts, quickly resolve conflicts and develop multiple features in parallel in independent branches.
The collaboration framework should also ensure effortless sharing of assets of several types via a central shared repository so these assets can be reused in other projects and/or as part of other artifacts. It should also provide simple but structured means of communication between team members.
Orchestration
It's not enough to produce siloed artifacts and share them in a central repository. To solve a specific business use case, artifacts of several types should be seamlessly orchestrated together, starting from a successful data ingestion, proceeding with building or retraining a machine learning model, and ending up with communicating insights back to the business application.
This is where orchestration technologies come into play. Orchestration processes allow integrating assets of multiple types (like data transformation flows, models, API calls, etc.) in a value pipeline that can serve as a single pane of glass for understanding, building and monitoring a specific process. As such, orchestration flows should also be versioned and shareable.
Testing automation and monitoring
It's great to have individual functional assets and orchestration pipelines in place, but it's not enough to reach a desired state of operationalization. Why? There are multiple reasons. These pipelines and assets are typically dependent on other systems, it's not always possible to foresee all exceptional use cases. Additionally, a change in one artifact can cause a failure of a larger pipeline where this artifact is used. So, it's essential to have a strategy of automated testing and a respective testing framework.
Such a framework should allow for automated test runs, provide the ability to store and share results in standard formats and provide notification and alerting capabilities.
Continuous delivery
Finally, the speed and quality of content promotion between development and production environments are crucial in accelerating the analytics lifecycle. Implementing an automated continuous integration/continuous delivery (CI/CD) approach (in cooperation with testing automation) reduces the time needed to deliver and embed data pipelines, machine learning models and decisions into production and reduces the probability of errors caused by manual interventions.
Though automation is crucial here it should also be possible to incorporate the functionality of manual approvals and enable additional validation as part of this process. The ability to version continuous delivery pipelines should also be supported.
Environmental management
And the final pillar in enabling the DataOps strategy is the ability to quickly provision multiple rich development environments in a repeatable and flexible manner. It allows isolating development work in individual secure sandboxes where engineers can access tools of their choice and necessary permissions for extending their sandbox as needed. This eliminates dependencies between different versions of multiple tools and technologies that might exist when multiple environments are hosted together and can also save costs, e.g., by turning off a specific environment when needed.
This approach can also be applied to isolated continuous integration and lightweight, secure production environments.

1 Comment
Hey Alexey! Thank you for this wonderful blog!