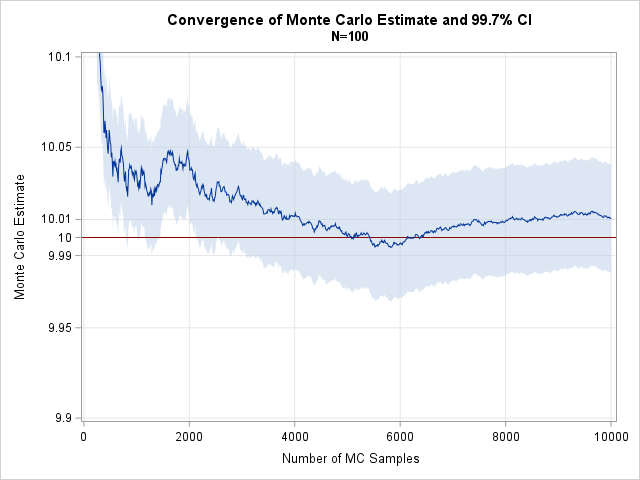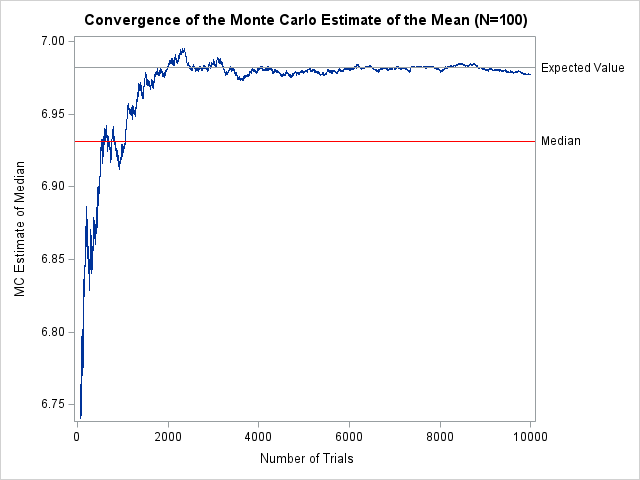
The sample median is a biased estimator for skewed distributions

Did you know that, for skewed distributions, the sample median is a biased estimator of the population median? You can show this in two ways. For any distribution, you can run a Monte Carlo simulation that reveals the bias. And, for some distributions (such as the exponential distribution), you can