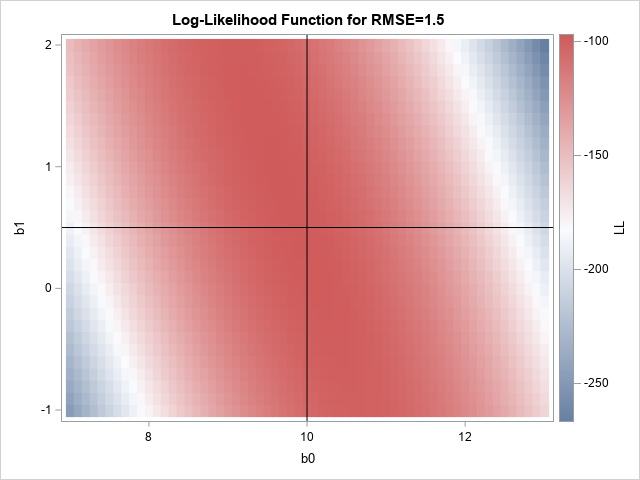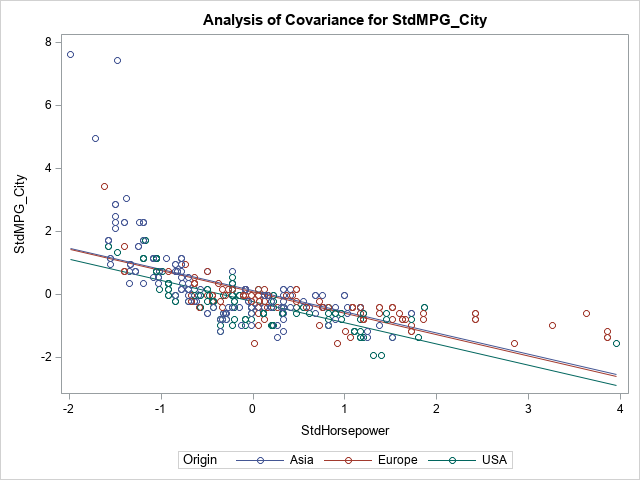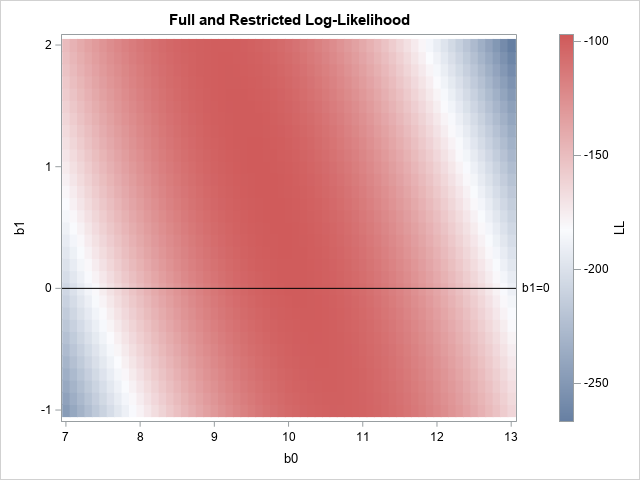
The likelihood ratio test for linear regression in SAS

A recent article describes how to estimate coefficients in a simple linear regression model by using maximum likelihood estimation (MLE). One of the nice properties of an MLE formulation is that you can compare a large model with a nested submodel in a natural way. For example, if you can