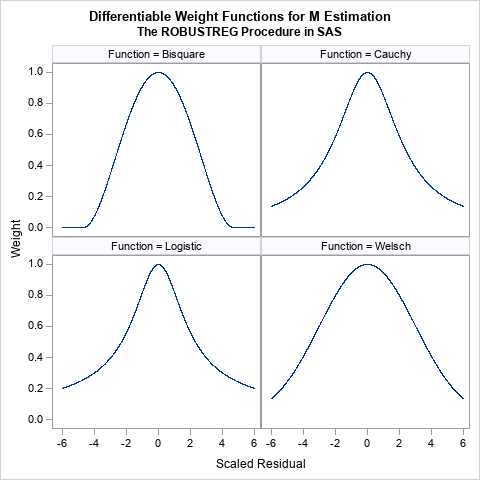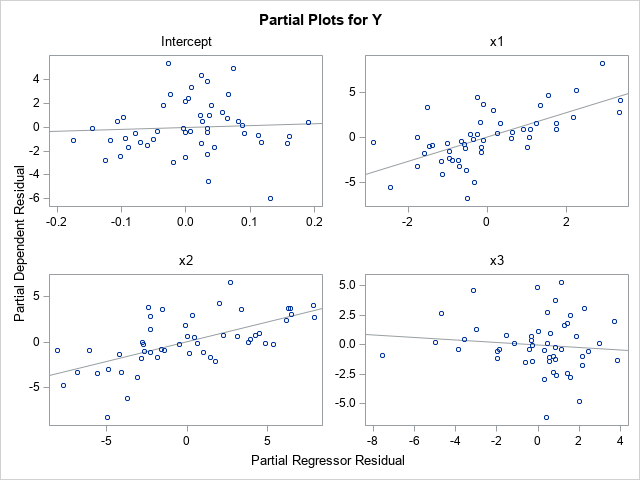
Partial leverage plots

For a linear regression model, a useful but underutilized diagnostic tool is the partial regression leverage plot. Also called the partial regression plot, this plot visualizes the parameter estimates table for the regression. For each effect in the model, you can visualize the following statistics: The estimate for each regression