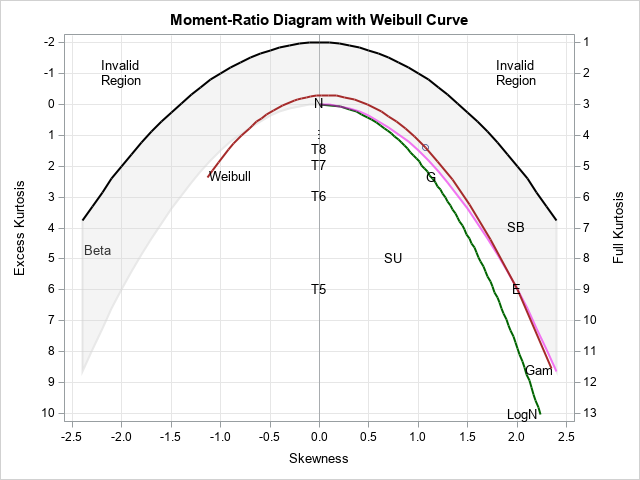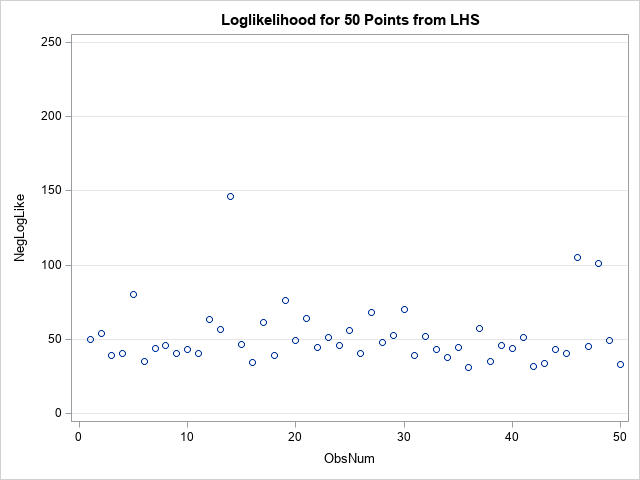
An application of Latin hypercube sampling to optimization

A previous article discusses a "Catch-22" paradox for fitting nonlinear regression models: You can't estimate the parameters until you fit the model, but you can't fit the model until you provide an initial guess for the parameters! If your initial guess for the parameters is not good enough, the nonlinear