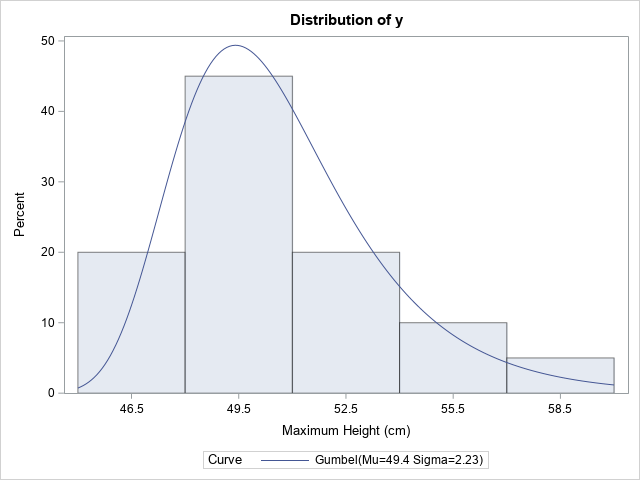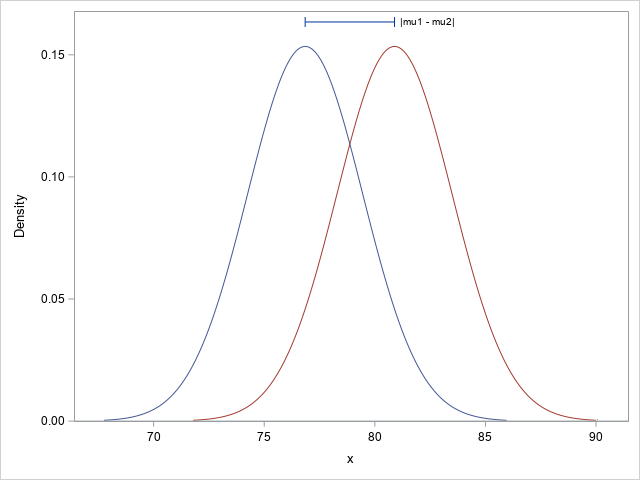
Confidence intervals for Cohen's d statistic in SAS

A previous article discusses Cohen's d statistic and how to compute it in SAS. For a two-sample independent design, Cohen's d estimates the standardized mean difference (SMD). Because Cohen's d is a biased statistic, the previous article also computes Hedges' g, which is an unbiased estimate of the SMD. Lastly,