This article shows how to classify a set of high-dimensional data into orthants. An orthant is the d-dimensional generalization of a quadrant.
For 2-D Euclidean space, there are four quadrants, often labeled by Roman numerals I-IV. The quadrants are open sets that are defined by the signs of each coordinate of a point (x1, x2). Traditionally, the quadrants are enumerated counterclockwise from the positive x axis, as follows:
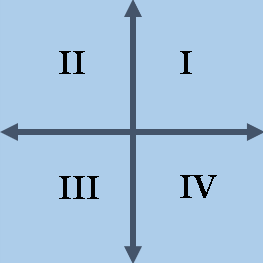
- I: The first quadrant is defined by {(x1,x2) | x1 > 0 and x2 > 0}. The signs of the coordinates are '++'.
- II: The second quadrant is defined by {(x1,x2) | x1 < 0 and x2 > 0}. The signs of the coordinates are '-+'.
- III: The third quadrant is defined by {(x1,x2) | x1 < 0 and x2 < 0}. The signs of the coordinates are '--'.
- IV: The fourth quadrant is defined by {(x1,x2) | x1 > 0 and x2 < 0}. The signs of the coordinates are '+-'.
In higher dimensions, there isn't a convention about how to enumerate the orthants, which are generalized quadrants. So let's create our own labeling scheme that uses the signs of the coordinates to give each orthant a unique label. You can associate a positive sign ('+') with 1 and a negative sign ('-') with 0. This each string of signs maps to a number in base-2 (binary). You can convert the binary representation to an integer 0 through 2d–1 in a natural way.
For example, the 2-D quadrants are associated with the digits 0-3 via the strings '00', '01', '10', and '11'. Since we usually count starting from 1, it is common to add 1 to every octant to obtain the numbers 1-4. Notice that this produces a different set of labels than is taught in high school:
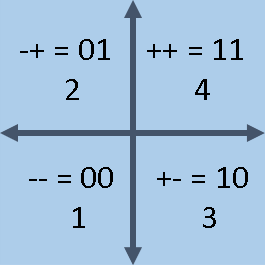
- The string '++' is mapped to '11'. In binary, this string equals 3. Add 1 to that value. Thus, the quadrant with the signs '++' is called Quadrant 4 by this new labeling method.
- The string '-+' is mapped to '01'. In binary, this string equals 1. Add 1 to that value. Thus, the quadrant with the signs '-+' is called Quadrant 2 by this labeling method.
- Similarly, the quadrant with signs '--' is called Quadrant 1, and the quadrant with signs '+-' is called Quadrant 3.
In a similar way, an orthant in 3-D space is called an octant. You can classify a 3-D point into an octant by looking at the signs of the three coordinates of a point. The octants are defined by the following eight triplets of signs: '+++', '++-', '+-+', '+--', '-++', '-+-', '--+', and '---'. The binary values are 7 down to 0 (in descending order), so the labels are 8 down to 1.
In general, the orthants in d-dimensional Euclidean space are defined by the set of unique strings on two symbols. The size of the set is 2d, and there is a natural one-to-one correspondence with the integers 0 through 2d–1 when written in base-2 (binary). Thus, we can label the orthants with the integers 1 to 2d.
Why do we care what orthant a point is in?
This current article is motivated by a recent project in which I reviewed a simulation algorithm that is supposed to create high-dimensional data that are spherically symmetric. In a correct simulation, each synthetic data point has an equal probability of appearing in any orthant. By displaying the distribution of the orthants, I was able to show the author that his algorithm was not correct.
To understand the relationship between spherical symmetry and orthants, let's briefly think about 2-D data. Suppose you are given a set of N two-dimensional observations. By subtracting the mean (or median) of each variable, you can center the data about the origin. Now, suppose you label each observation for the centered data according to its Euclidean quadrant. This tells you a few things about the distribution of the data:
- If approximately N/4 observations are in each quadrant, then the data are uncorrelated or weakly correlated.
- If most observations are in the quadrants I and III, the data are positively correlated.
- If most observations are in the quadrants II and IV, the data are negatively correlated.
Thus, the distribution of the orthants for centered data is a way to examine whether the data distribution is spherically symmetric or whether there are correlations in the data.
A first look at classifying points into orthants
Suppose you have a set of 2-D points. How can you identify the quadrant for each point? One way is to use the SIGN function in SAS, which returns the value -1 if a value is negative, +1 if the value is positive, and 0 if the value is 0. The SIGN function in the DATA step takes a scalar argument, but recall that you can call Base SAS functions from PROC IML and pass in vectors or matrices.
The following IML program defines a matrix, where each row is a point in 2-D. In this example, there is one point in each quadrant.
To find the quadrant, you can use the SIGN function to map the coordinates to a binary 0/1 matrix. Each row is now the
binary representation of a number 0-3. You can convert the row to a base-10 number and add 1 to obtain the quadrant number. Mathematically, the quadrant number for the i_th row is
\(q_i = 1 + \sum\nolimits_{j=0}^p b_{ij} 2^i\)
where the \(b_{ij}\) are the binary 0/1 values in the i_th row.
The program displays the quadrant for each point:
proc iml; z = { 7 8, /* I */ -6 8, /* II */ -2 -3, /* III */ 5 -6 }; /* IV */ d = ncol(z); s = (sign(z) + 1) / 2; /* sign(z) contains {-1,1}; map these values to {0,1} */ pow = 2##(d-1:0); /* powers of 2 for d <= 53 */ quadrant = 1 + (s#pow)[,+]; /* quadrant number for d <= 53 */ print z[c={'x1' 'x2'} r={I,II,III,IV} L='Convention'] quadrant[L='New Label']; |
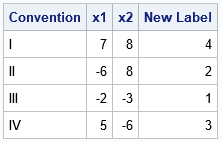
The output correctly classifies each 2-D point as being in the first, second, third, or fourth quadrant.
A function that classifies points into orthants
You can encapsulate these statements into a SAS IML function that computes the orthants for points in any dimension (Well, the dimension cannot exceed 53 because 2d must be representable as an integer, but this method is most useful for smaller values of d.) For completeness, the following function also handles the case where a coordinate of point is zero. In that case, the point is not in any quadrant, so the function returns a missing value.
/* z is an (n x d) matrix of points, where d <= 53. Find the orthant that contains the point. Ex: z = {-1 1}; q = CoordToOrthant(z); Answer is 3 because z is in the 3rd octant. */ start CoordToOrthant(z); s = sign(z); d = ncol(z); b = (s + 1) / 2; /* sign(z) contains {-1,1}; map these values to binary {0,1} */ w = 2##(d-1:0); /* powers of 2 */ orthant = 1 + (b#w)[,+]; /* convert binary representation to quadrant number */ /* handle the zero-probability case where sign(z)=0 */ idx = loc(s = 0); /* are any points are on a subspace where x[i]=0 for some i? */ if IsEmpty(idx) then return orthant; /* usual case; return quadrants */ rc = ndx2sub(dimension(z), idx); /* get rows and columns for the indices */ orthant[rc[,1], ] = .; /* set quadrant for those rows to missing */ return orthant; finish; z = { 5 6 4, 7 8 -9, 3 -2 7, 5 -6 -4, -2 8 9, -3 6 -4, -6 -5 8, -2 -3 -5, 6 0 3 }; /* x2=0 */ octant = CoordToOrthant(z); print z[c={'x1' 'x2' 'x3'}] octant; |
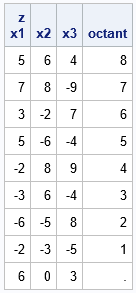
The output shows that the 3-D points are correctly classified into octants, including the point in the last row, which is not in any octant.
Application: The distribution of points into orthants
As mentioned earlier, this article is motivated by a project in which I had to assess whether a simulation algorithm was generating correct output. I knew that the correct output are spherically symmetric, meaning that there is an equal probability that the points would appear in any orthant. Rather than examine the distribution of the data, it was easier to examine the distribution of the orthants for the data.
For example, suppose you want to simulate uncorrelated random normal variates. The simulated data is spherically symmetric, so if you simulate B data points in d dimensions, approximately B/2d of them should be in each orthant. Let's run an experiment by generating 8,000 uncorrelated random variates in 3-D and plotting a bar chart of the orthants:
call randseed(123); d = 3; N = 2##d * 1000; /* generate N uncorrelated random normal variates in d dimensions */ mu = j(1, d, 0); Sigma = I(d); Z = randnormal(N, mu, Sigma); orthant = CoordToOrthant(Z); title "Distribution of Uncorrelated 3-D Points in Octants"; call bar(orthant) grid="y"; |
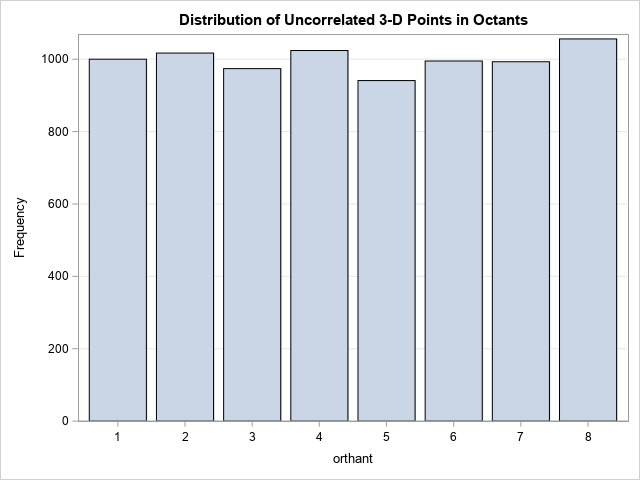
The bar chart indicates that of the 8,000 random points, there are approximately 1,000 points in each of the eight octants in 3-D.
The bar chart looks different if the points are correlated. In 2-D, a scatter plot of positively correlated data shows that most points are in the first and third quadrants. This geometry generalizes to higher dimensions. For example, the following IML statements define a 3 x 3 correlation matrix for which the (X1,X2) variables have a large positive correlation and the (X2,X3) variables have a large negative correlation.
/* contrast with the octants of strongly correlated data */ Sigma = { 1 0.7 -0.2, 0.7 1 -0.7, -0.2 -0.7 1 }; X = randnormal(N, mu, Sigma); orthant = CoordToOrthant(X); title "Distribution of Correlated 3-D Points in Octants"; call bar(orthant) grid="y"; |
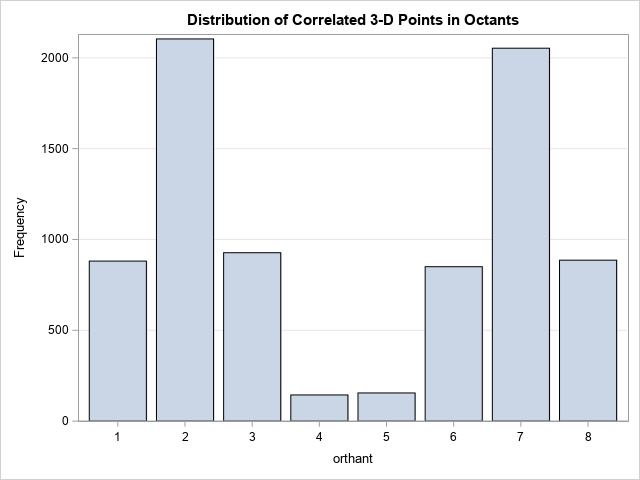
The bar chart indicates that the points are not distributed equally across the eight octants. There are many points in the 2nd and 7th octants, and relatively few in the 4th and 5th octants.
Summary
This article shows how to use the SIGN function in SAS to compute the orthant for a set of d-dimensional points. The function first uses the SIGN function to construct a vector of signs of the coordinates. This vector is naturally mapped to base-2 representation of a number, which is mapped to an integer in the range 1-2d. That integer is the orthant number. One application of this technique is to determine whether a high-dimensional sample of centered data is spherically symmetric.
