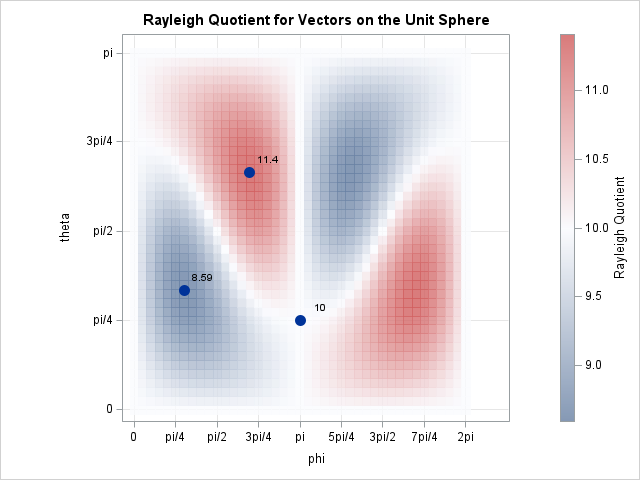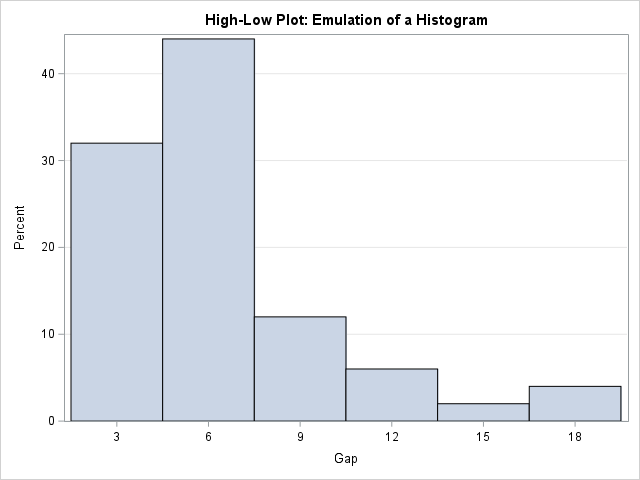
Use a high-low plot to emulate a histogram in SAS

SAS has several procedures that can fit a probability distribution to data, plot a histogram, and overlay one or more density estimates: PROC UNIVARIATE in Base SAS enables you to overlay parametric density curves from about 20 common continuous probability distributions, such as normal, lognormal, and gamma. It also enables