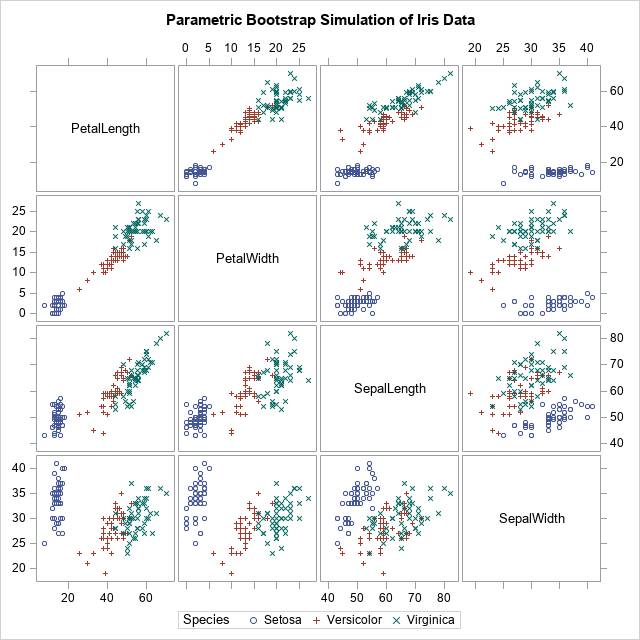
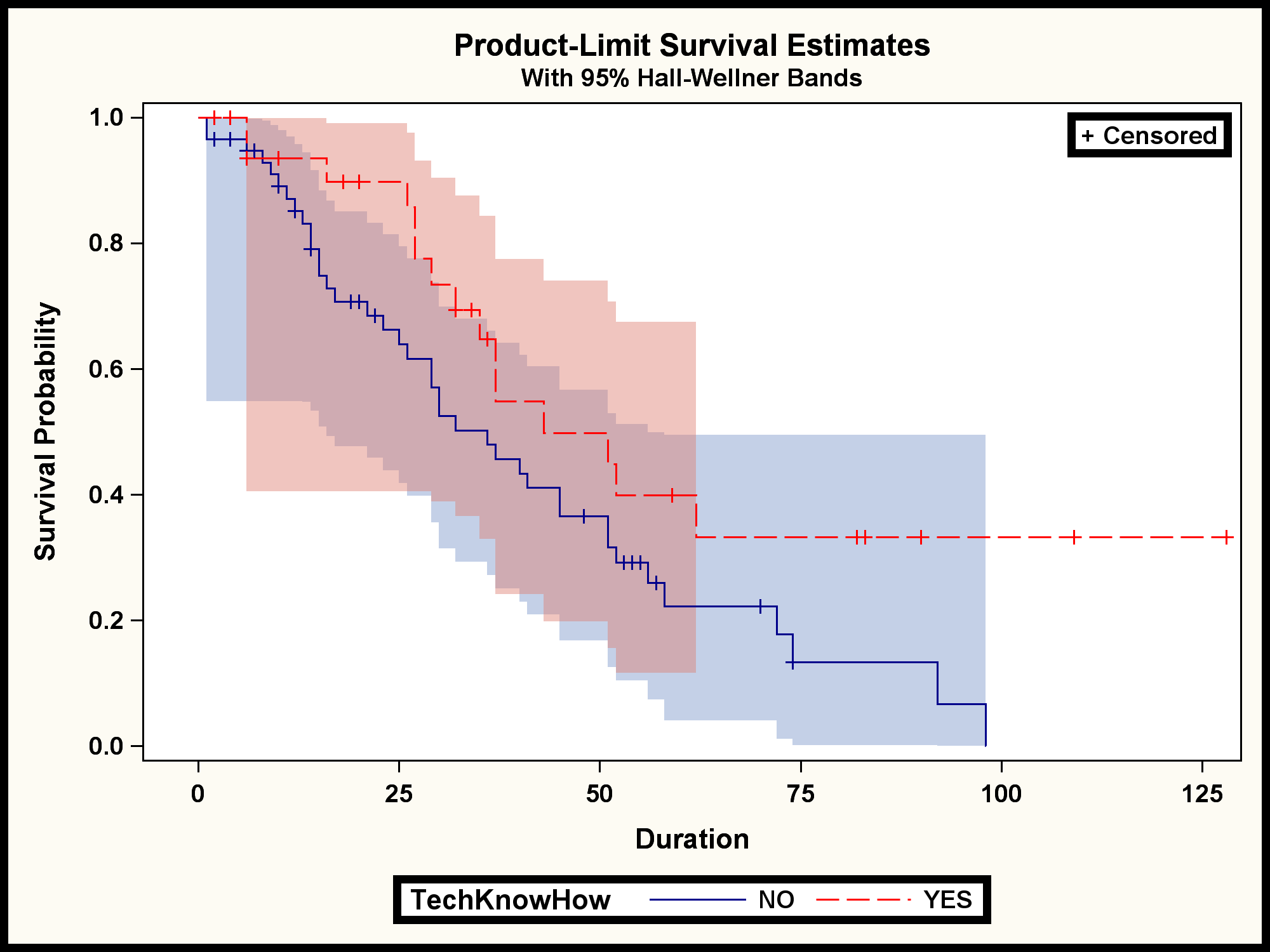
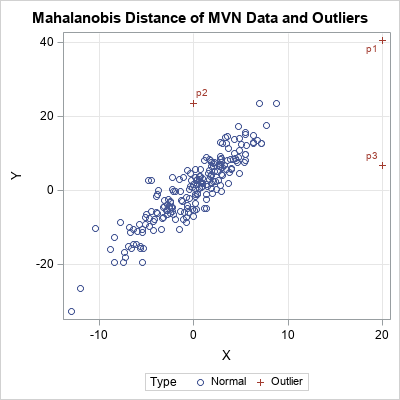
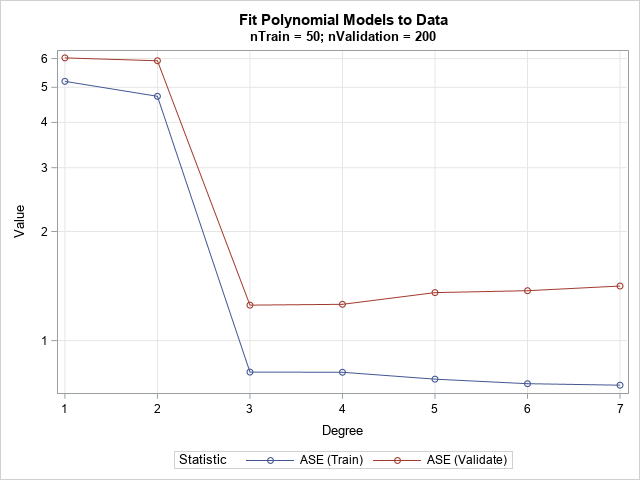
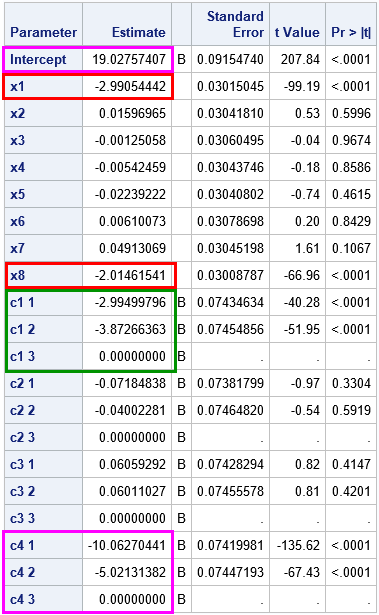
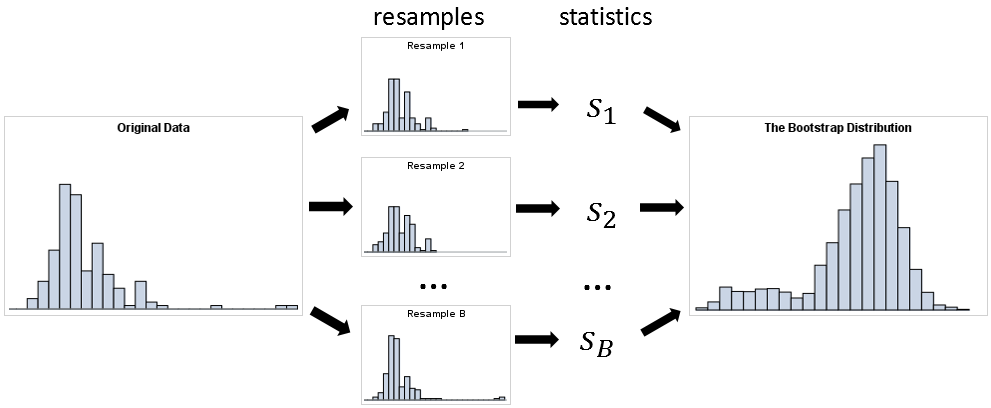
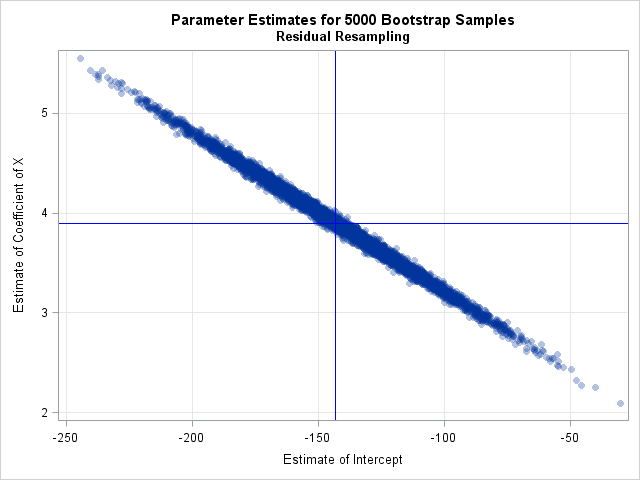
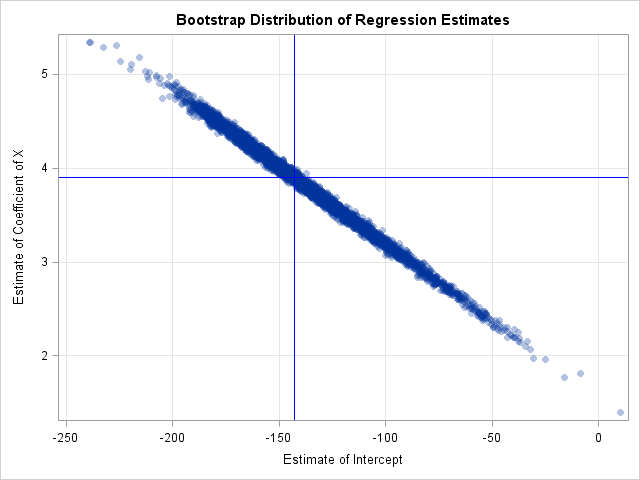
SAS Press Author Derek Morgan on Timetables and Model Trains

I was sitting in a model railroad club meeting when one of our more enthusiastic young members said, "Wouldn't it be cool if we could make a computer simulation, with trains going between stations and all. We could have cars and engines assigned to each train and timetables and…" So,