Deep learning (DL) is a subset of neural networks, which have been around since the 1960’s. Computing resources and the need for a lot of data during training were the crippling factor for neural networks. But with the growing availability of computing resources such as multi-core machines, graphics processing units (GPUs) accelerators and hardware specialized, DL is becoming much more practical for business problems.
Financial institutions use a large number of computations to evaluate portfolios, price securities, and financial derivatives. For example, every cell in a spreadsheet potentially implements a different formula. Time is also usually of the essence so having the fastest possible technology to perform financial calculations with acceptable accuracy is paramount.
In this blog, we talk to Henry Bequet, Director of High-Performance Computing and Machine Learning in the Finance Risk division of SAS, about how he uses DL as a technology to maximize performance.
Henry discusses how the performance of numerical applications can be greatly improved by using DL. Once a DL network is trained to compute analytics, using that DL network becomes drastically faster than more classic methodologies like Monte Carlo simulations.
We asked him to explain deep learning for numerical analysis (DL4NA) and the most common questions he gets asked.
Can you describe the deep learning methodology proposed in DL4NA?
Yes, it starts with writing your analytics in a transparent and scalable way. All content that is released as a solution by the SAS financial risk division uses the "many task computing" (MTC) paradigm. Simply put, when writing your analytics using the many task computing paradigm, you organize code in SAS programs that define task inputs and outputs. A job flow is a set of tasks that will run in parallel, and the job flow will also handle synchronization.
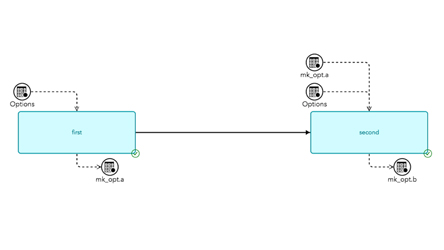
The job flow in Figure 1.1 visually gives you a hint that the two tasks can be executed in parallel. The addition of the task into the job flow is what defines the potential parallelism, not the task itself. The task designer or implementer doesn’t need to know that the task is being executed at the same time as other tasks. It is not uncommon to have hundreds of tasks in a job flow.
Using that information, the SAS platform, and the Infrastructure for Risk Management (IRM) is able to automatically infer the parallelization in your analytics. This allows your analytics to run on tens or hundreds of cores. (Most SAS customers run out of cores before they run out of tasks to run in parallel.) By running SAS code in parallel, on a single machine or on a grid, you gain orders of magnitude of performance improvements.
This methodology also has the benefit of expressing your analytics in the form of Y= f(x), which is precisely what you feed a deep neural network (DNN) to learn. That organization of your analytics allows you to train a DNN to reproduce the results of your analytics originally written in SAS. Once you have the trained DNN, you can use it to score tremendously faster than the original SAS code. You can also use your DNN to push your analytics to the edge. I believe that this is a powerful methodology that offers a wide spectrum of applicability. It is also a good example of deep learning helping data scientists build better and faster models.
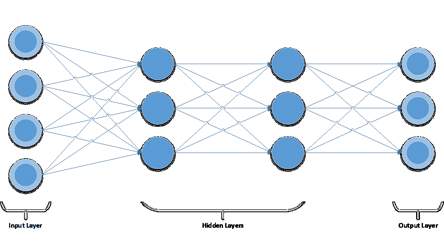
The number of neurons of the input layer is driven by the number of features. The number of neurons of the output layer is driven by the number of classes that we want to recognize, in this case, three. The number of neurons in the hidden layers as well as the number of hidden layers is up to us: those two parameters are model hyper-parameters.
How do I run my SAS program faster using deep learning?
In the financial risk division, I work with banks and insurance companies all over the world that are faced with increasing regulatory requirements like CCAR and IFRS17. Those problems are particularly challenging because they involve big data and big compute.
The good news is that new hardware architectures are emerging with the rise of hybrid computing. Computers are increasing built as a combination of traditional CPUs and innovative devices like GPUs, TPUs, FPGAs, ASICs. Those hybrid machines can run significantly faster than legacy computers.
The bad news is that hybrid computers are hard to program and each of them is specific: you write code for GPU, it won’t run on an FPGA, it won’t even run on different generations of the same device. Consequently, software developers and software vendors are reluctant to jump into the fray and data scientist and statisticians are left out of the performance gains. So there is a gap, a big gap in fact.
To fill that gap is the raison d’être of my new book, Deep Learning for Numerical Applications with SAS. Check it out and visit the SAS Risk Management Community to share your thoughts and concerns on this cross-industry topic.
