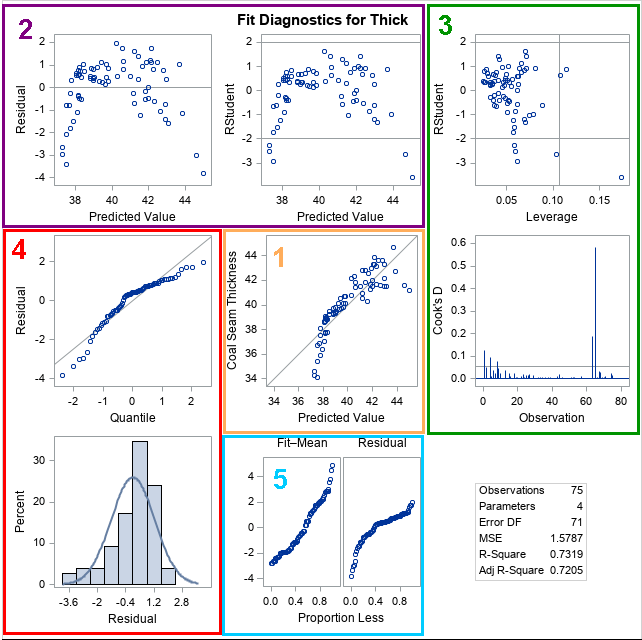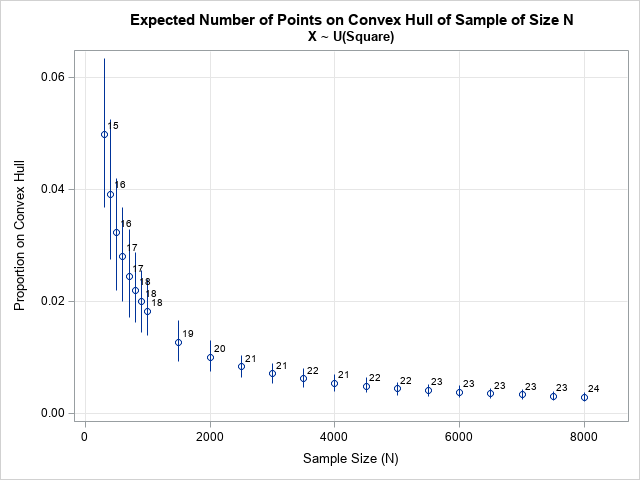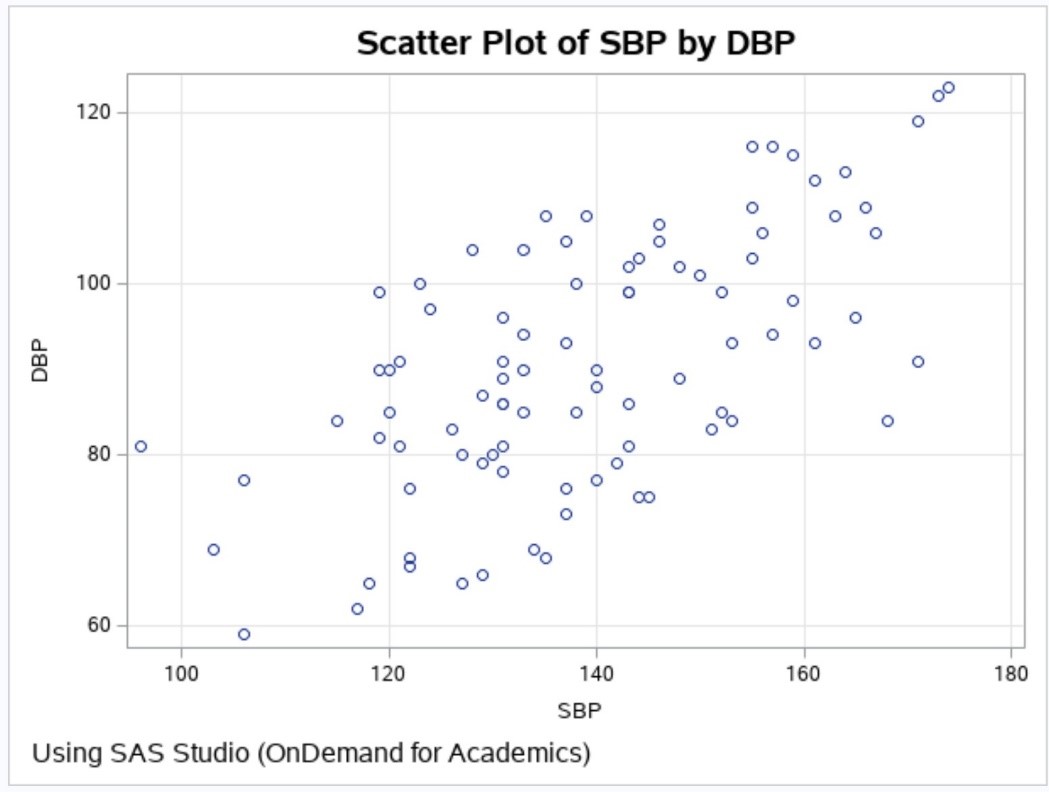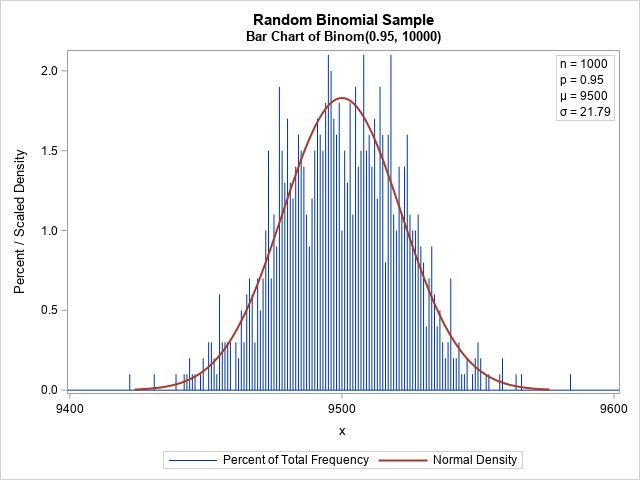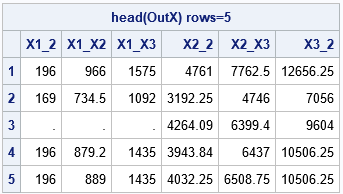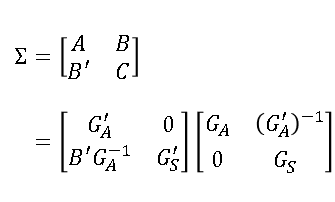
A block-Cholesky method to simulate multivariate normal data

You can use the Cholesky decomposition of a covariance matrix to simulate data from a correlated multivariate normal distribution. This method is encapsulated in the RANDNORMAL function in SAS/IML software, but you can also perform the computations manually by calling the ROOT function to get the Cholesky root and then