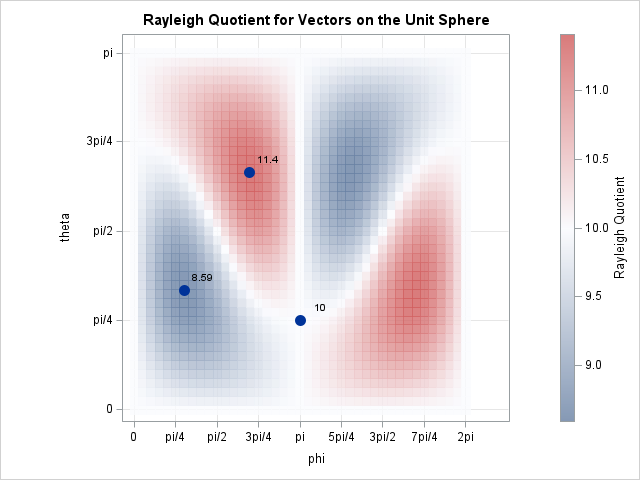
Visualize Rayleigh quotients and eigenvectors

When I encounter a new function, I usually graph it to gain intuition about how the function transforms its inputs. Recently, I needed to use the Rayleigh quotient function, which is connected to the estimation of eigenvalues and eigenvectors for symmetric matrices. It has been several years since I last



