
My SAS history: industry and academia
I have been using SAS since 2002: first in the telecommunications industry, later as a researcher at universities and then finally as a consultant at SAS headquarters. I used SAS in telecommunications for over ten years, in academia for over another decade and as a consultant for two years before officially joining SAS in December of 2015. Now, you might be asking yourself... 2002 was 20 years ago, but your SAS history adds up to over 28 years. Where did these extra years come from? Well, some of my academic experience was in parallel with working in the industry. The four years of my Ph.D. program at UFRJ, two years of postdoc at IMPA and two years of postdoc at DCU overlapped with my work in the industry. I wore two hats, one in the industry and one in academia. In the industry, I would use more graphical interfaces like Enterprise Miner because it was faster to develop multiple models, safer to maintain and evolve and easier to collaborate with other folks. In academia, I would code much more. The work was more solitary, I had the flexibility to change whatever I want, whenever I want and narrow down my research and development as needed.
From Enterprise Miner...
I have to confess. I loved Enterprise Miner. It could train multiple models by using a graphical structure which allowed me to define different approaches and methods. For example, I could try a decision tree with original inputs, with transformed ones and based on features extracted from the raw data (we didn’t call the process to create new variables as feature extraction). I could try multiple neural network topologies, varying for instance learning rates, some hidden neurons or trying out distinct activation functions. I could create and evaluate all these different analytical approaches in a single place, in a single workflow.
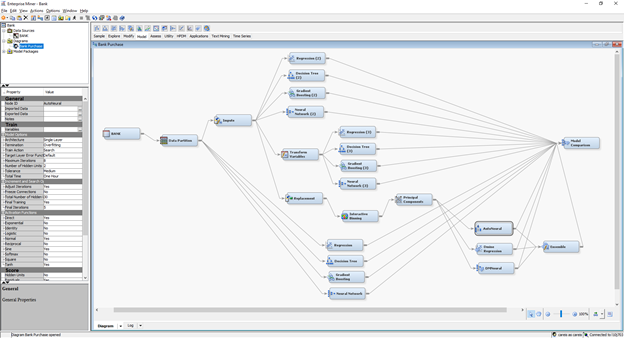
In the industry, I knew that I should try to generalize the models as much as possible because the data changes over time and all models will decay eventually. In academia, I was more concerned about accuracy and the type of training was much more specific. The graphical interface in Enterprise Miner and the possibility to create a workflow or multiple workflows was only a dream. It wasn't realized and wouldn't be... Until SAS Viya, particularly Model Studio, came into play.
...to Model Studio
Even though it was very practical to define and train multiple approaches in Enterprise Miner, at some point the assessment got a bit confusing. If I decided on a single workflow, I would have models everywhere with all the multiple methods sitting in the same place. I could still assess the models’ performance, but all approaches would be together in the evaluation. Of course, I could create one workflow for each analytical approach, but then I wouldn’t be able to assess all models for all different approaches together in a single view.
When I first started using Model Studio in SAS Viya, I immediately realized that this particular problem was solved.
For example, I can create multiple pipelines (analogous to workflows in Enterprise Miner), one for each analytical approach, but now I can assess and evaluate all different approaches one by one and also all together. I can concentrate on my training, approach by approach, and try to improve models upon this particular approach along the process. I can then move on to different approaches and do the same.
I can create a very traditional statistical approach based on different regressions and decision trees. I may try imputation and transformation before training the models or not. I can focus on my different attempts in a single pipeline and then assess the final results.
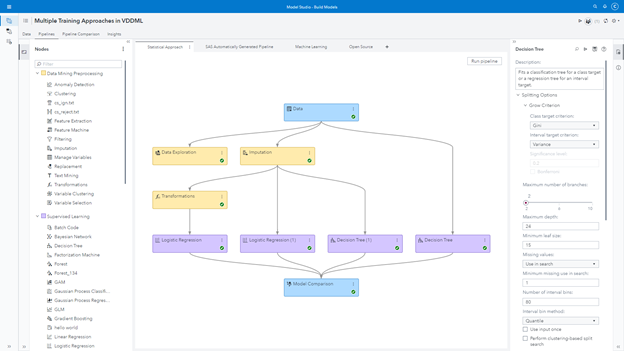
One of the challenges in training supervised models is figuring out the best sequence of steps before actually starting the training. Should I impute or transform variables? Which ones? Should I replace values on the existing input data? Should I extract new machine learning features like autoencoders? One embedded AI feature in Model Studio help us in this task. We can automatically generate a pipeline. An optimization process runs behind the scenes to try out multiple sequences and steps as well as not just attempting different models but also autotuning them. The final pipeline is presented to us and we can use it as guidance. Naturally, we can tune models and modify steps as we want. As an optimization process, we can set a time limit to search all these different parameters. The longer we allow it to run, the more likely the pipeline will be better.
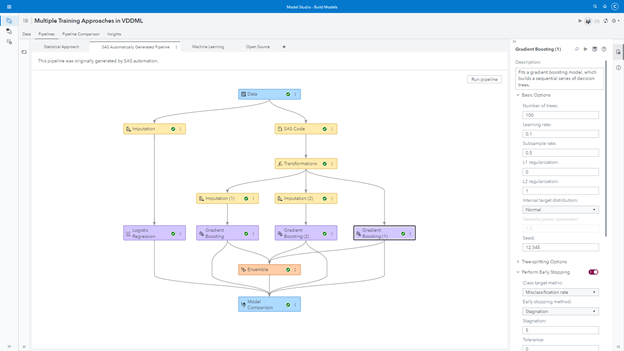
The best approach tournament
SAS Viya is a distributed engine running multiple tasks in parallel. While my automated pipeline runs, I can focus on my machine learning approach. I can select models like neural networks, gradient boosting, forest and support vector machines. I can also evaluate if an ensemble model works better in generalizing the final prediction with different (validation) data. Something extremely helpful is the autotune feature within each one of these models. Personally, I used to spend a lot of time trying out different parameters, like learning rates, hidden layers, hidden neurons, regularizations, etc. With the autotuning feature, we can define the range of the input space when the optimization algorithm searches for all those hyperparameters. Pretty cool, right? Again, it doesn’t need to be our final model. We can use this feature as a guide so we can eventually fine-tune the champion model in this "tournament," or the tournament associated with my machine learning approach. Well, if we have an autotuning feature that searches for the best hyperparameters for a machine learning model, why not have a feature that searches for the best-autotuned model across different algorithms? Good news: we do have that feature. I can select the Model Composer and choose which models to try out in an autotune approach. This node will select the best model on this, let’s say, "small tournament."
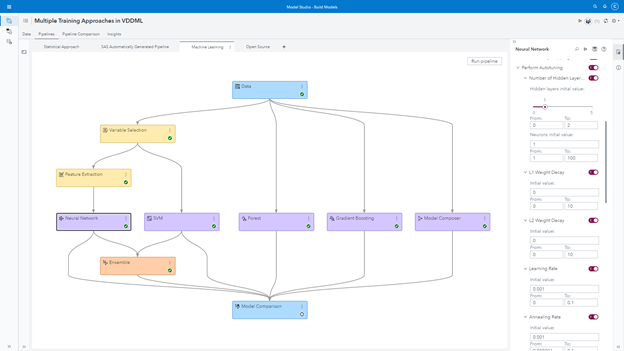
Of course, all these tasks may take a while, but that's no problem. I will move on to a different approach, the open source approach. To be honest, I am not good at open source. After all these years of using SAS, I am very biased. Fortunately, I have some brilliant young minds working with me and I often ask for them to help me out with the open source models. Once the models are done, I simply add them into a new pipeline, and voilà! My new approach is ready to be evaluated and, better yet, compared to all other different approaches I have created.
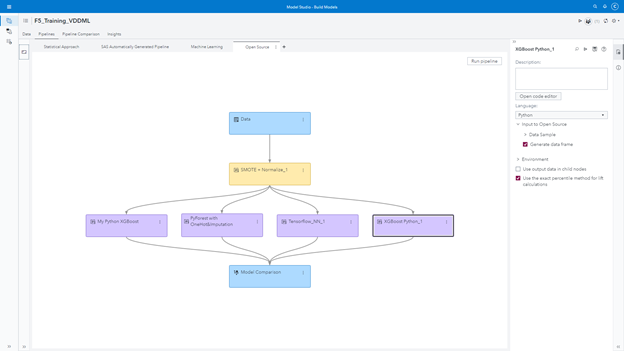
For each approach, the statistical one, the automated, the machine learning and the open source, I have my own, let’s say, "regional tournament." I can see the performance for all models, looking through multiple fit statistics, evaluating lift curves, etc. The best model according to my preferred fit statistics will be automatically selected for me.
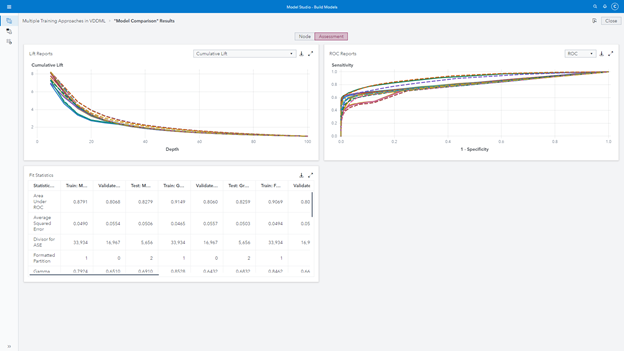
Then, I can compare all the champion models, the champion from each one of the pipelines I have created. This has become my "tournament of tournaments" or the "national league," if you will.
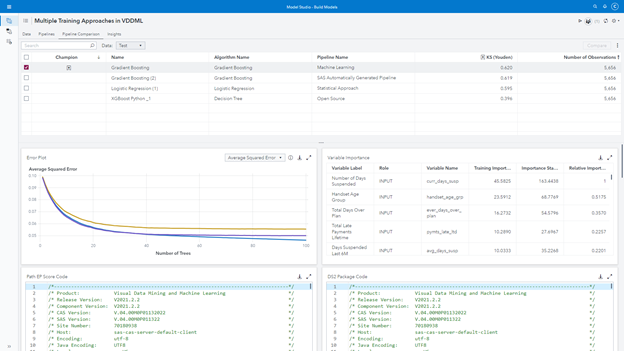
This way of working allows me to organize my multiple analytical approaches into different pipelines. Even better, it allows me to collaborate more effectively with my peers. As I said, I am not an open source person. So, while I work on my machine learning approach, I can ask some of those brilliant young minds I mentioned before to work on the open source approach in parallel.
But wait, there's more!
This approach helps me with challenging initiatives like maintenance, evolution, orchestration, governance, etc. You couldn’t possibly ask for more, right? Well, hold on! Let me tell you about two bonus features before I you go. These are features that I dreamed about for a long time.
Model interpretability
The first bonus feature is model interpretability. I love neural networks, I really do, but when working with business departments, I am always asked to interpret and describe the model or at least its predictions. That’s totally fair, I know my peers on the business side do not use just my models’ scores or probabilities. They use the models’ explanations to create campaigns, speeches, packages, bundles and select the leads. How do I interpret a neural network or an ensemble of trees like gradient boosting or forest? I just can’t. Well, I used to run another model like regression or decision tree based on the neural network’s prediction to explain the results. But now, we can use the model interpretability feature to better understand the models’ outcomes, like variable importance, partial dependency, individual conditional expectation, local interpretable model-agnostic explanation, and Shapley.
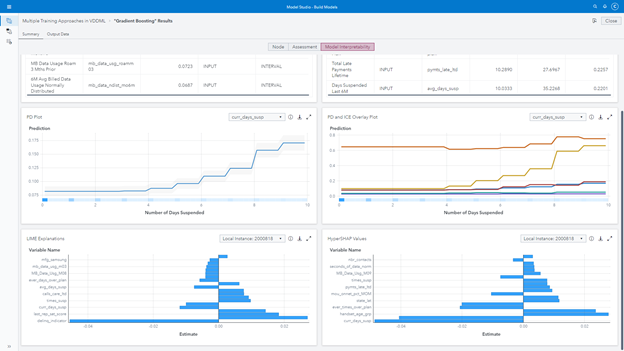
Insights
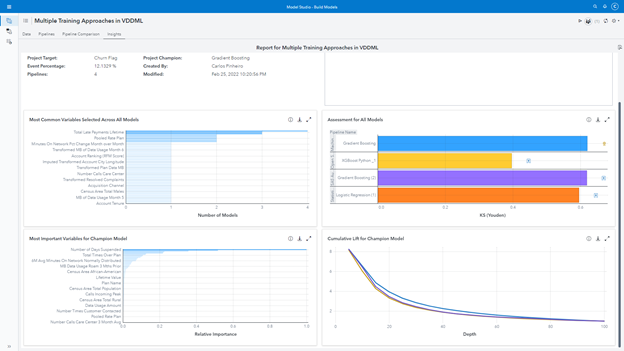
The second bonus is the Insights feature. Once you run all approaches (pipelines tournaments) and compare them all together (tournament of the tournaments), we can execute the Insights and get valuable information about the champion models, like the most common variables used across all of them, the assessment of the champion models, the variable importance list considering all models and the cumulative lift for the champions. It seems trivial, but it is actually very useful when we work in parallel with other folks on the same project. We have an open input text box to add notes! Hah! Cutting-edge technology helps us to organize the work and keep everyone informed about the decisions of the project along the way.
Conclusion
If you've made it this far in the article, I would like to thank you! I really hope you enjoyed reading this and that it's useful to you. If you are an Enterprise Miner user, do not miss the opportunity to try out Model Studio in Viya. I am sure you will love it!
Want to learn more? Try the latest SAS® Viya® capabilities now, for free!

2 Comments
I haven't used Enterprise Miner or Model Studio before, but these tools look interesting. I have, however, been working with data analytics for almost a decade, so I appreciate you bringing these applications to my attention. I will need to do more research on Model Studio in particular.
Hi Bret, I'm glad you found interesting. Do not hesitate to reach out to me if you have any questions while you research on Model Studio.