The SAS machine learning toolkit, accessed through SAS Model Studio, now offers more flexibility between SAS and open source models. SAS Model Studio, included with SAS Viya, is the integrated visual environment that supports model development for SAS Visual Data Mining and Machine Learning, SAS Visual Forecasting, and SAS Visual Text Analytics. SAS Model Studio also supports workflows for open source models and custom SAS code.
Pipelines in action
Within SAS Model Studio, processes are built using pipelines. (For more about visual machine learning and pipelines, see this article from my colleague Crista Cody.) Pipelines can consist of data preprocessing, model generation and comparison processes.
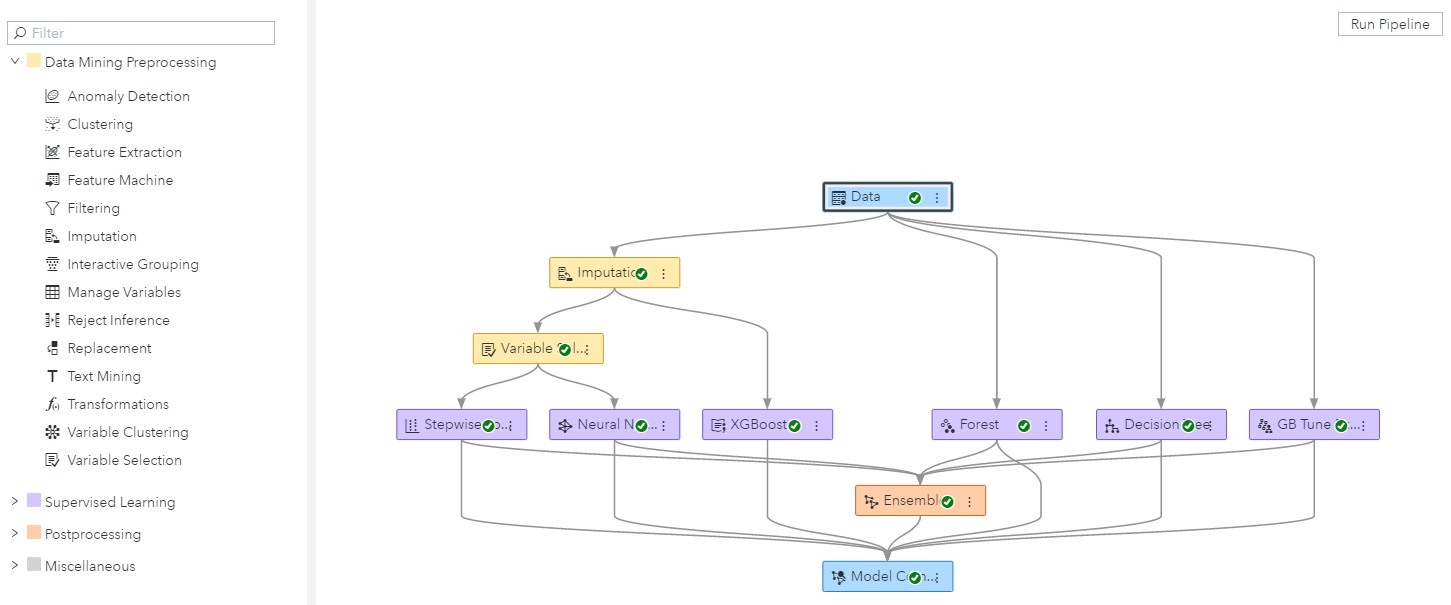
Each pipeline can have a 'pipeline champion' after the models are compared. A 'project champion' is selected from pipeline champions to represent the best model for the entire project. Pipelines and individual processes can be saved and later replicated by other users for a better collaborative experience. Although there are already prebuilt processes that SAS provides by default, you can customize your processes using either open source or custom SAS code and add them to the list. With SAS Viya 3.5, these custom processes can interact with each other.
As simple as it sounds, this feature enables you to create pipelines with different programming languages. Because SAS technology runs much faster in its native engine, you can run heavy duty processes efficiently in CAS (Cloud Analytic Services) and then connect the output to your favorite open source packages. Debugging is easier too, since SAS Model Studio can pinpoint the specific process related to any error.
An example: A SAS model, SAS program, and Python code walk into a bar...
Let's see these integrated pipelines in action.
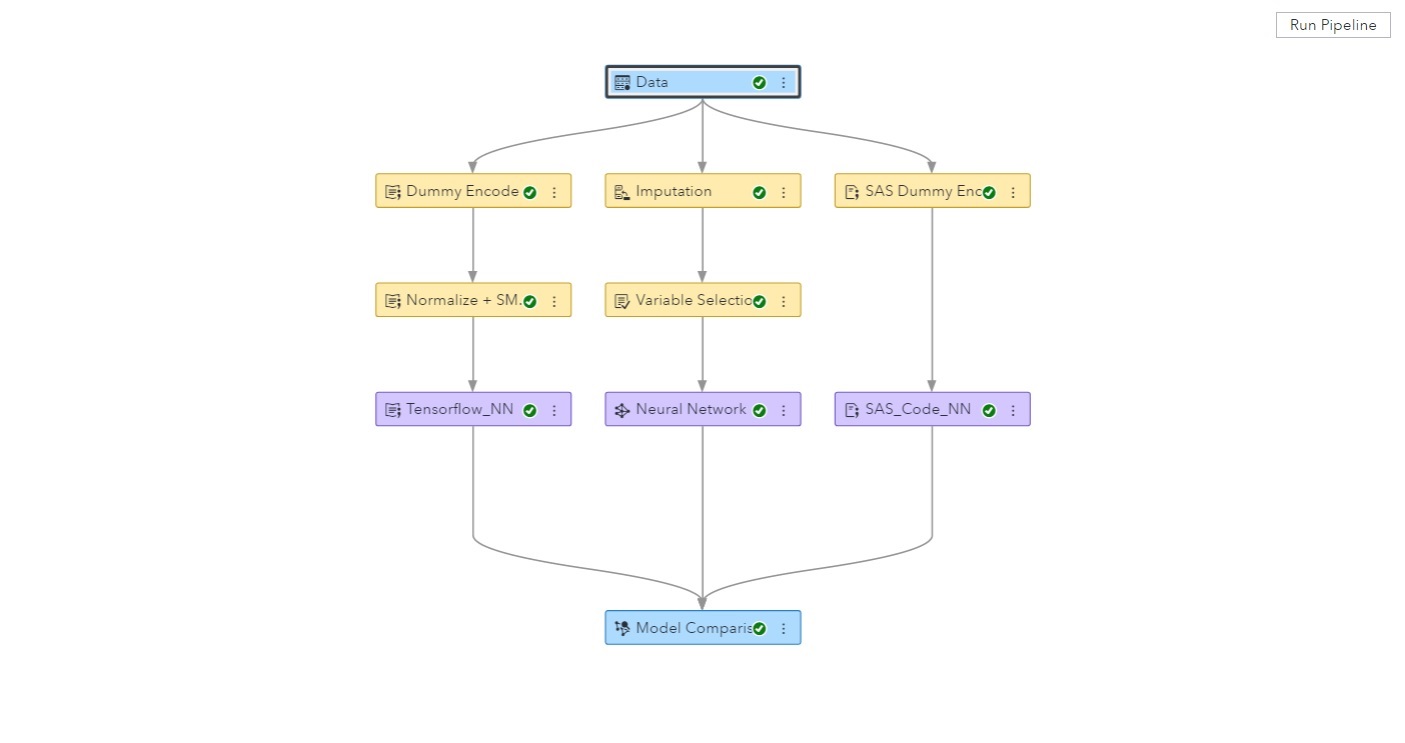
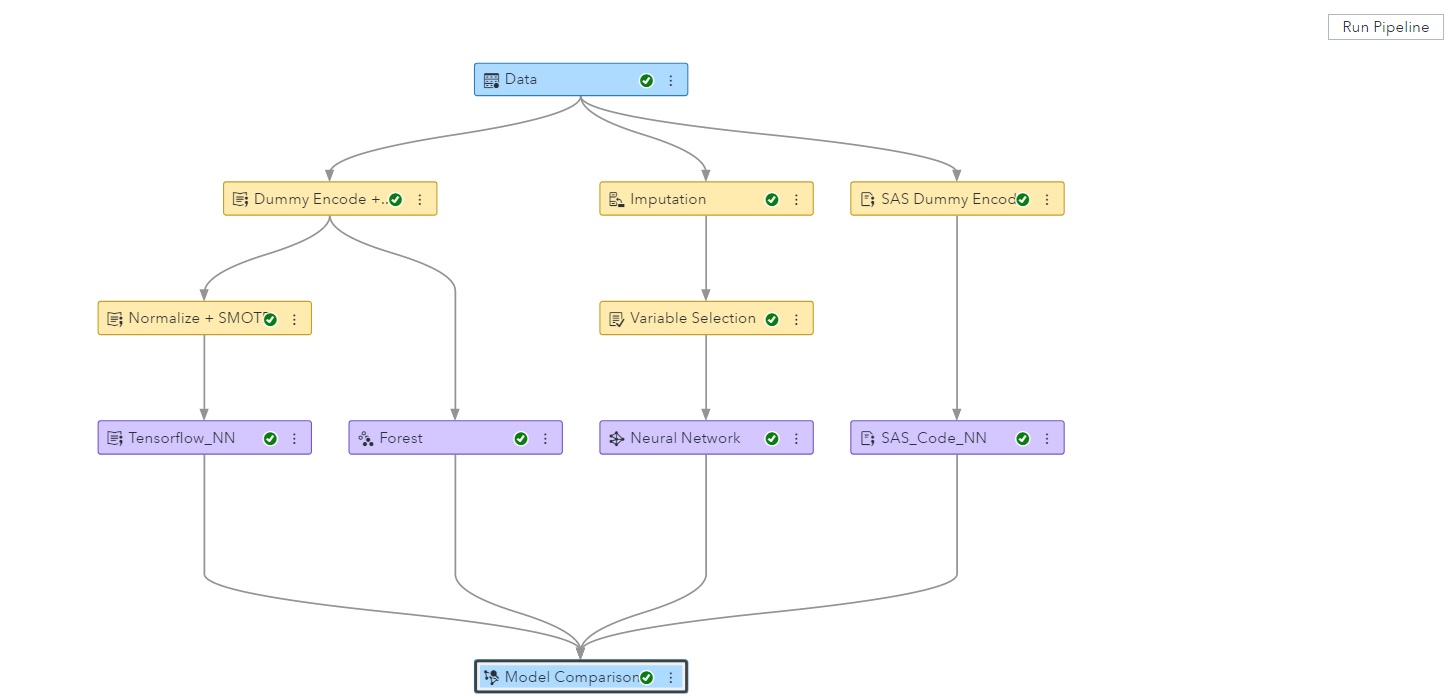
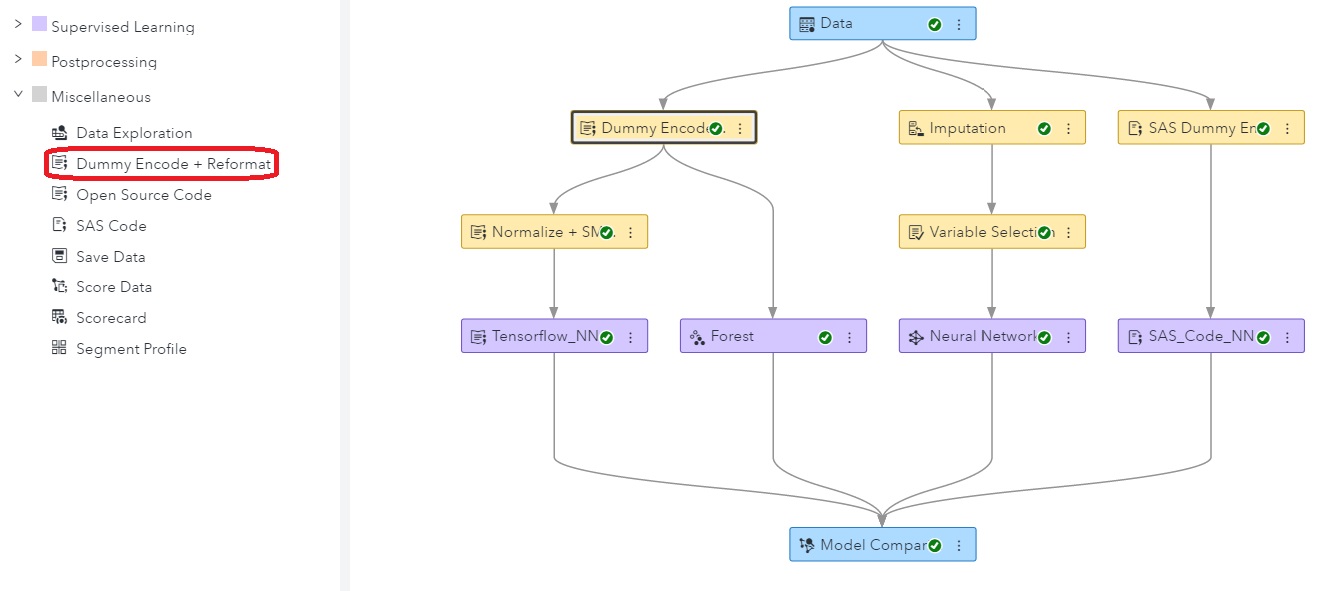
The pipeline above shows three separate branches. The left branch uses Python processes; the right branch is all SAS custom code; and the middle branch consists of prebuilt Model Studio processes. Because the interactions are based only on data outputs, languages can be intermingled. For example, the node called 'Dummy Encode + reformat' could be defined in R; 'SMOTE + Normalization' could be defined in SAS; and Tensorflow could run using Python. Team members can work on the same pipeline and share each other's work -- programming language and preferred packages are not a barrier.
Models can be compared simply by opening a comparison node. In this example, it looks like the Python preprocessing step worked well with the SAS prebuilt Forest model and its autotuned hyperparameters.
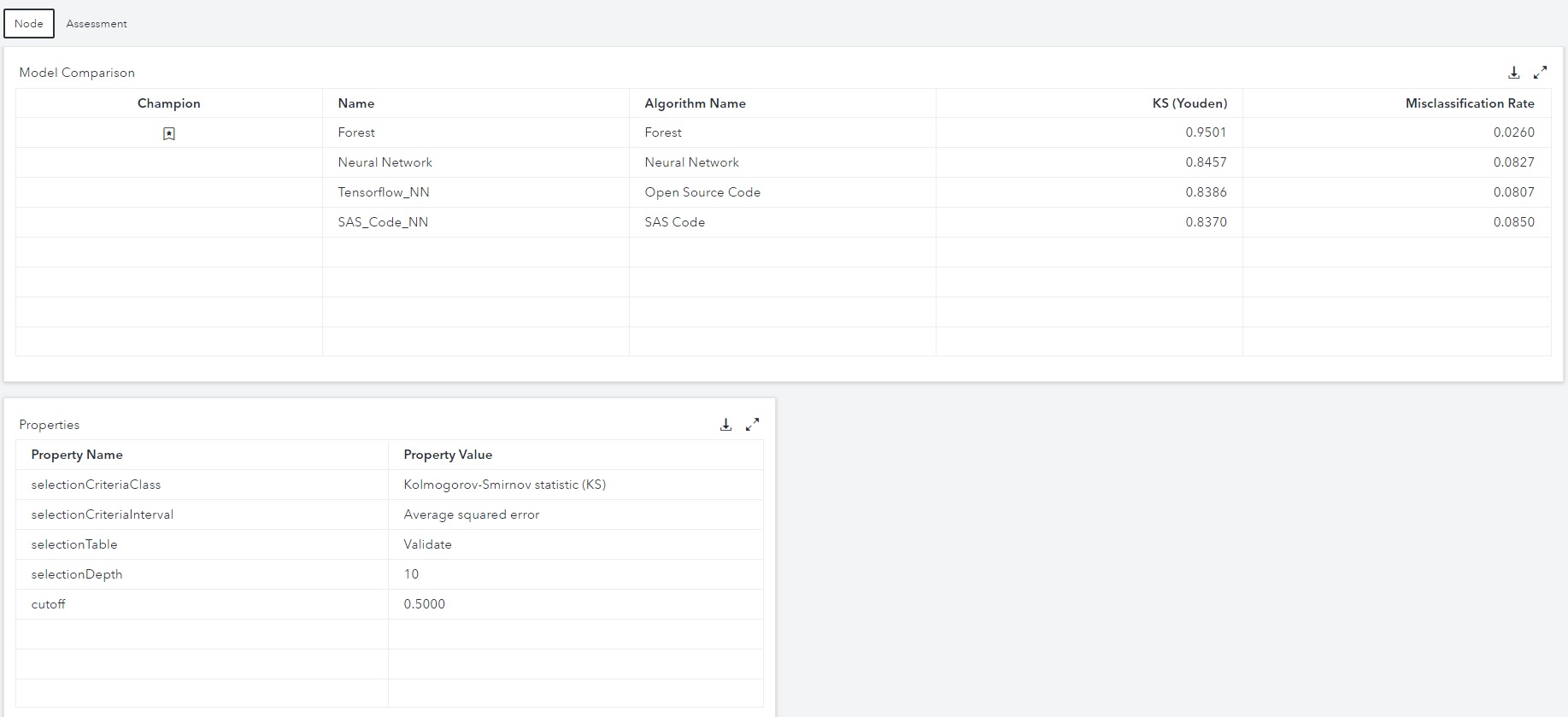
Speaking of model comparison, in this tutorial my colleague Jeff Thompson explains the theory and practice for comparing analytical models, with examples in SAS Model Studio.
Saving your pipelines for reuse
Once we have a collection of pipelines that we like, we can save them to a repository so other users could replicate them or use them as a starting point for another project.
Although there are many machine learning toolkits in the tech industry, SAS Model Studio incorporates the established and optimized SAS techniques that customers love, along with the best of open source techniques. Multiple users are free to work on the same model and share their processes without language restrictions, providing a collaborative approach for model developers.







2 Comments
Very good post. Cleared a lot of concepts, thank you!
Pingback: The analytical platform modernization - The SAS Data Science Blog