Are you a seasoned data scientist looking for a fast, all-inclusive machine learning solution? Curious about machine learning but have little to no programming experience? Interested in using AI to take over the world? Follow my lead and use SAS VDDML to fast track your world domination.
This blog is the beginning of a series on SAS Visual Data Mining and Machine Learning (VDMML) told from my perspective as a first-time SAS Viya user, Graduate Intern at SAS, and ABD PhD Candidate in Computer Science. I'm writing this series for two main reasons: 1) to express how surprised I am at seeing how easily complex tasks can be completed after doing it the hard way for years and 2) to provide examples to convince you, too.
SAS VDMML is only one of many products available in SAS Viya®. Its distinguishing feature being the machine learning pipelines which are created in a single, integrated in-memory environment via a drag and drop interface.
In this post, I will provide a high-level overview of a few of the features available in SAS VDMML. In the next posts, I will provide detailed examples and code comparisons for individual features, such as pipeline creation and autotuning.
Tip: At the bottom of the post, I talk about a course on machine learning using SAS Viya that provides access to the software and teaches machine learning basics.
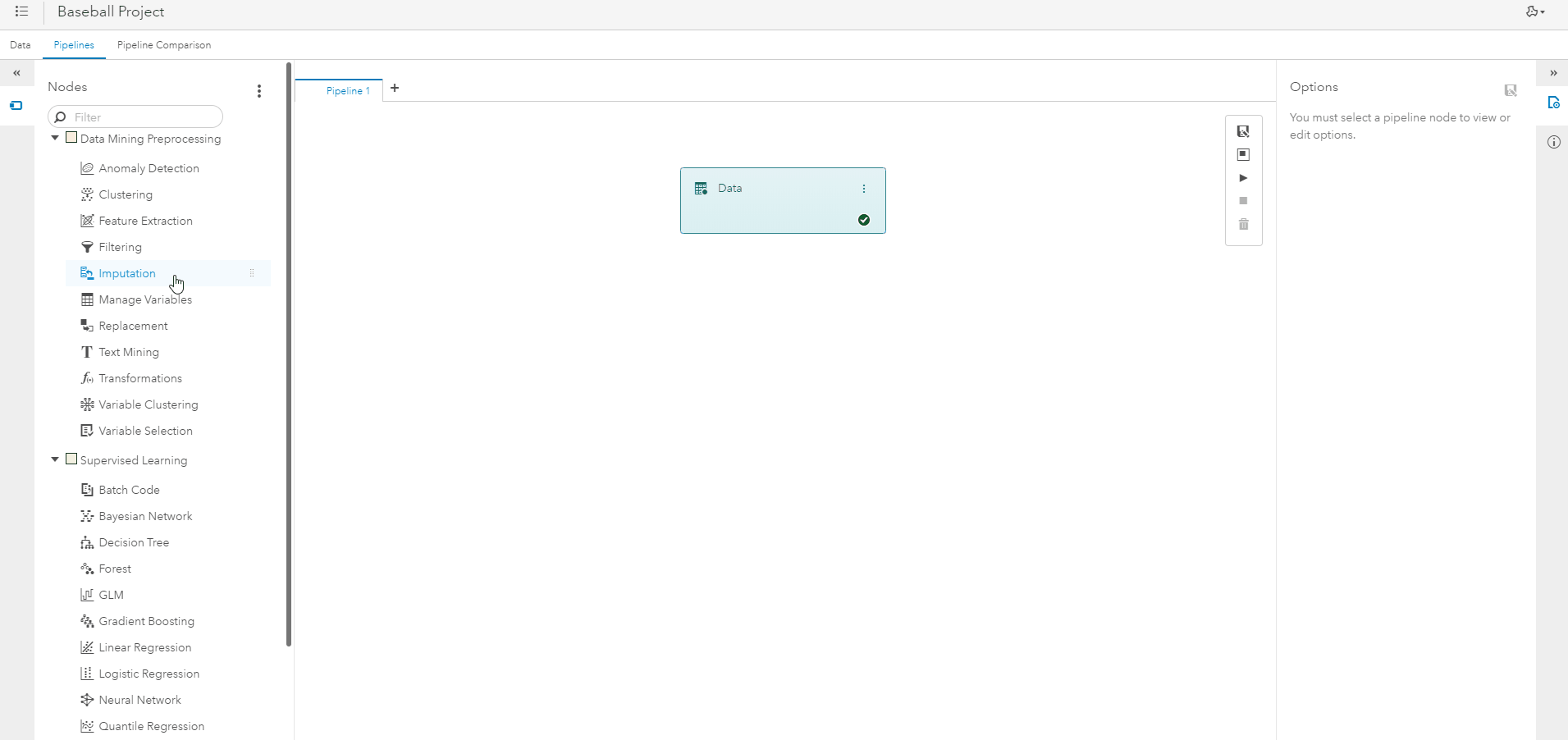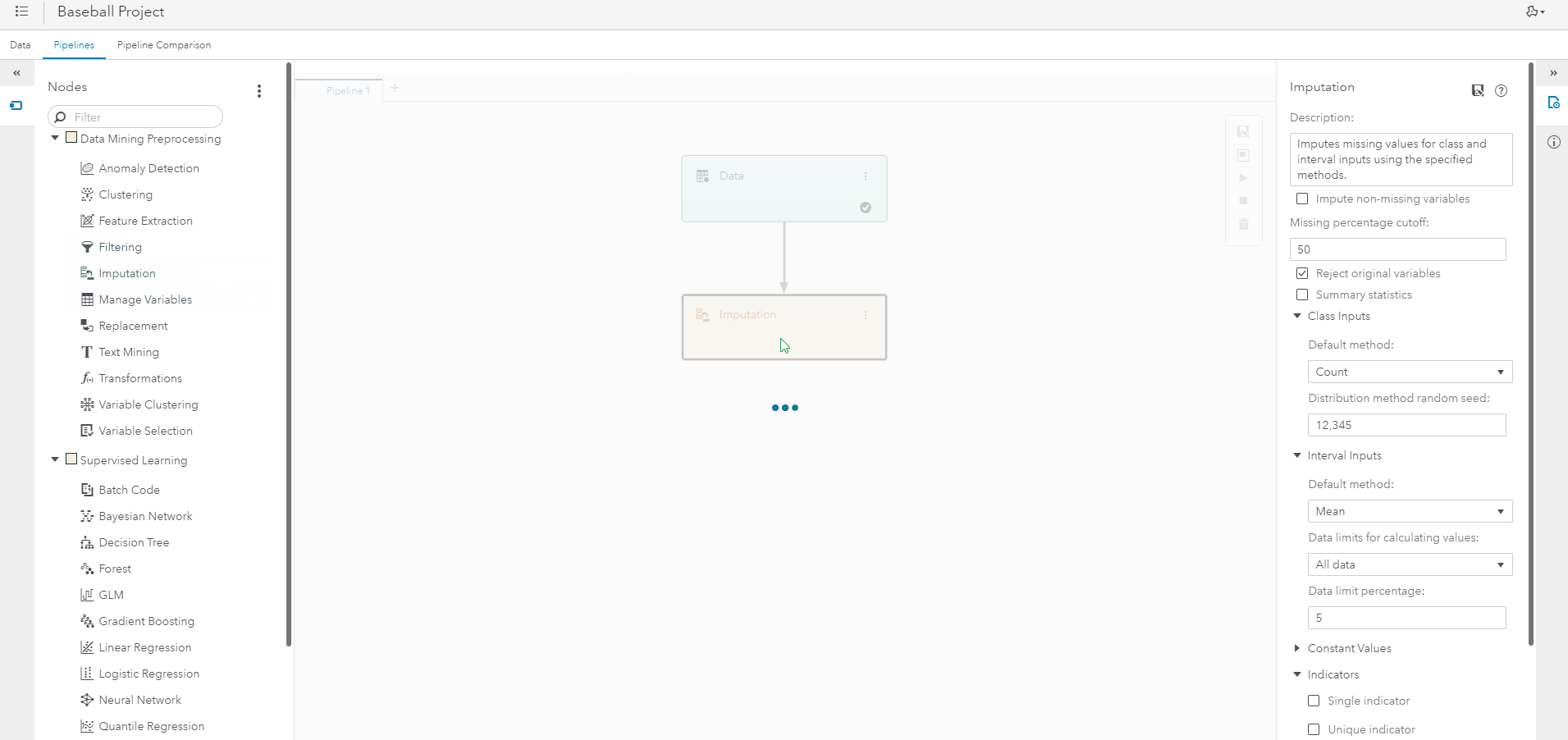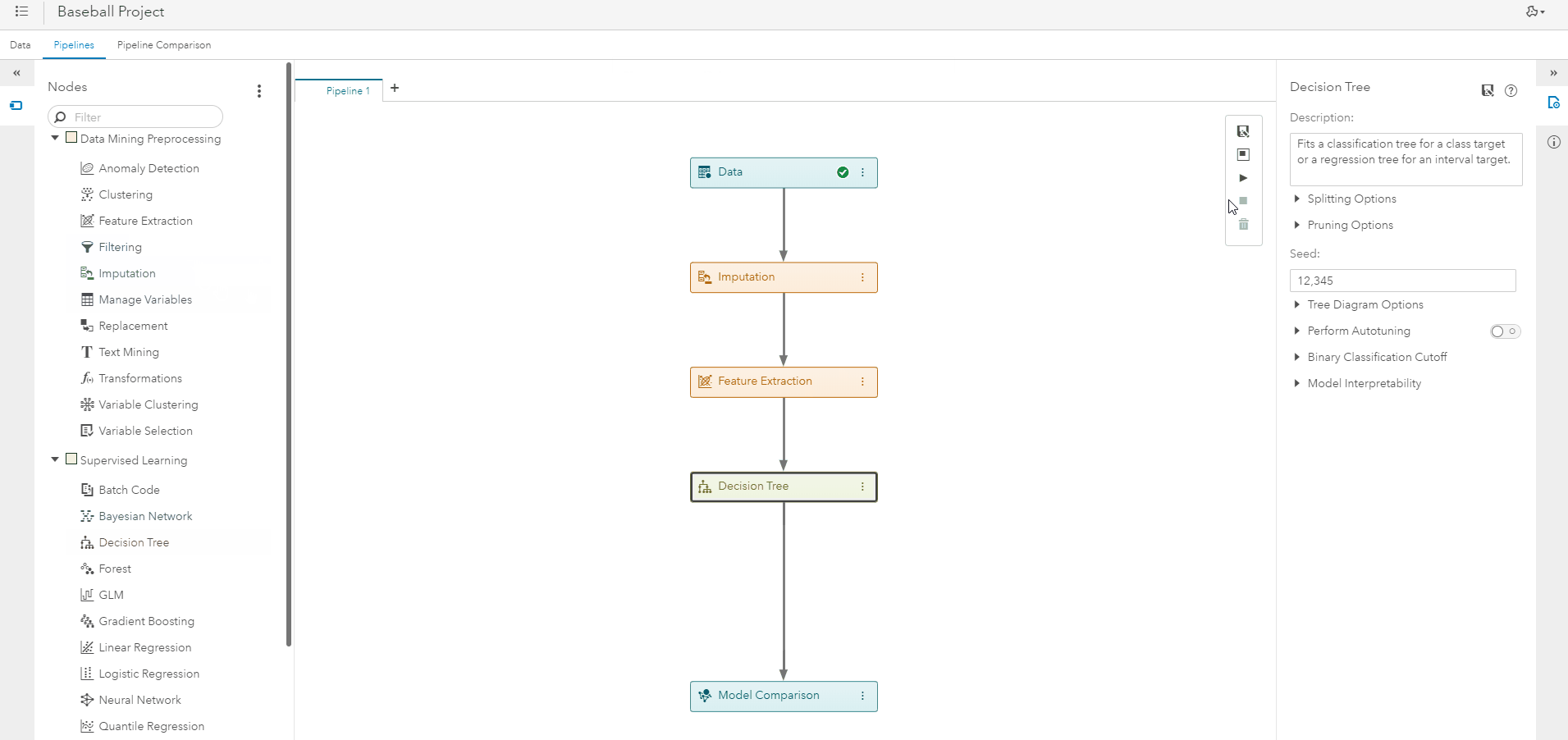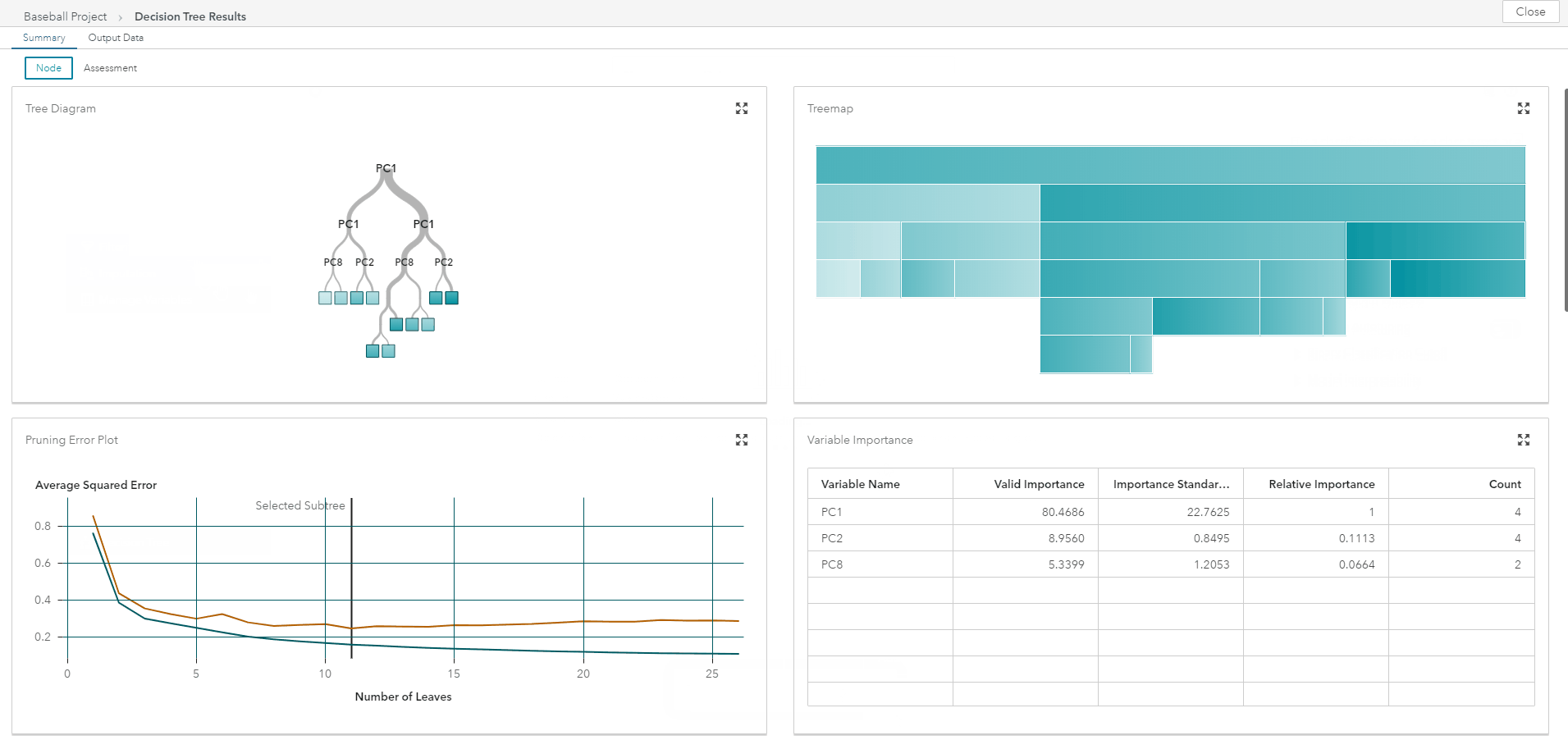
If you've never used SAS VDMML, here are the top 3 reasons why I think you should check it out.
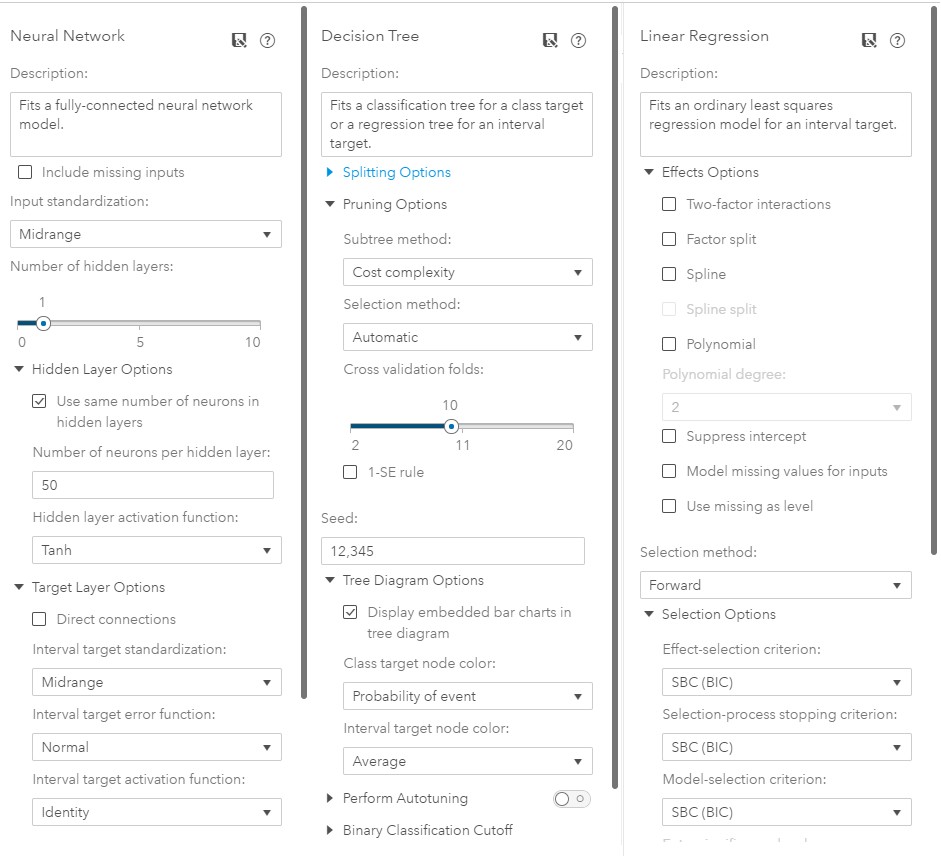
SAS VDMML creates a simplified approach to machine learning solutions beneficial to people with a wide range of expertise.
Have you been programming for as long as you can remember and are well-versed in the machine learning world?
Why spend all your precious mental energy focusing on tedious programming tasks? Instead, you could be focusing your energy on diving deeper in your data and discovering the extent of its modelling capabilities.
After spending only a week familiarizing myself with the interface, I felt confident I could perform my normal tasks with ease and with better hyperparameter tuning and more comprehensive model evaluations.
If you are wondering if these simplifications limit the customization of models, think again. For most uses, the customization options available match the level programming provides by utilizing features such as drop-down menus and editable text boxes - eliminating unnecessary mental overhead.
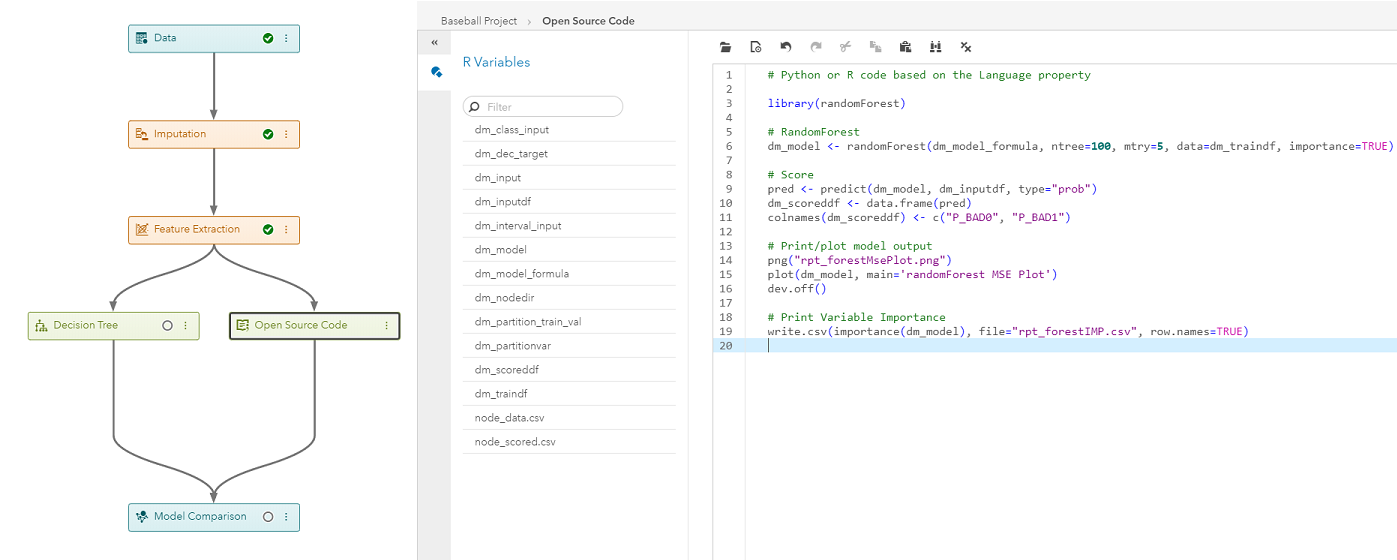
Still itching to program?
You have options: the SAS Code node and the Open Source Code node (available for use with R and Python). Both nodes can be used in any part of the pipeline, including preprocessing, supervised learning, and post-processing.
For example, you may have preprocessing code for extra messy data already written in R. All you need to do is add the Open Source Code node, insert your code, and update the variables to match the provided macros. Or, maybe you want to try the Deep Learning toolkit and CAS action? Drop a SAS Code node into your pipeline, add your code, and you are good to go!
Little to no programming experience or not quite a machine learning expert?
The drag and drop interface, wide selection of templates, and the extensive evaluations allow for almost anyone to produce professional-level results in a matter of minutes. While using SAS VDMML might not require expert-level knowledge on machine learning, important projects should have an expert review the approach and results.

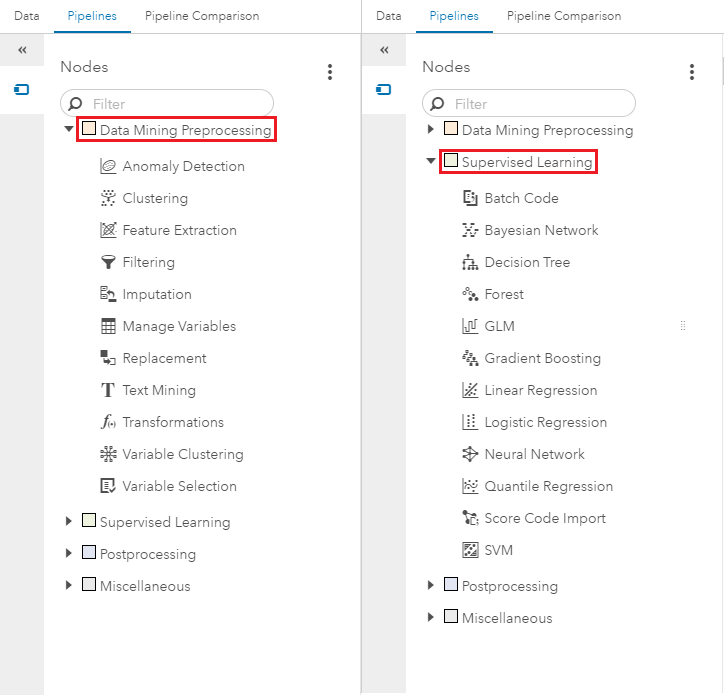
The days of spending weeks programming scripts for feature extraction, fine-tuning models, and evaluating your model are over!
For example, let's say I'm attempting to impute some variables using R. First, I might store the names of each columns separately based on the type of imputation I want to perform on it. Then, I could create the code for each type of imputation. If I'm only attempting 2 different types of imputation, I will most likely need less than 10 lines of code. Not much, right?
But, I will also need to test and verify that each variable has been imputed correctly.
Instead, the same task in SAS VDMML would just require you to drop an Imputation node into the pipeline and select via a drop-down menu how to impute the variables - no time wasted.
Additionally, you can quickly compare a variety of supervised learning methods as well as test out the same model with different pre-processing methods using the automatic evaluations provided.
Looking to save even more time?
You can use the autotuning feature to select the best set of hyperparameters for your model by turning it on in your supervised learning node of choice and hitting run.
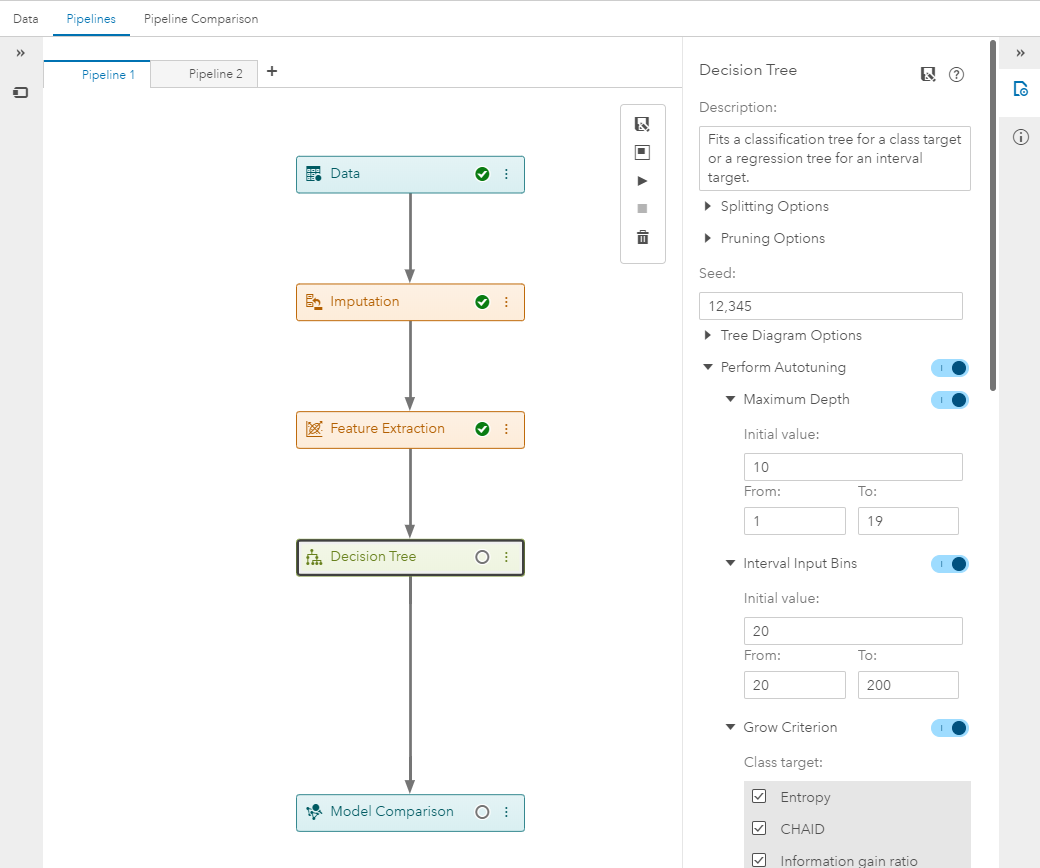
After the run is complete, view the supervised learning model's results to see the best configuration of parameters as determined by autotuning.
All of this can be accomplished with a few clicks, which eliminates the hours spent debugging scripts and connecting the steps in your workflow.
 You’ve spent the last hour transforming and creating features in your code editor of choice. Now, after waiting 30 minutes for your model to run again, you get the same results! How? Wait...you’ve forgotten to update the reference to your new data, AGAIN. (This has definitely not happened to me.)
You’ve spent the last hour transforming and creating features in your code editor of choice. Now, after waiting 30 minutes for your model to run again, you get the same results! How? Wait...you’ve forgotten to update the reference to your new data, AGAIN. (This has definitely not happened to me.)
Fortunately, SAS VDMML only allows you to view results if the pipeline is up-to-date, which ensures that all changes are accounted for. Now, instead of checking and checking again that I passed the right data to the right functions, I can immediately know that my small tweak had no effect on the results. *sigh* OR on a brighter note, that the drastic improvement is not a fluke!

Interested in checking out SAS Viya?
Machine Learning Using SAS Viya is a course that teaches machine learning basics, gives instruction on using SAS Viya VDMML, and provides access to the SAS Viya for Learners software all for $79.This course is the pre-requisite course for the SAS Certified Specialist in Machine Learning Certification. Going through the course myself, I was able to quickly learn how to use SAS VDMML and received a refresher on many data preprocessing tactics and machine learning concepts.
Want to learning more?
Stay tuned!!
I will be posting blogs with in-depth examples of specific features in the SAS VDMML and adding links to the new blog posts here as they are posted. If you there’s any specific features you would like to know more about, leave a comment below!

6 Comments
Hello,
Thank you so much for the detailed explanation! I am interested in learning medical image analysis (preferably histology images and DICOM images).
Can you please let me know where to get started?
Thank you,
Madhu
It was a great article that was both instructive and beneficial to me. Thank you for sharing your expert knowledge with us.
Nice blog post. information is really so meaningful and you have explained every point so clearly ... I really liked the way you are explaining... thank you so much for this article...
Jonathan, thanks for your detailed explanation. I might try Viya sometime.
How SAS Viya is different from SAS EMiner? More intuitive GUI or something else?
Hi Tingting. I would actually use SAS Visual Data Mining and Machine Learning on Viya (VDMML) as the frame of reference to Enterprise Miner (EM). Viya is the framework on which VDMML runs.
As the Product Management lead for SAS Machine Learning products, I position VDMML as an evolution of EM. For years, EM has been the go-to data mining and machine learning tool for running end-to-end model tournaments, from feature engineering, selection, and extraction, modeling, and most importantly - deployment. As a client-server product, it enabled both desktop and server users to access this environment.
VDMML provides a web-based experience for data scientists to interactively explore, model, and deploy, using a robust set of machine learning, deep learning, and even text mining techniques. What you will find is that there are many more modern machine learning and deep learning techniques, in addition to expanded open source integration in VDMML.
With regards to the wonderful Model Studio blog that Christa wrote above, she has shown how intuitive, collaborative, and powerful VDMML can be. Model Studio is the 'pipeline' generator in VDMML, akin to the EM process flow. One of my favorite features of VDMML is 'The Exchange' that Christa referenced, for accessing best practice templates from SAS and your colleagues.
Finally, there is built in integration and migration in Model Studio, for ingesting supported EM batch code, so that you can use your EM flows as a good starting point.
Please let me know if we can help you out further.
Good luck!!