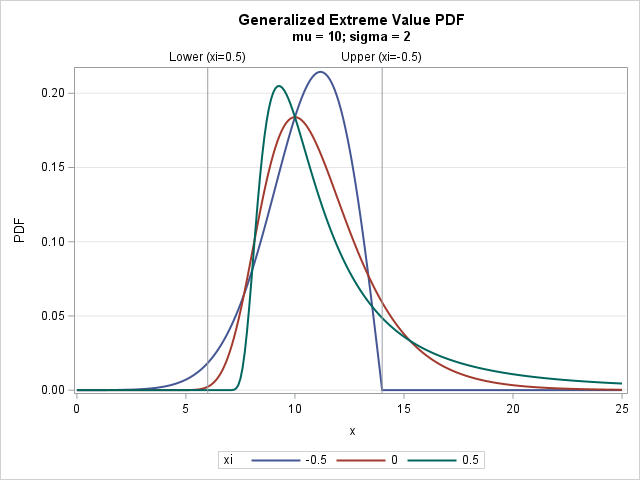
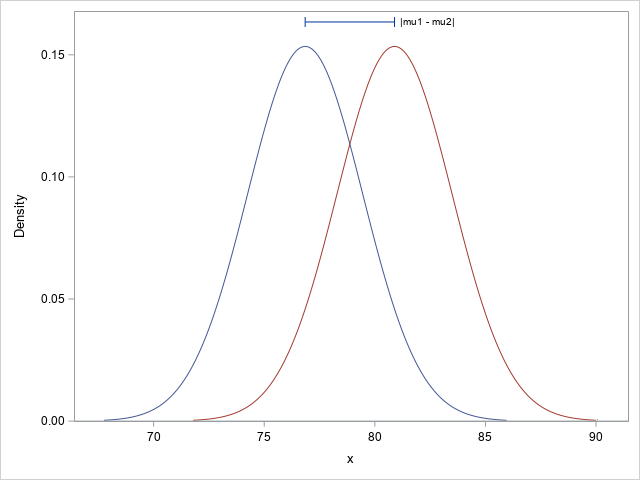
A SAS macro technique for running a one-time task

In data analysis, sometimes we need to perform a preliminary task before we can analyze data. Often the task needs to be performed only once per session. For example, you might need to download or merge data prior to your analysis. Or you might need to define or load a