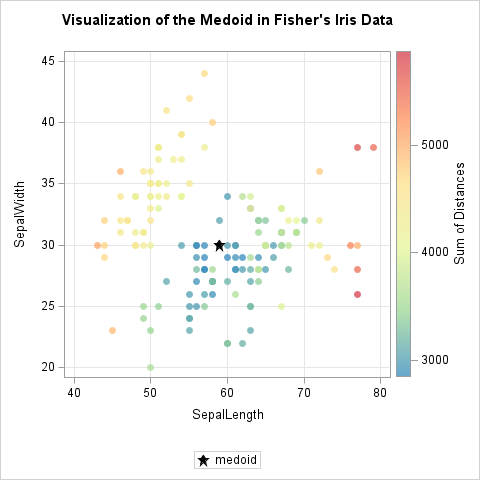
What is a medoid?

In univariate data analysis, the median is often used as an alternative to the mean because the mean is sensitive to outliers in the data, whereas the median is a robust statistic. For higher-dimensional data, the mean and the centroid are both used to represent the "center" of a cloud



