Matrix norms and spectra

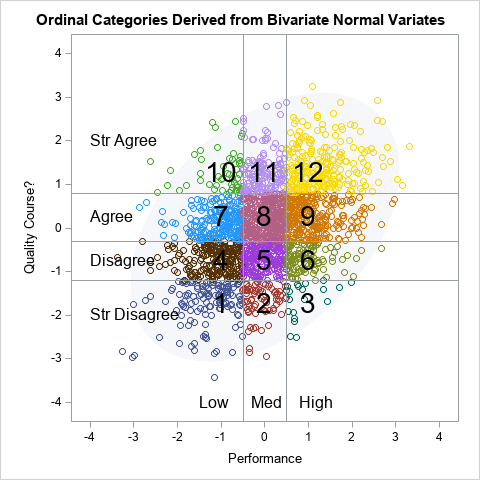
A previous article discusses covariance matrices that have the same set of eigenvalues. The set of eigenvalues is called the spectrum of the matrix. For symmetric matrices, the spectrum contains real numbers. For covariance matrices, which are positive semidefinite, the eigenvalues are nonnegative. It turns out that two symmetric matrices