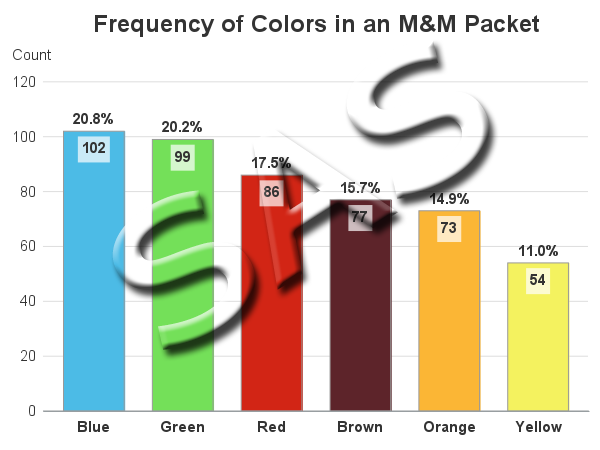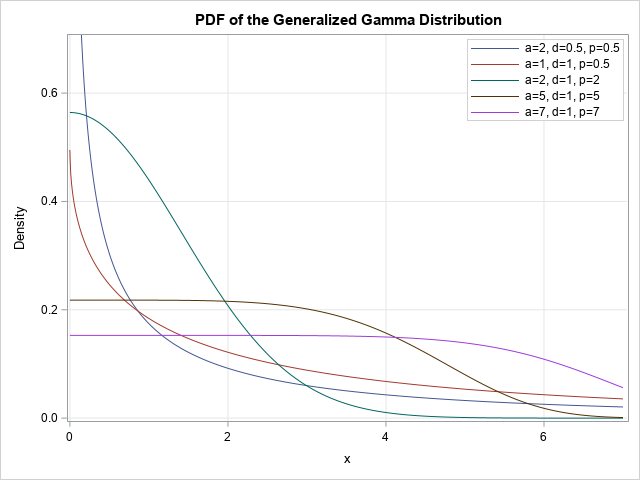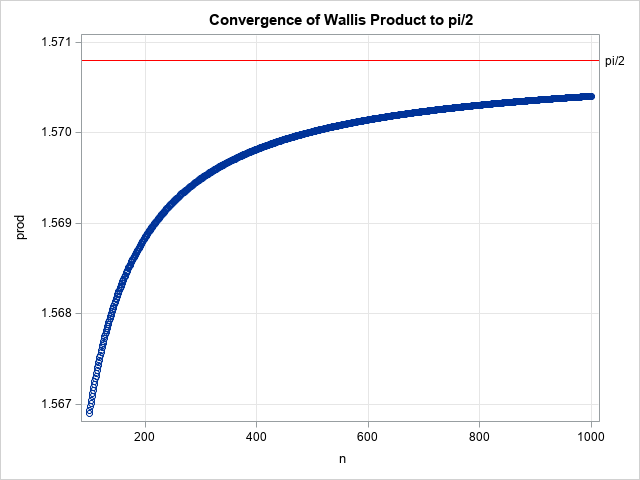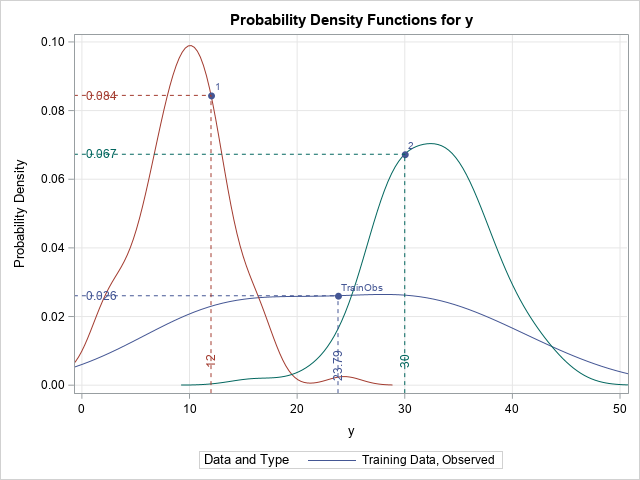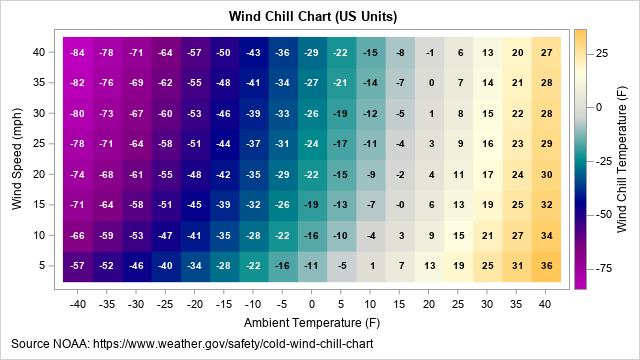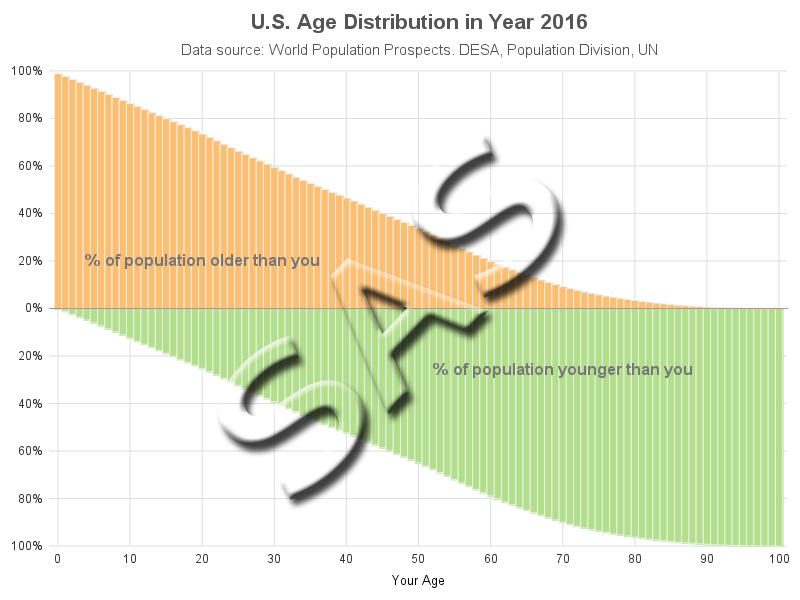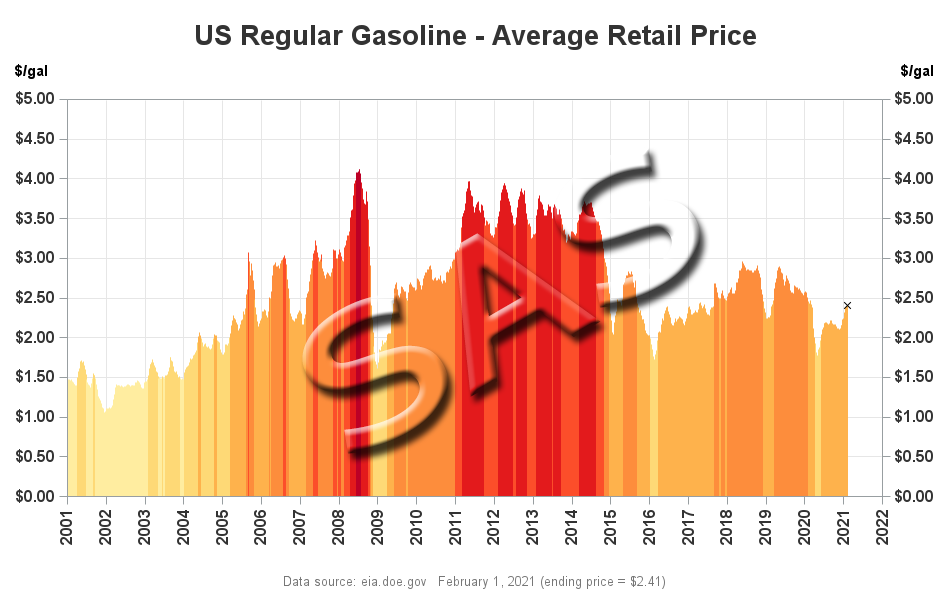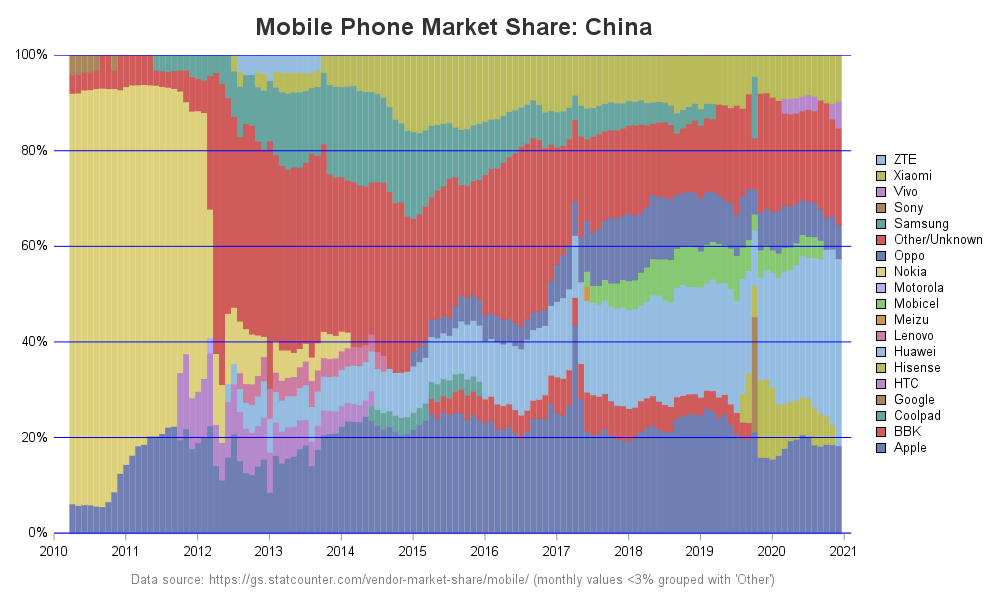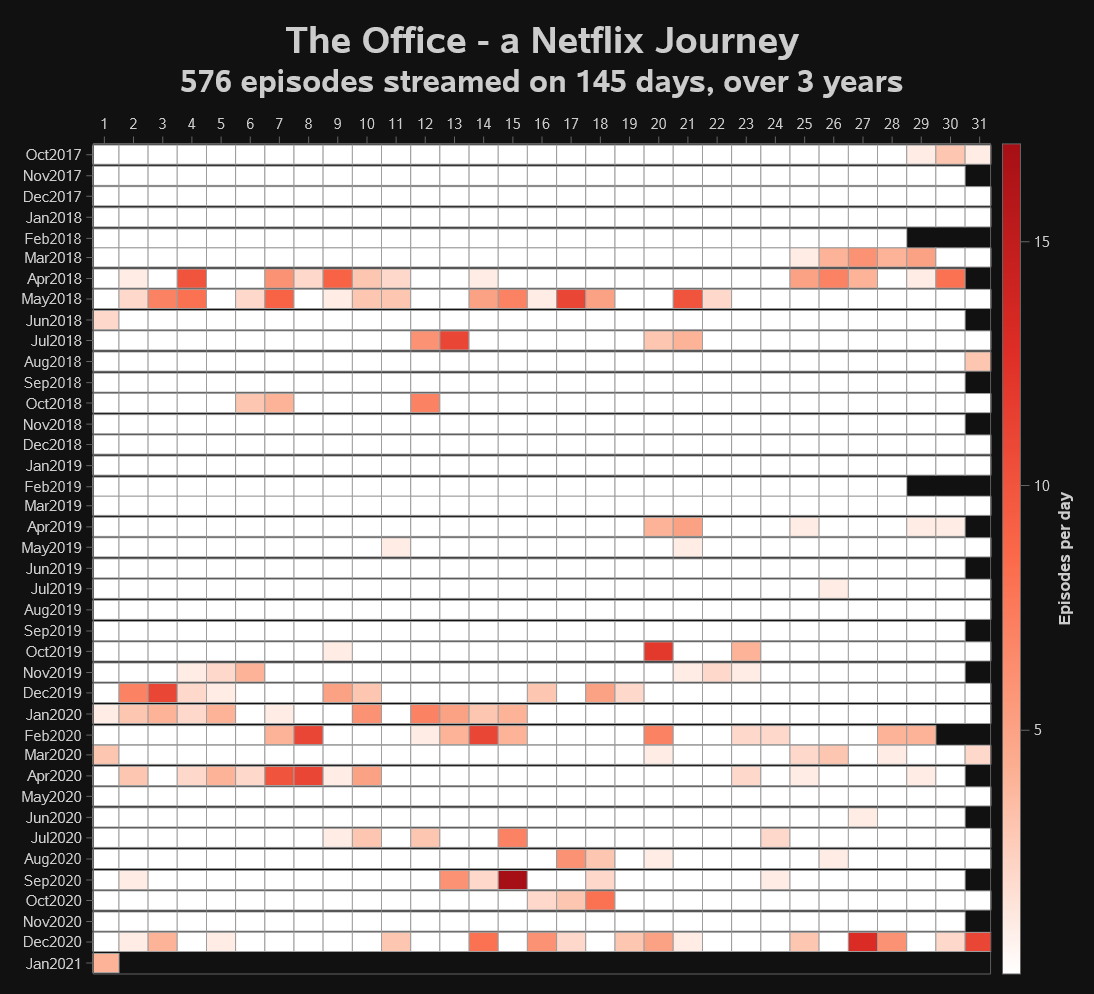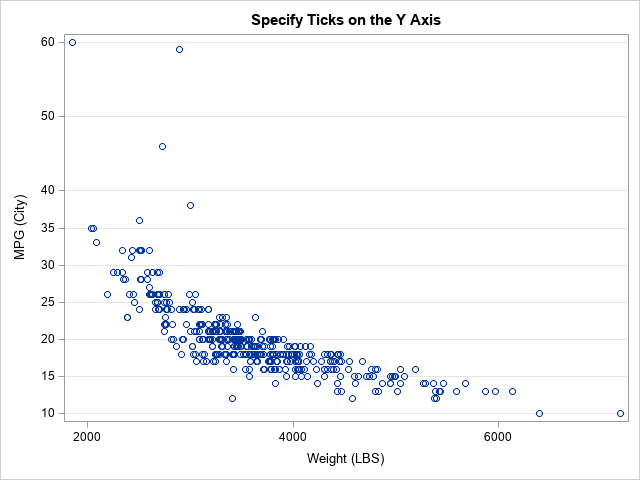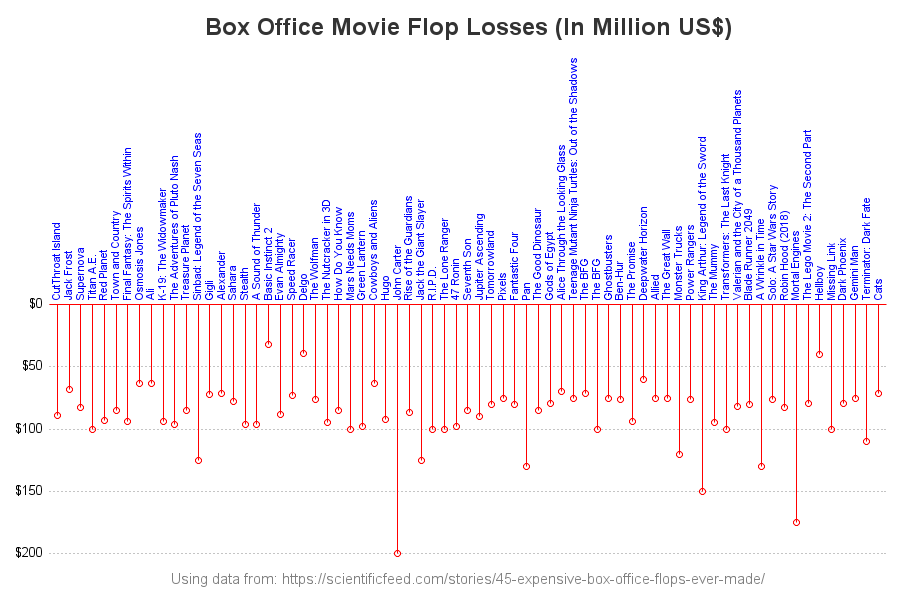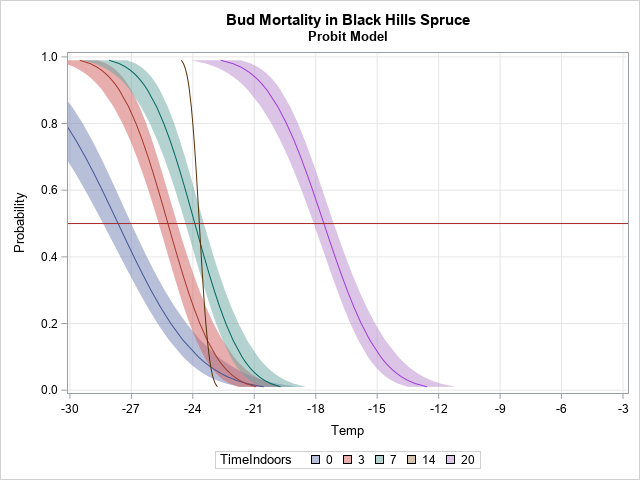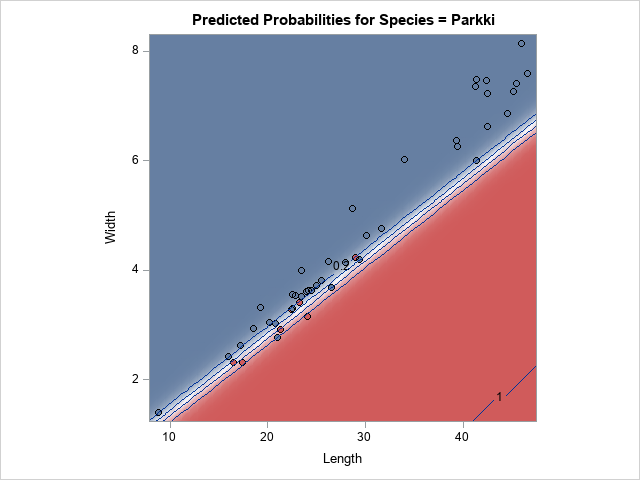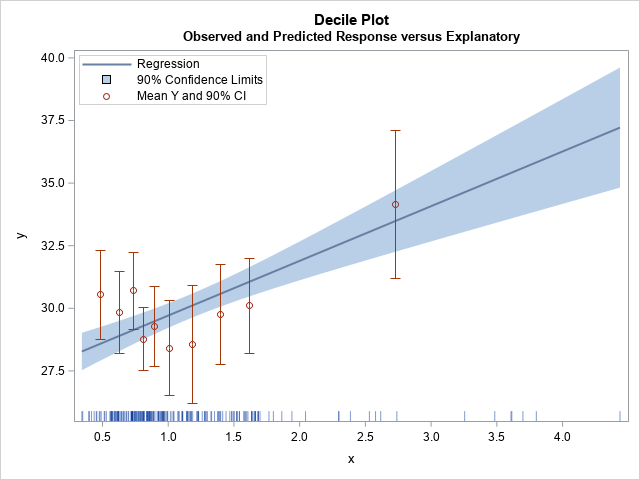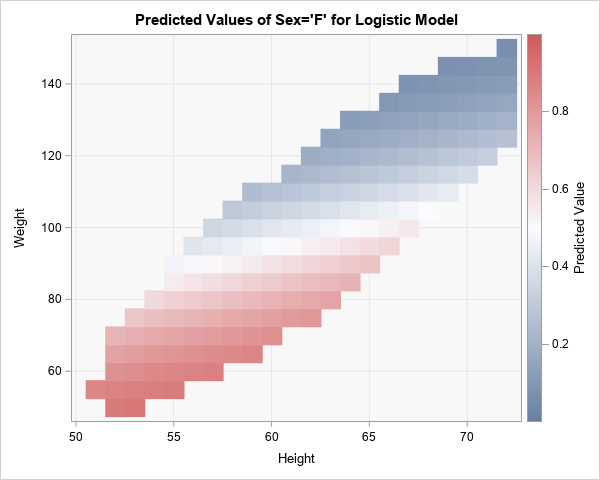
The Farey sequence

Here is an interesting math question: How many reduced fractions in the interval (0, 1) have a denominator less than 100? The question is difficult is because of the word "reduced." If we only care about the total number of fractions in (0,1) whose denominator is less than 100, we