All Posts
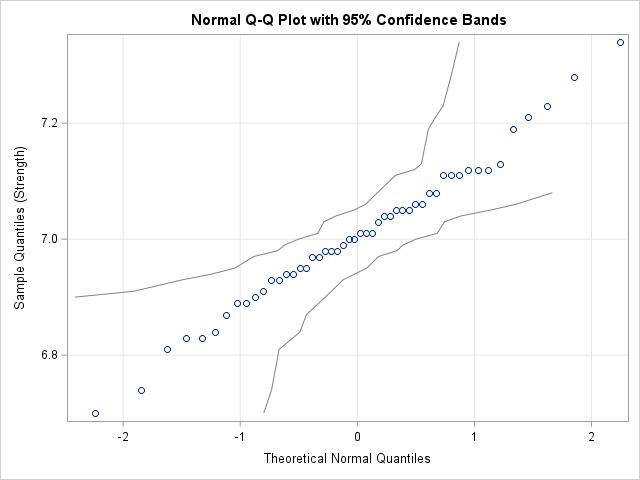

This article shows how to compute a confidence band for a Q-Q plot in SAS. A previous article shows how to construct confidence bands for the CDF of continuous univariate data. The bands can be added to a plot of the empirical CDF (ECDF) for the data. One of the




AI readiness is often framed around models, technology and talent. In practice, it starts with something more fundamental: trusted data. Without clean, integrated and governed data, even the most sophisticated AI systems can produce unreliable results and erode confidence across the business. I often meet with data industry professionals and


Under value-based care contracts, health systems are more responsible for both patient outcomes and the total cost of care. That means a preventable readmission, a delayed diagnosis or a missed follow-up appointment can affect not only patient health but also financial performance. To succeed, organizations need a clearer understanding of


Nourishing yourself during pregnancy is one of the most powerful ways you can support your growing baby – and your own well-being. While pregnancy comes with many changes, nutrition doesn’t have to feel overwhelming. With thoughtful, realistic choices, you can support healthy development, steady energy, and recovery through every stage


The platforms we choose don't just shape how data flows. They shape how people work. In clinical analytics, those decisions affect far more than technology. And in clinical development, a platform that only works for part of your team isn't a technology problem. It's a leadership problem and one every
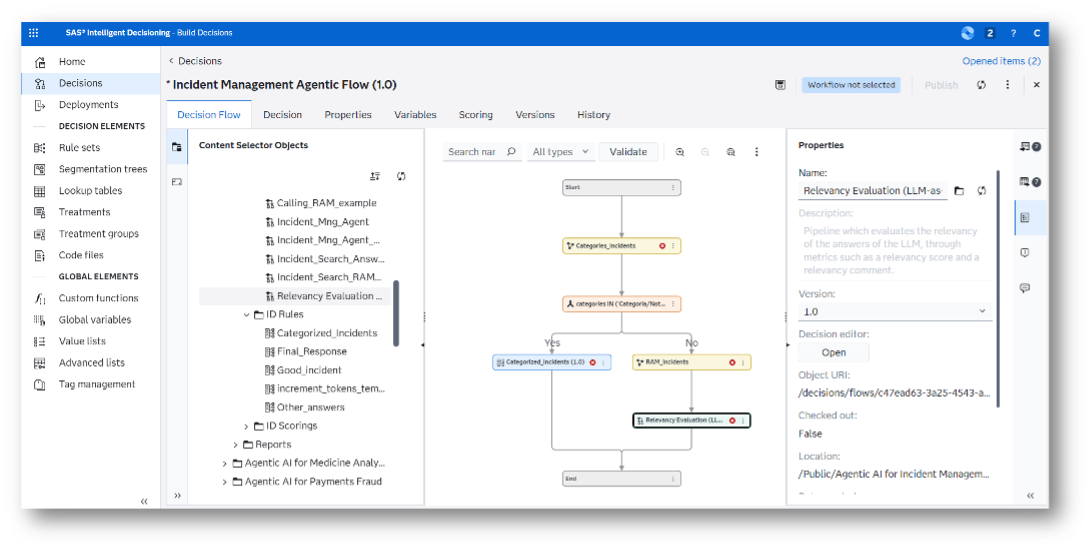

Learn how the SAS Agentic AI Accelerator and SAS Viya can be used to build a governed, multi-agent support-ticket solution that combines text analytics, RAG, LLMs, business rules, and human oversight to improve resolution speed, accuracy, and operational efficiency.
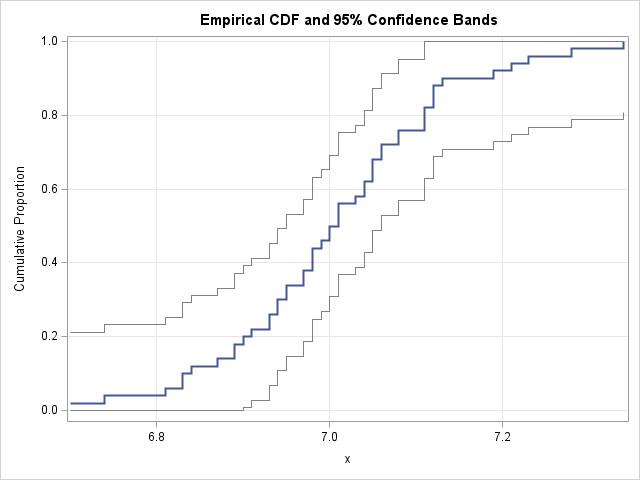
A previous article shows how to construct an empirical cumulative distribution function (ECDF) for univariate data by using PROC UNIVARIATE or in the SAS IML language. The ECDF is a tool for visualizing the distribution of a sample and is helpful for estimating quantiles in the data. In statistics, we


Most leaders do not have an AI problem. They have a readiness problem. In many small and midsized businesses, pilots are underway and use cases are defined. But when leaders step back and ask the harder question, "Is AI actually paying off?", the answer is often less clear. This gap


En el actual ecosistema empresarial de Latinoamérica, las organizaciones ya no buscan simplemente herramientas que analicen datos; necesitan sistemas capaces de actuar. La evolución de la Inteligencia Artificial hacia un modelo agéntico marca el inicio de una era para sectores como el de las telecomunicaciones, donde la autonomía de la


A duplicate customer record. A missing zip code. A workaround someone did years ago. On their own, these don’t seem like big issues. But together, they create inconsistencies that have a ripple effect – often with major consequences. Here’s a truth that we can all agree on: If your data


Explore how SAS AI-Driven Entity Resolution on SAS Viya combines no-code configuration, probabilistic matching, and industry-specific integrations to create trusted identities, improve data quality, and support critical decisions across sectors such as public services and financial crime prevention.


A quick search through headlines reveals a range of AI-related disappointments. Consider that 95% of GenAI pilots fail, according to MIT. Amazon’s Kiro agent recently sparked a 13-hour outage by deleting a production environment. And we can’t forget that the resource and energy strain from a new wave of AI


Marketers have made enormous strides with generative AI (GenAI) over the last year, moving from experimentation to large-scale deployment. But the next shift in AI maturity – agentic AI – is already underway. This shift will push organizations beyond prompt-based productivity and into a world where AI can act, learn


Desde sus orígenes en el ámbito estadístico hasta la actual era de la inteligencia artificial, SAS celebra cinco décadas de innovación confiable. Durante este tiempo, la organización ha demostrado que, cuando las empresas invierten en las personas e innovan con un propósito claro, la confianza se consolida como el activo