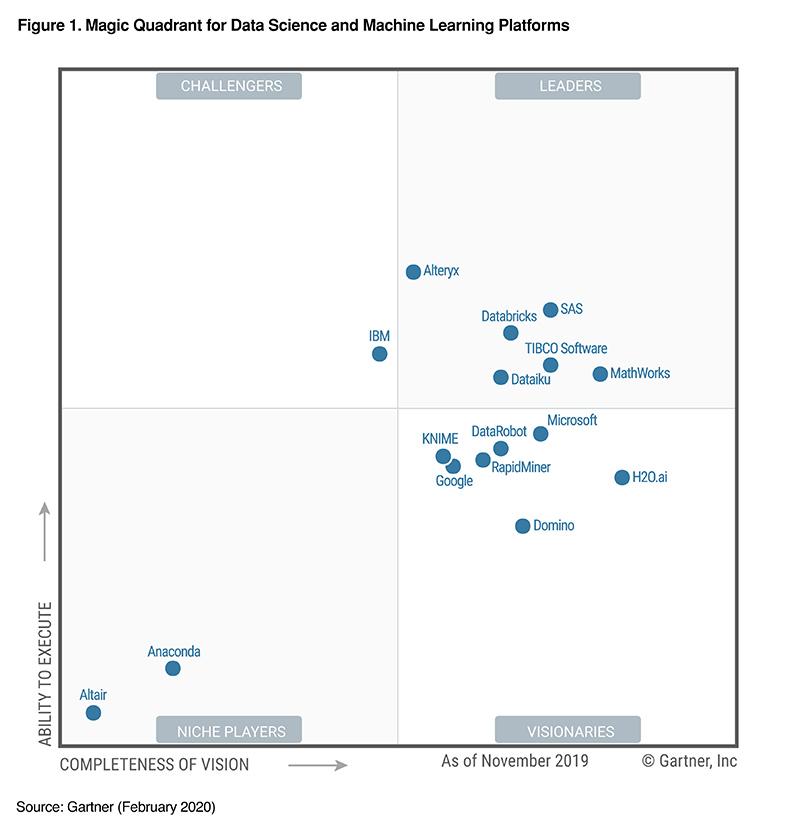
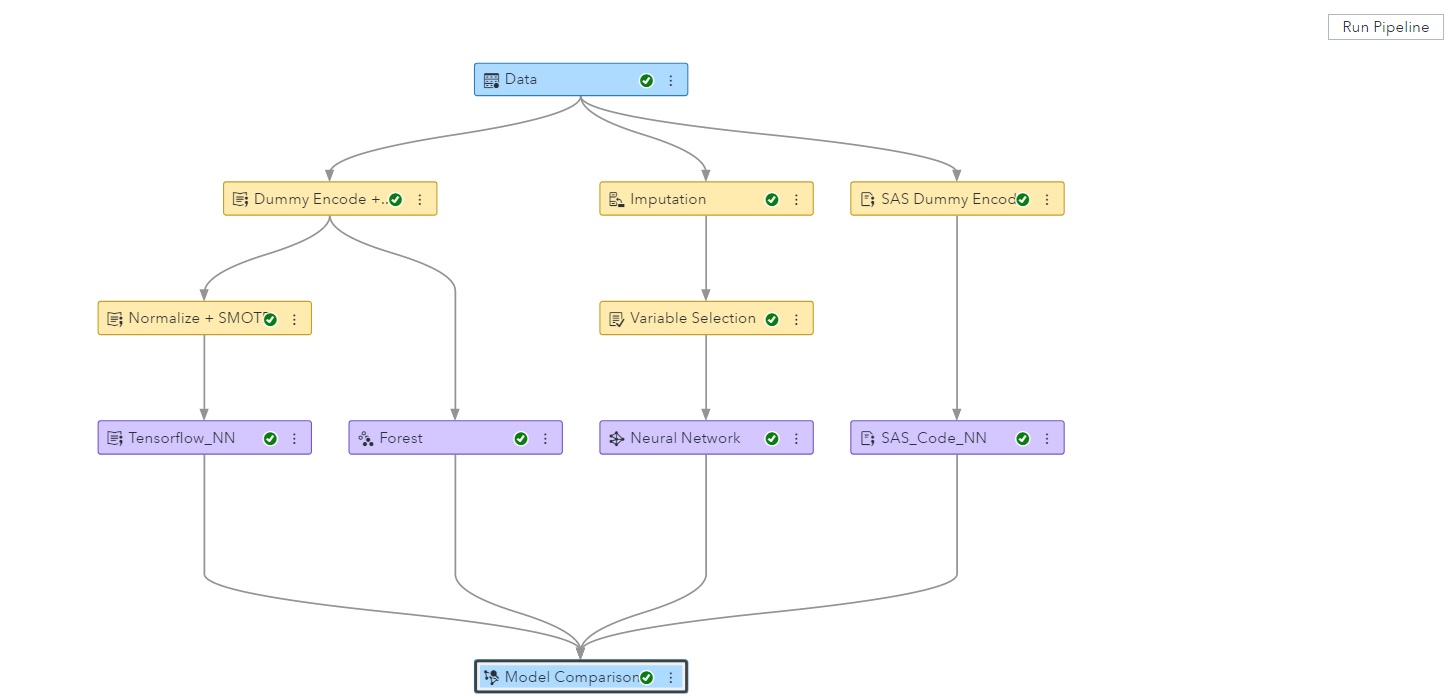
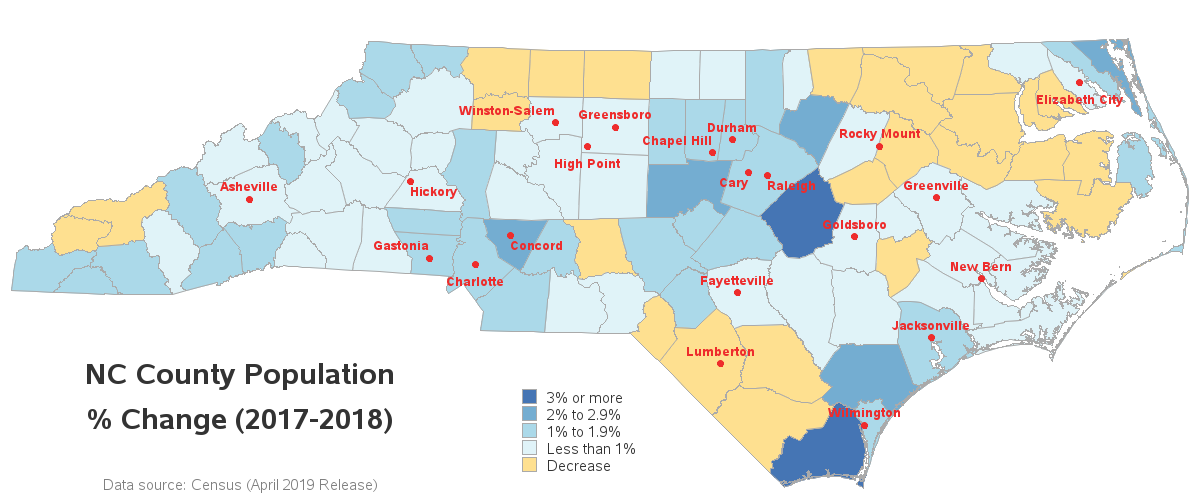
How to share your SAS knowledge with your professional network

SAS Global Forum 2020 is not the conference experience we thought it would be. Thousands of us had planned to gather in person to share our enthusiasm and knowledge about SAS and power of data and analytics. We were going to combine our skills and knowledge to inspire one another