This blog is part of a series on SAS Visual Data Mining and Machine Learning (VDMML).
If you're new to SAS VDMML and you want a brief overview of the features available, check out my last blog post!
This blog will discuss types of missing data and how to use imputation in SAS VDMML to improve your predictions.
Imputation is an important aspect of data preprocessing that has the potential to make (or break) your model. The goal of imputation is to replace missing values with values that are close to what the missing value might have been. If successful, you will have more data with which the model can learn. However, you could introduce serious bias and make learning more difficult.

When considering imputation, you have two main tasks:
- Try to identify the missing data mechanism (i.e. what caused your data to be missing)
- Determine which method of imputation to use
Why is your data missing?
Identifying exactly why your data is missing is often a complex task, as the reason may not be apparent or easily identified. However, determining whether there is a pattern to the missingness is crucial to ensuring that your model is as unbiased as possible, and that you have enough data to work with.
One reason imputation may be used is that many machine learning models cannot use missing values and only do complete case analysis, meaning that any observation with missing values will be excluded.
Why is this a problem? Well look at the percentage of missing data in this dataset...
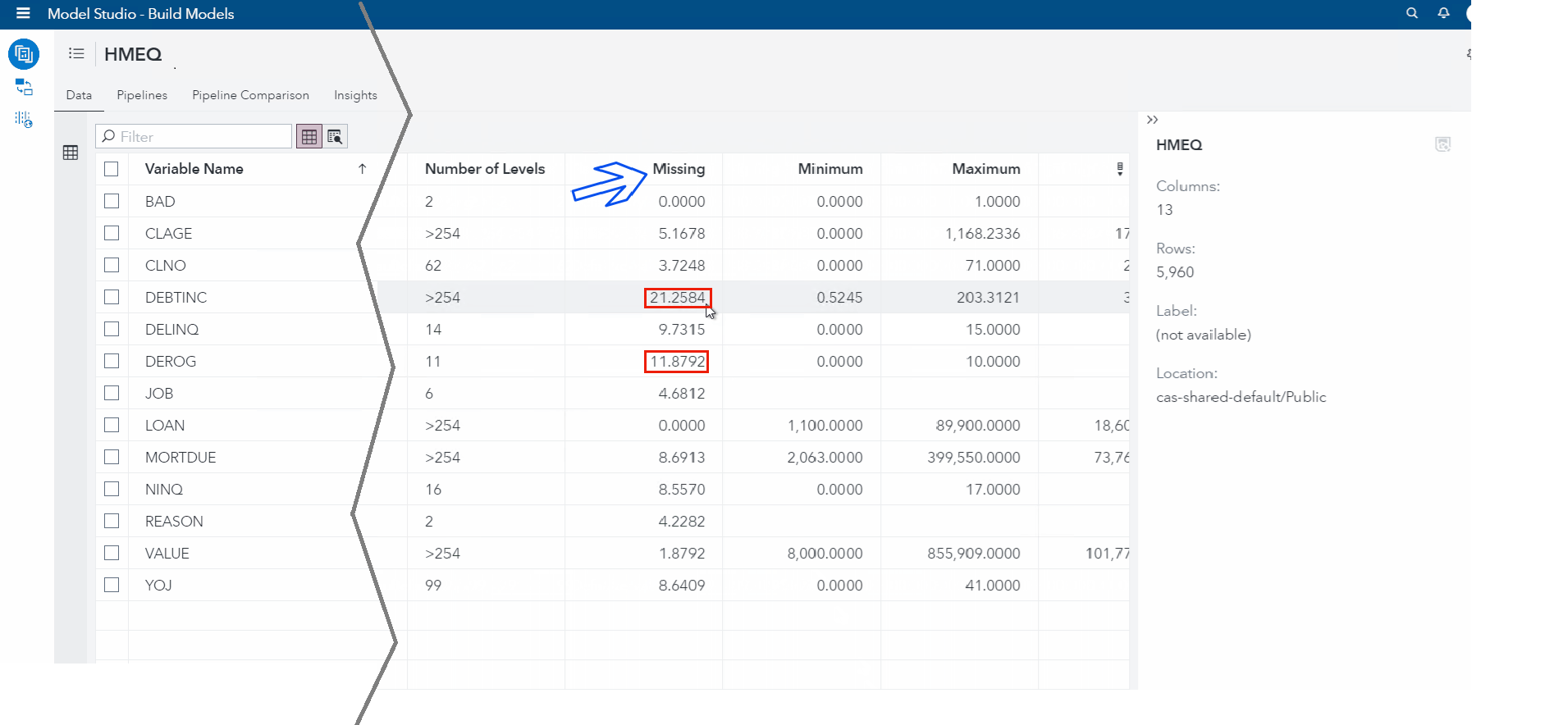
If we use complete case analysis with this data, we will lose at least 21% of our observations! Not good.
Missing data can be classified in 3 types:
- missing completely at random (MCAR),
- missing at random (MAR),
- and missing not at random (MNAR).
Missing completely at random (MCAR) indicates the missingness is unrelated to any of the variables in the analysis -- rare case for missing data. This means that neither the values that are missing nor the other variables associated with those observations are related to the missingness. In this case, complete case analysis should not produce a biased model. However, if you are concerned about losing data, imputing the missing values is still a valid approach.
Data can also be missing at random (MAR), where the missing variable value is random and unrelated to the missingness, but the missingness is related to the other variables in the analysis. For example, let’s say there was a survey sent out in the mail asking participants about their activity levels. Then, a portion of surveys from the certain region were lost in the mail. In this case, the missing data is not at random, but this missingness is not related to the variable we are interested in, activity level.

An important consideration is that even though the missingness is unrelated to activity level, the data could be biased if participants in that region are particularly fit or lazy. Therefore, if we had data from other people in the affected region, we may be able to use that information in how we impute the data. However, imputing MAR data will bias the results, to what extent will be dependent on your data and method for imputation.
In some cases, the data is missing not at random (MNAR) and the missingness could provide information that is useful to prediction. MNAR data is non-ignorable and must be addressed or your model will be biased. For example, if a survey asks a sensitive question about a person's weight, a higher proportion of people with a heavier weight may withhold that information -- creating bias within the missing data. One possible solution is to create another level or label for the missing value.
The bottom-line is that whether you should use imputation for missing values is completely dependent on your data and what the missing value represents. Be diligent!
If you have determined that imputation may be beneficial for your data, there are several options to choose from. I will not be going into detail on the types of imputation available as the type you use will be highly dependent on your data and goals, but I have listed a few examples below to give you a glimpse of the possibilities.
Examples of types of imputations:
- Mean, Median
- Regression
- Hot-deck
- Last Observation Carried Forward (LOCF - for longitudinal data)
- Multiple Imputation
How to Impute in SAS VDMML
Now, I will show an example of Imputation in SAS Viya - Model Studio. (SAS VDMML)
First, I created a New Project, selecting the Data Mining and Machine Learning, and the default template.
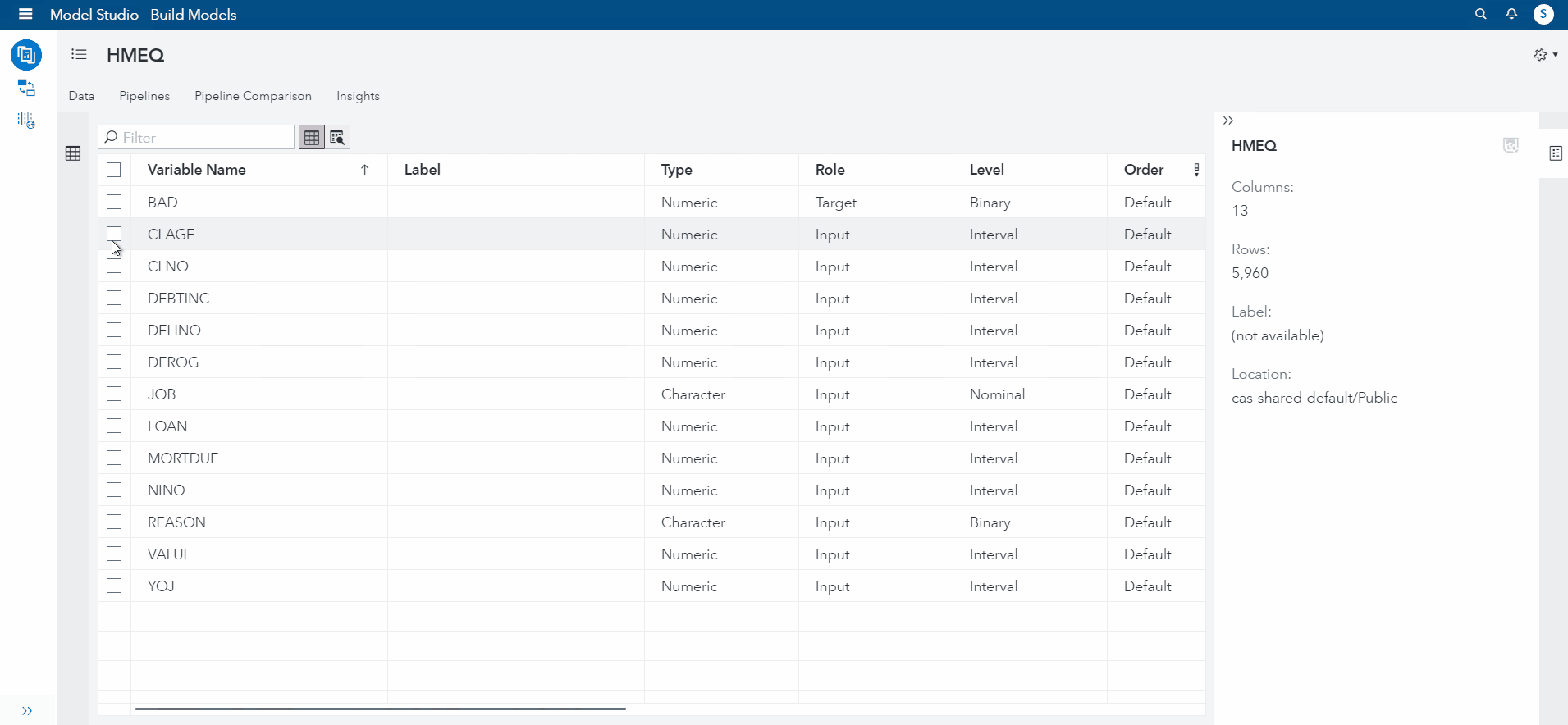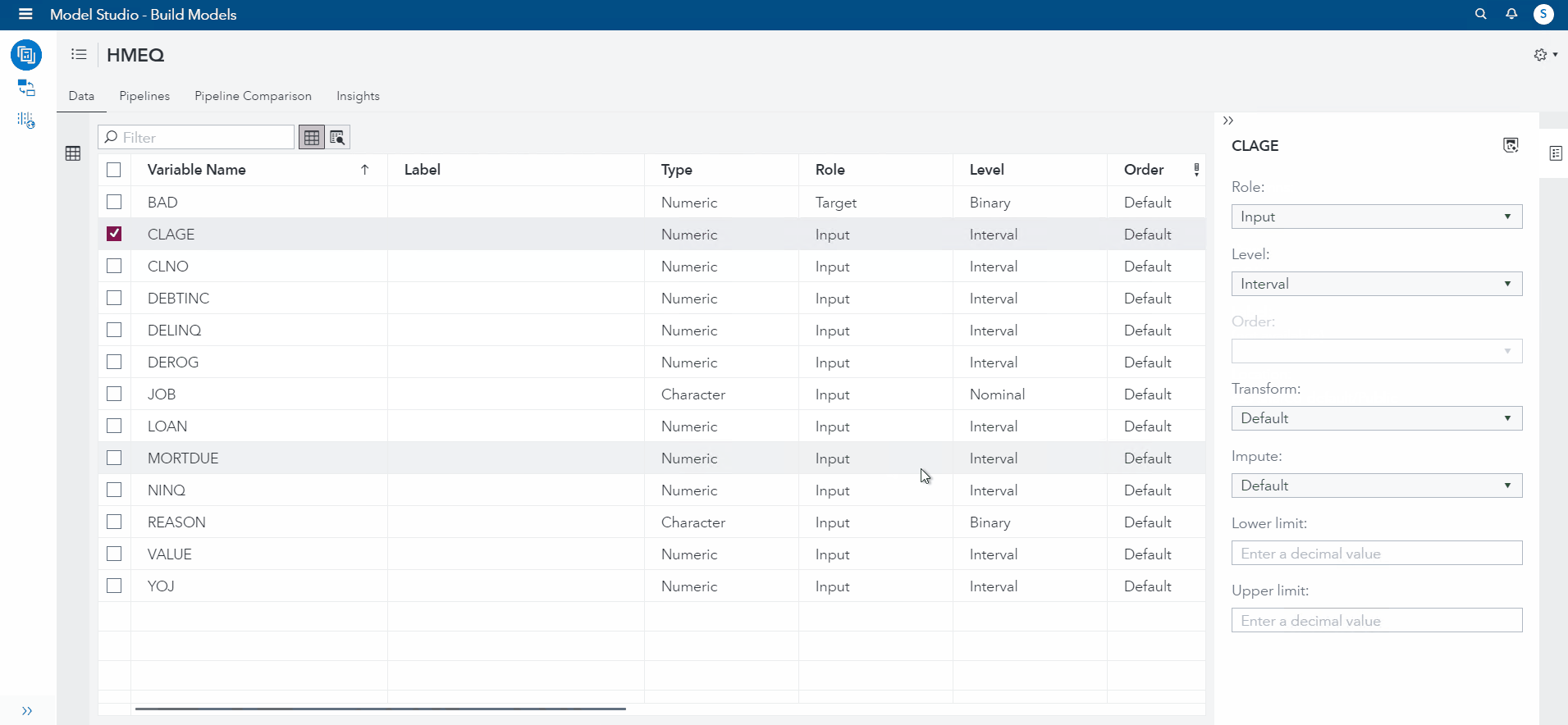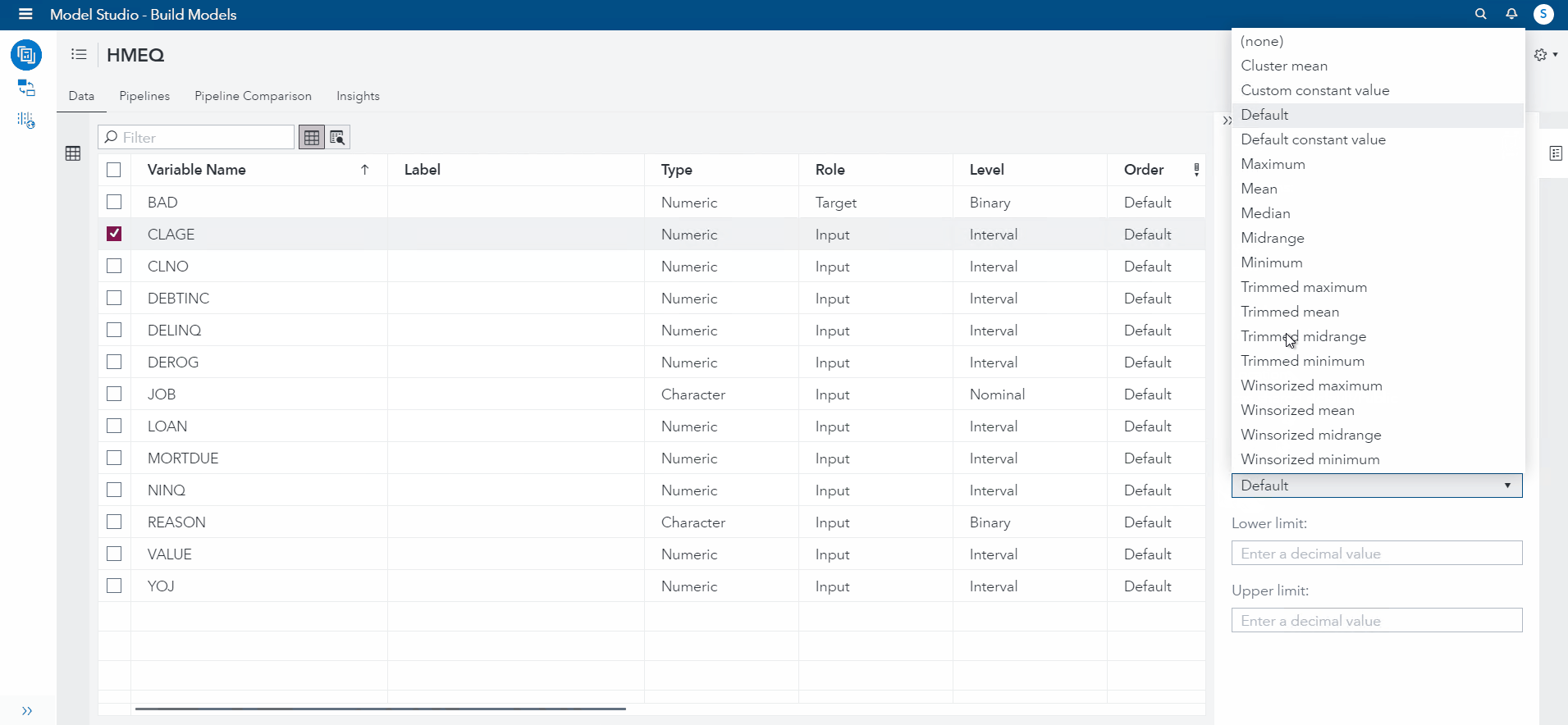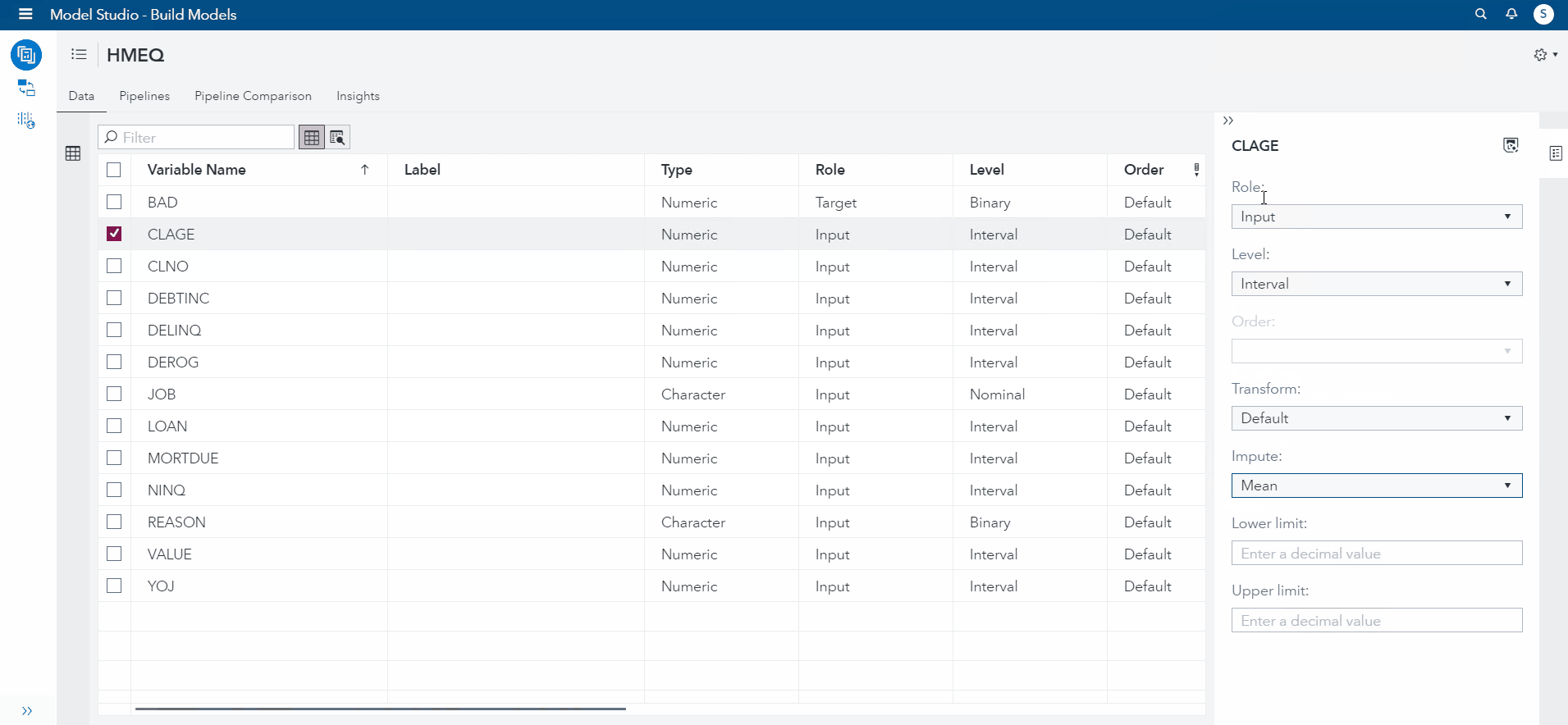
On the data tab, I will specify how I want certain features to be imputed. This does not do the imputation for us! Think about the specifications on the data tab as a blueprint for how you want the machine learning pipeline to handle the data.
To start, I selected CLAGE feature and changed the imputation to "Mean" (See demonstration below). Then, I selected DELINQ and changed the imputation to "Median". For NINQ, I selected "minimum" as the imputed value. For DEBTINC and YOJ, I will set the Imputation for both to Custom Constant Value (50,100).
Now, I will go over to the Pipeline tab, and add an imputation node (this is where the work gets done!)
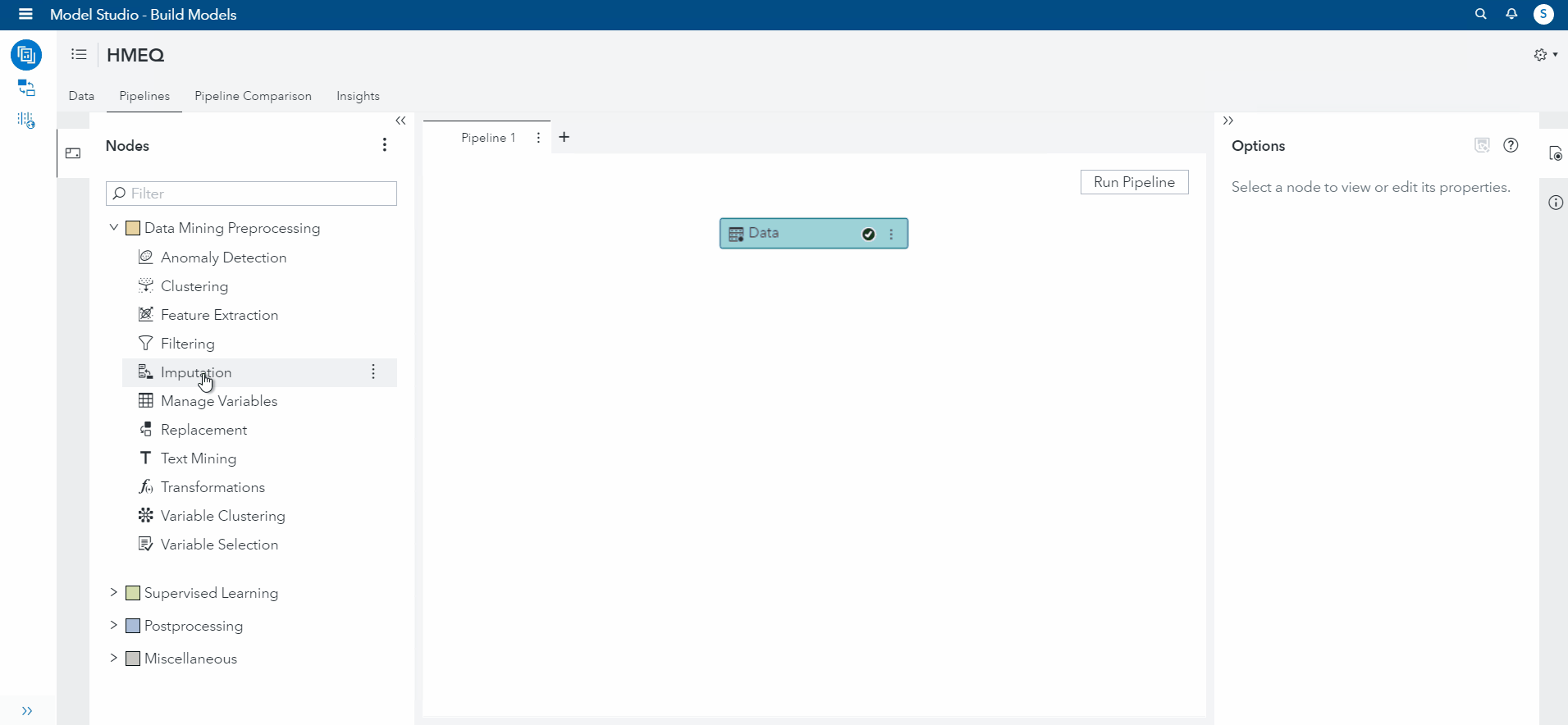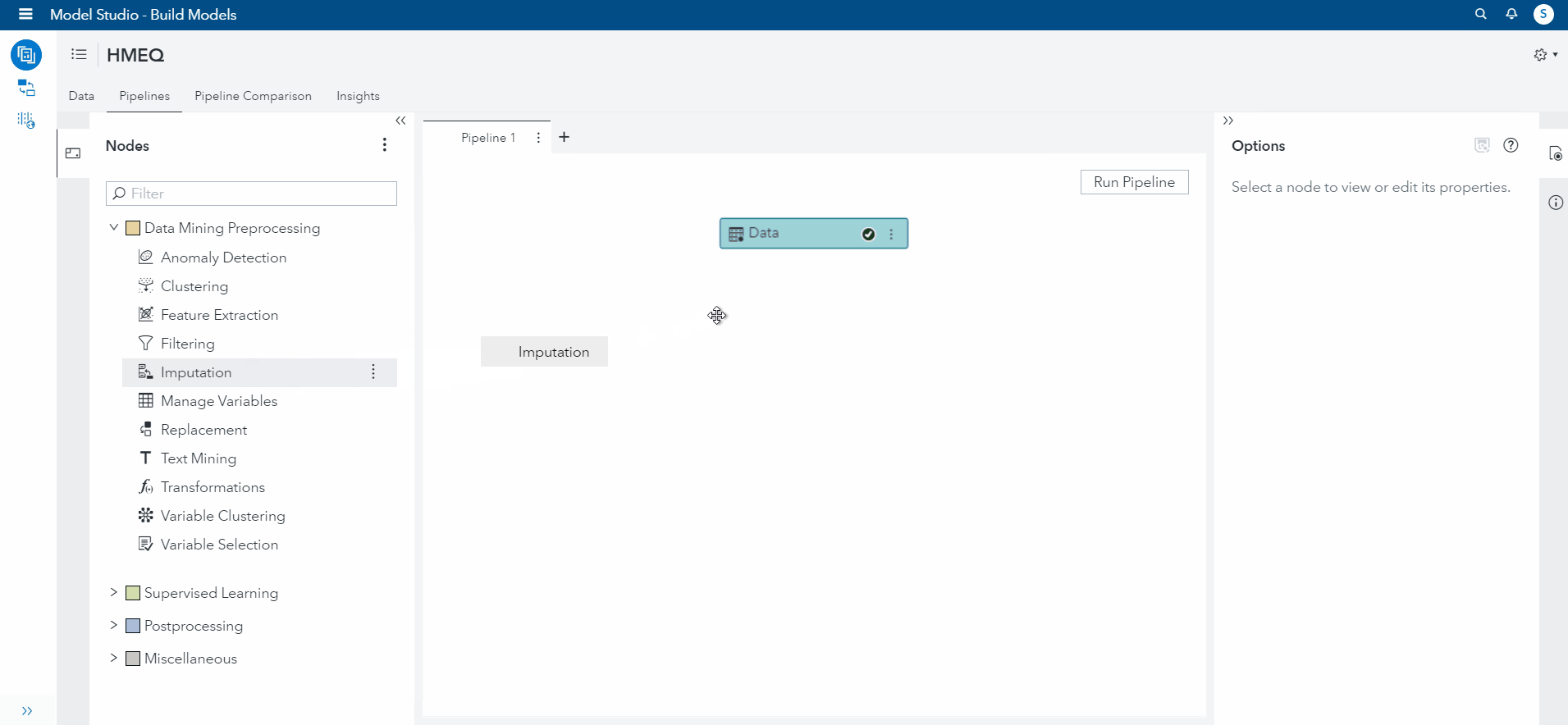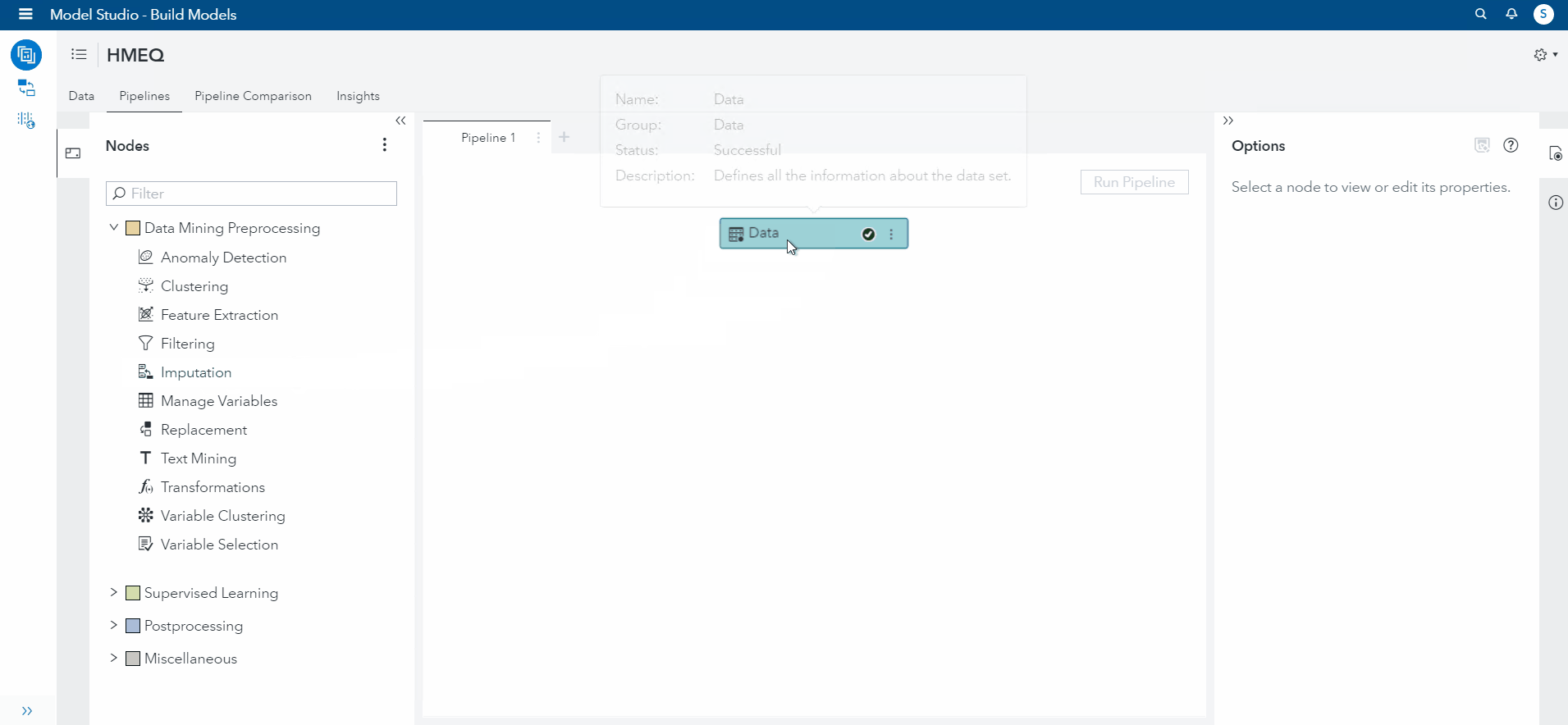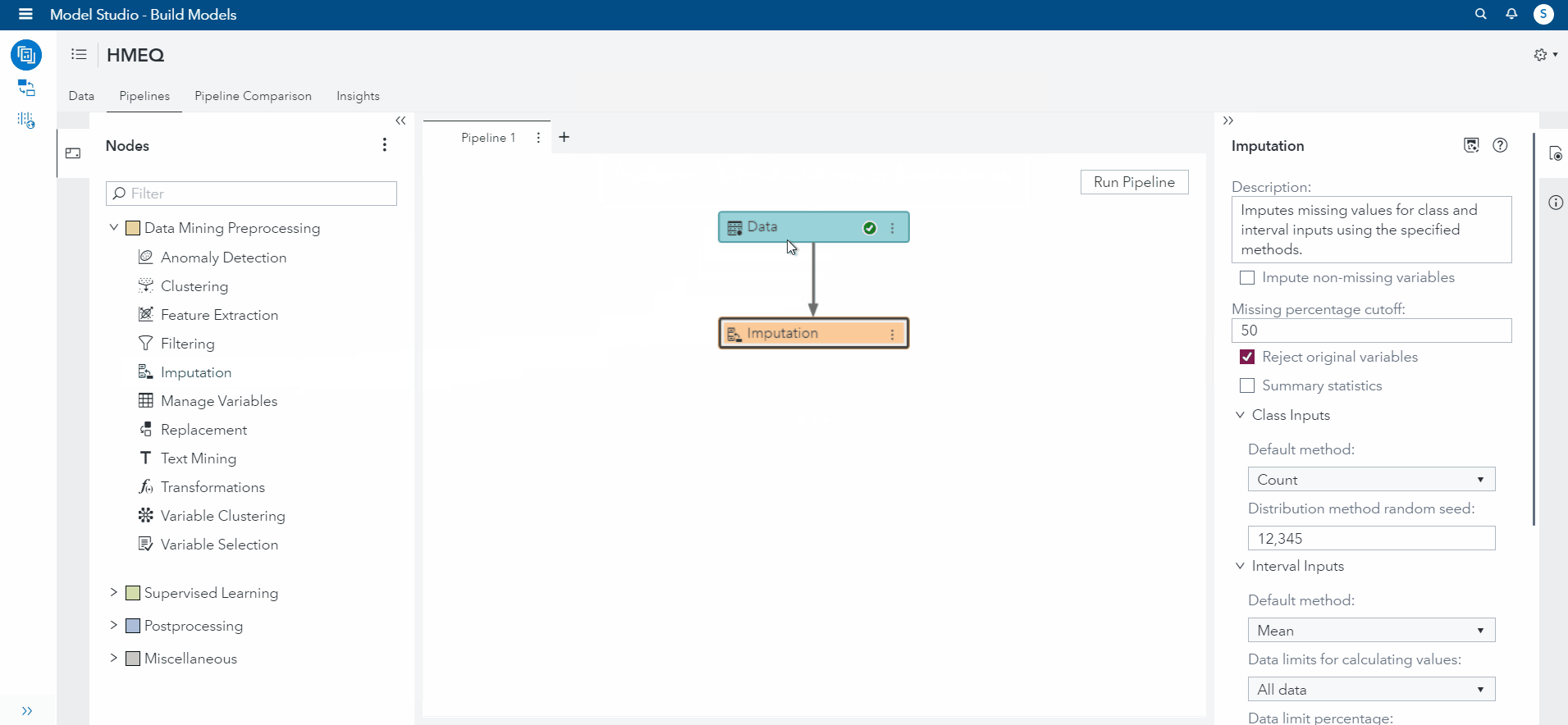
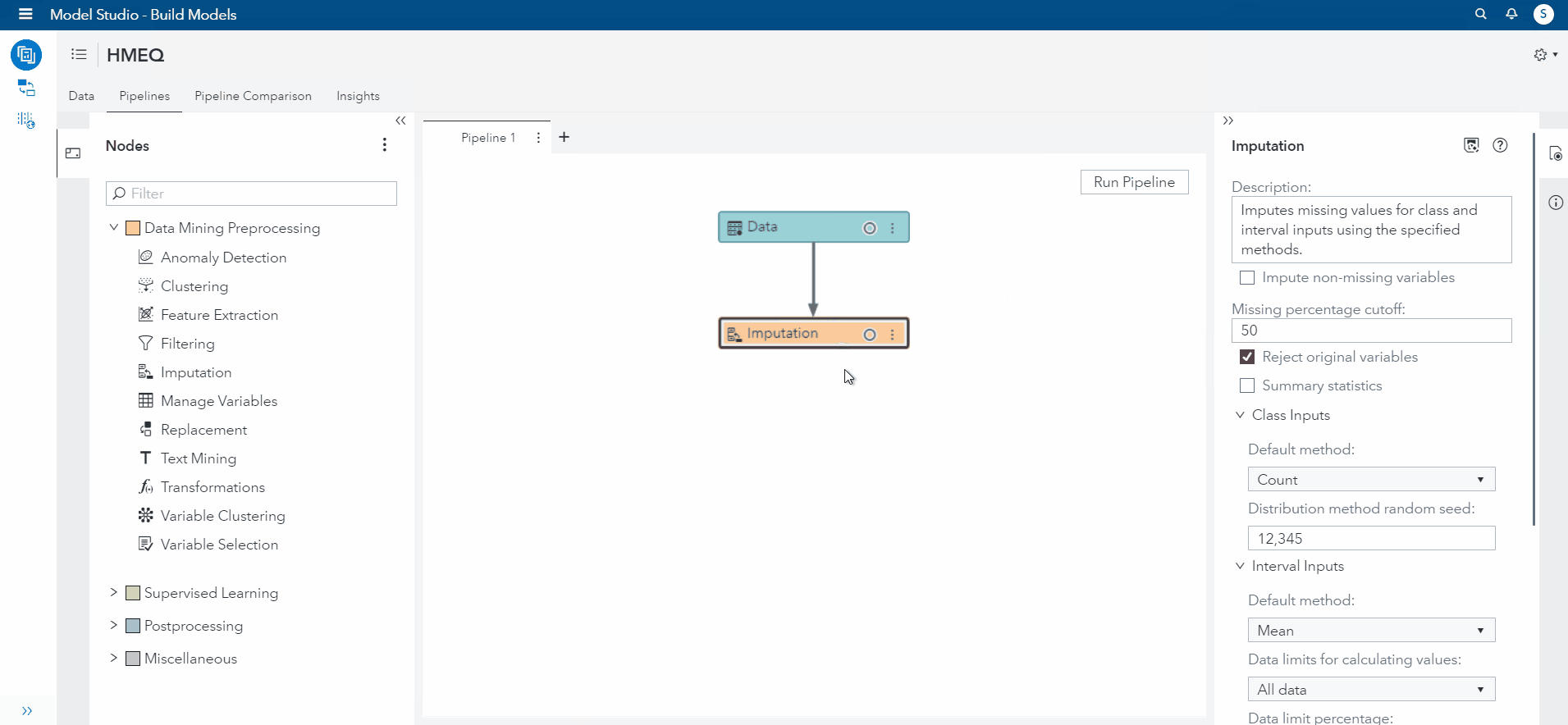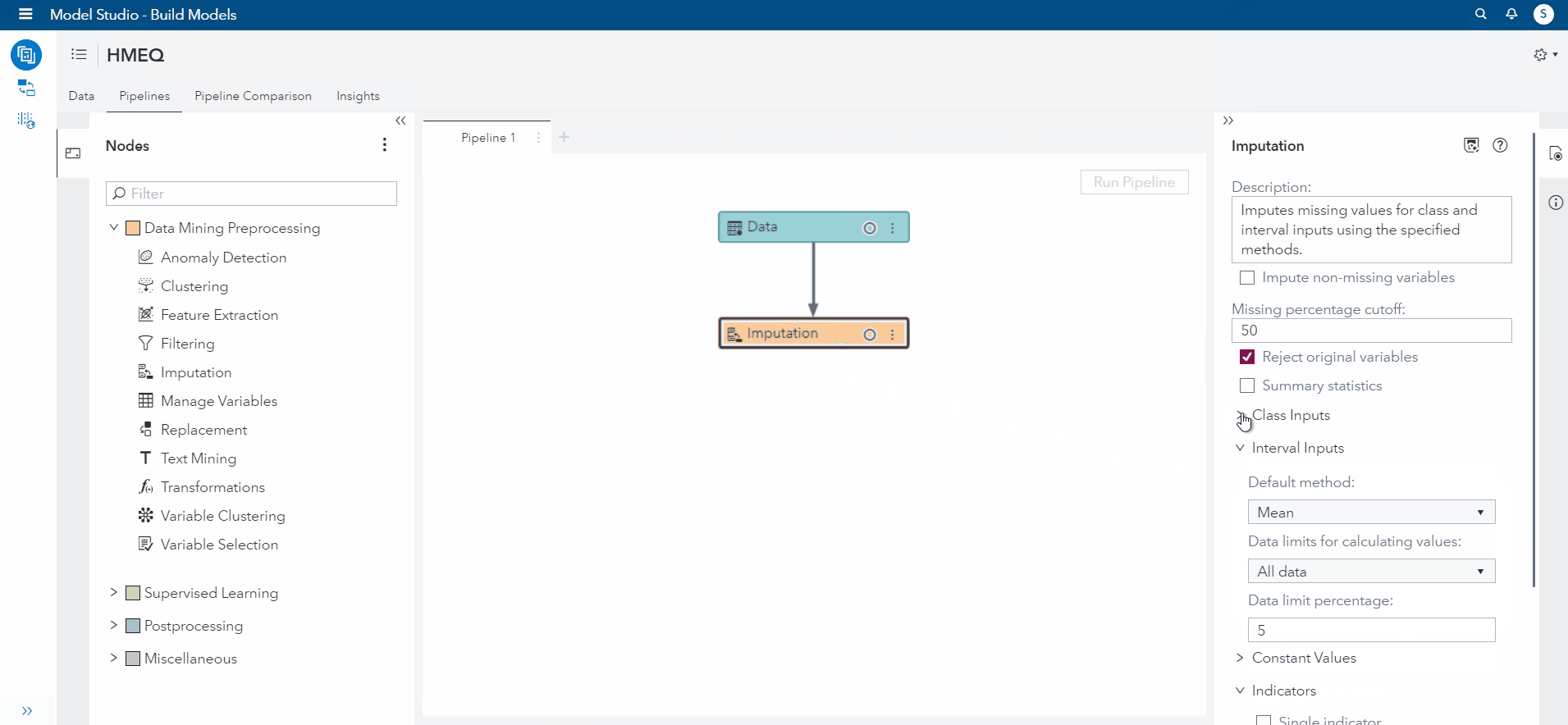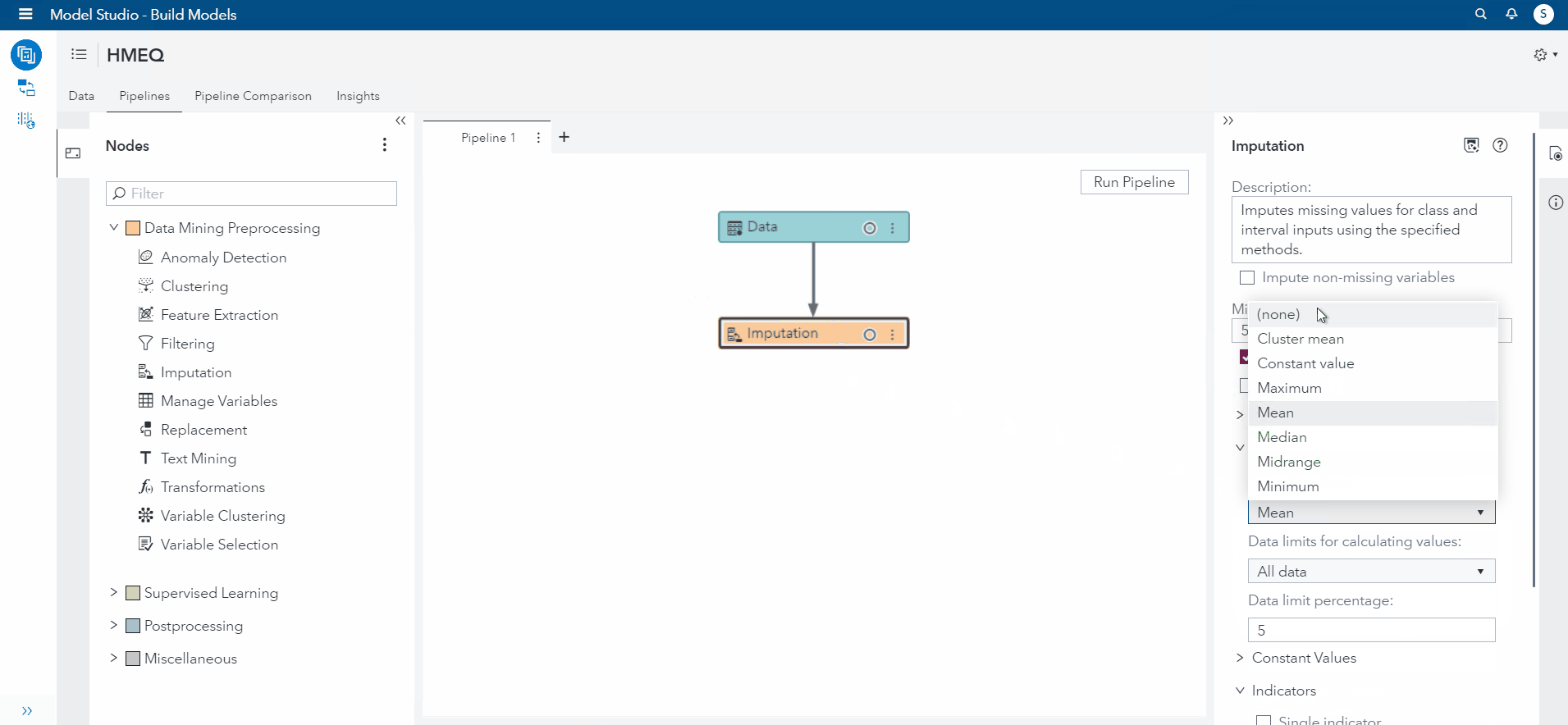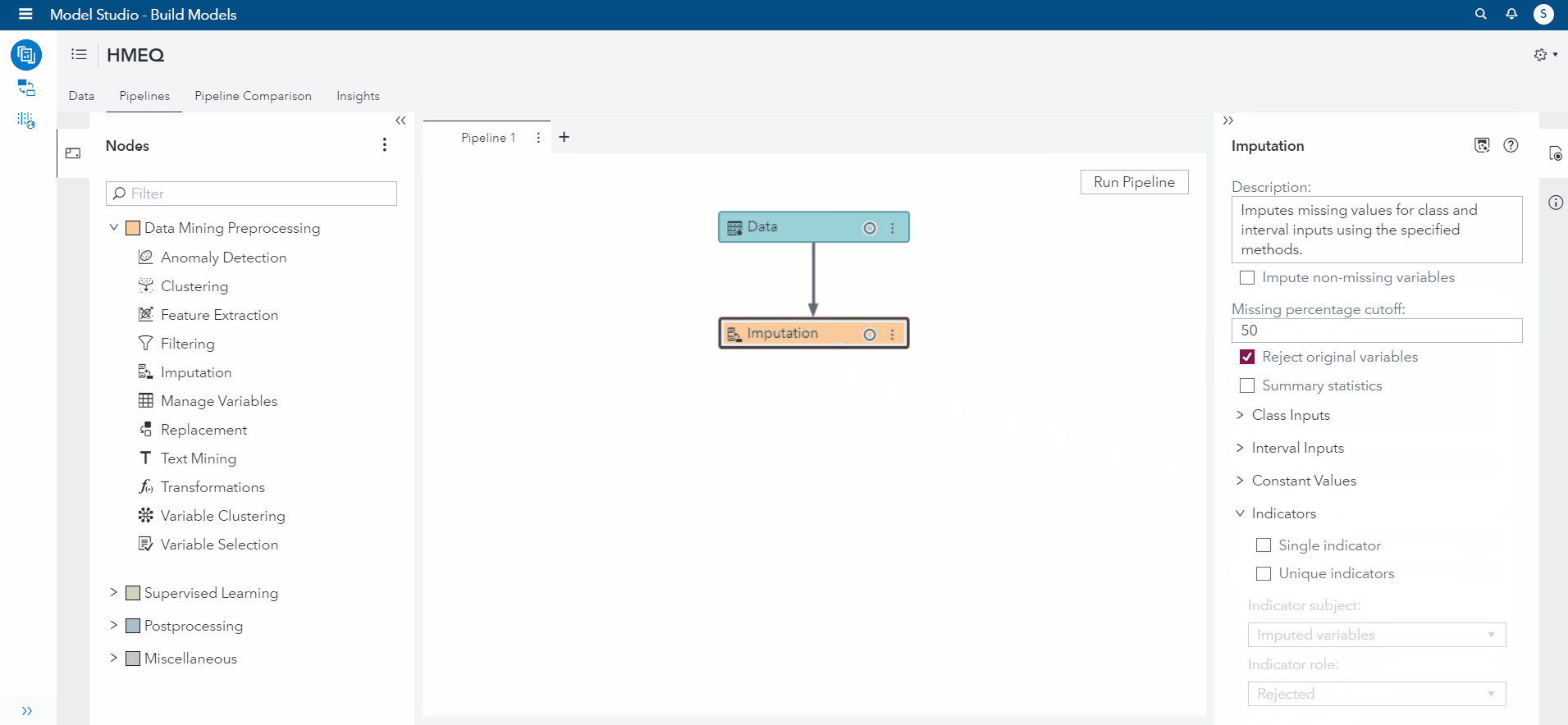
Selecting the imputation node, I view the options and change the default operations for imputation to none. I changed this because we only want the variables previously specified to be imputed. However, if you wanted to run the default imputation, SAS VDMML automatically imputes all missing values that are Class (categorical) variables to the Median and Interval (numerical) values to the Mean.
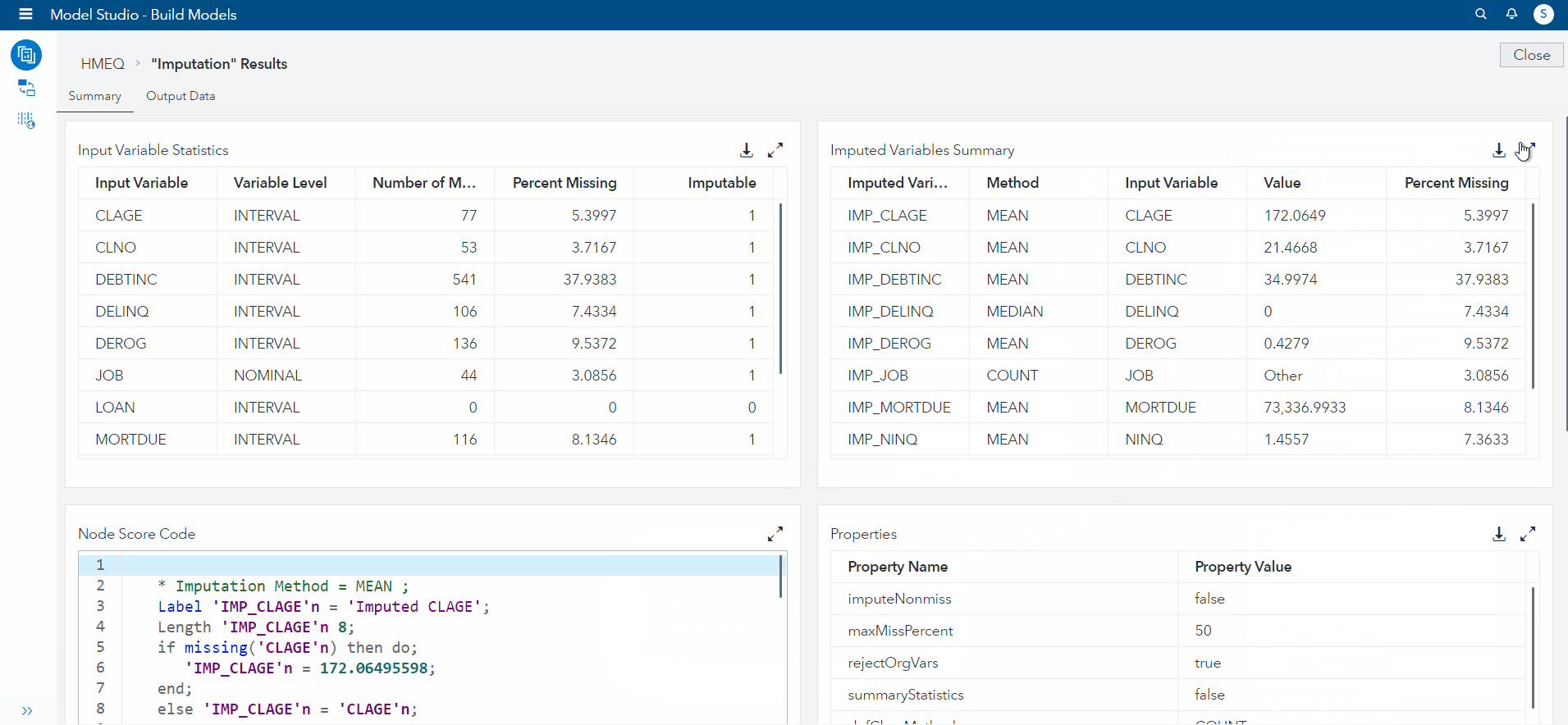
Looking at the results, we can see what variables imputation was performed on, what value was used, and how many values for each variable were replaced.
And that's how easy it is to impute variables in SAS Model Studio!
Interested in checking out SAS Viya?
Machine Learning Using SAS Viya is a course that teaches machine learning basics, gives instruction on using SAS Viya VDMML, and provides access to the SAS Viya for Learners software all for $79.This course is the pre-requisite course for the SAS Certified Specialist in Machine Learning Certification. Going through the course myself, I was able to quickly learn how to use SAS VDMML and received a refresher on many data preprocessing tactics and machine learning concepts.
Want to learn more?
Stay tuned; I will be posting more blogs with examples of specific features in the SAS VDMML. If you there’s any specific features you would like to know more about, leave a comment below!

1 Comment
Simple and accurate article. Good examples.
Thks.