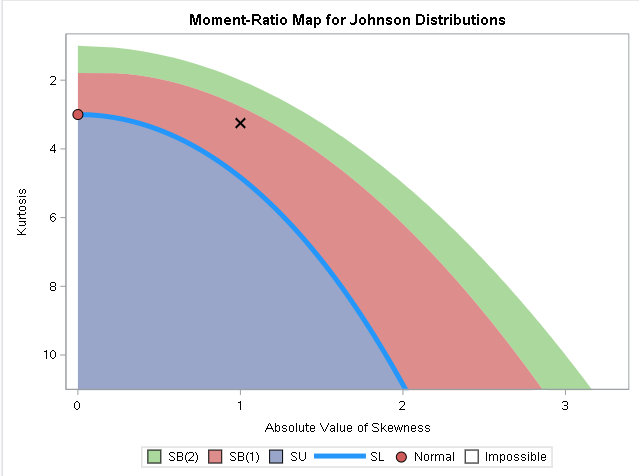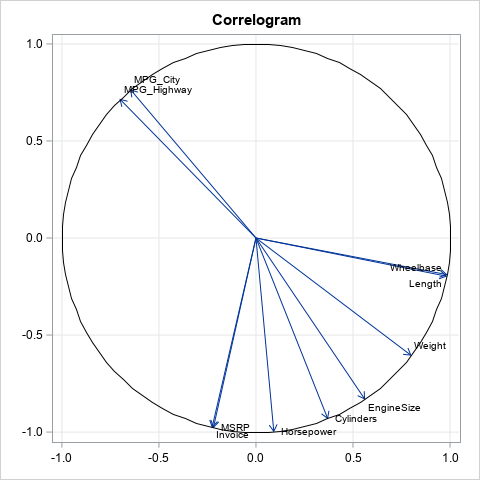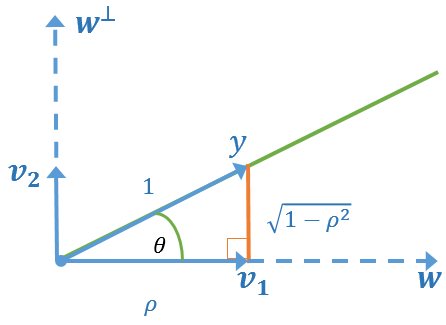
The correlation between two sets of variables

In a correlation analysis, it is common to consider the correlations between all pairs of numerical variables. That is, if there are k numerical variables, most people examine the complete k x k matrix of correlations. This matrix is symmetric and has 1s on the diagonal, so more than half of the