When you count the outcomes of an experiment, you do not always observe all of the possible outcomes. For example, if you roll a six-sided die 10 times, it might be that the "1" face does not appear in those 10 rolls. Obviously, this situation occurs more frequently with small data than with large, although even for large data set, you might not observe rare events.
When conducting a statistical analysis, it is sometimes necessary to specify the unobserved categories. I have previously shown how to use the DATA step to add outcomes with zero counts and run PROC FREQ on the resulting data. I have also shown how to use the DATA step to merge observed data with expected values so that you can overlay a parametric density on a histogram.
In the SAS/IML language, you can use the LOC-ELEMENT technique to merge counts for observed outcomes into a vector of zeros. The result is the counts for all outcomes, where 0 indicates that an outcome is unobserved.The following SAS/IML statements analyze 10 rolls of a six-sided die. The TABULATE subroutine counts the number of times each face appeared. The MergeCounts module inserts the observed counts into a vector.
proc iml;
/* Use LOC-ELEMENT technique to merge observed outcomes into all outcomes */
start MergeCounts(allVals, obsVals, counts);
allCounts = j(nrow(allVals),ncol(allVals),0); /* array of 0s */
idx = loc(element(allVals, obsVals)); /* LOC-ELEMENT technique */
allCounts[idx] = counts; /* insert counts */
return( allCounts );
finish;
rolls = {4 6 4 6 5 2 4 3 3 6}; /* only 5 faces observed */
call tabulate(Vals, Counts, rolls);
allVals = 1:6; /* all outcomes */
allCounts = MergeCounts(allVals, Vals, Counts);
print Counts[c=(char(Vals))] allCounts[c=(char(allVals))]; |
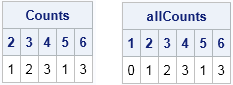
Whereas the first table contains only the five observed faces, the second table lists all six faces of the die, with 0 indicating the "1" face was not observed.
In addition to the applications mentioned earlier, this technique is useful when you are computing goodness-of-fit statistics. For example, to compute the chi-square statistic for the null hypothesis that the die is fair (each face appears equally often), you need to form the difference between the observed and expected values for each face. The following statements implement a chi-square goodness-of-fit test:
Expected = sum(allCounts) / 6;
ChiSq = sum((allCounts-Expected)##2 / Expected); /* sum (O-E)^2/E over categories */
pval = 1 - cdf("chisquare", ChiSq, ncol(allVals)-1); /* p-value for test */
print ChiSq pval; |
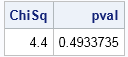
Most statistical textbooks recommend that you not use the chi-square test if the expected counts are less than 5, as they are for this tiny data set. Nevertheless, this example illustrates the usefulness of adding unobserved outcome categories to data that contain the observed categories.

1 Comment
Pingback: Tabulate counts when there are unobserved categories - The DO Loop