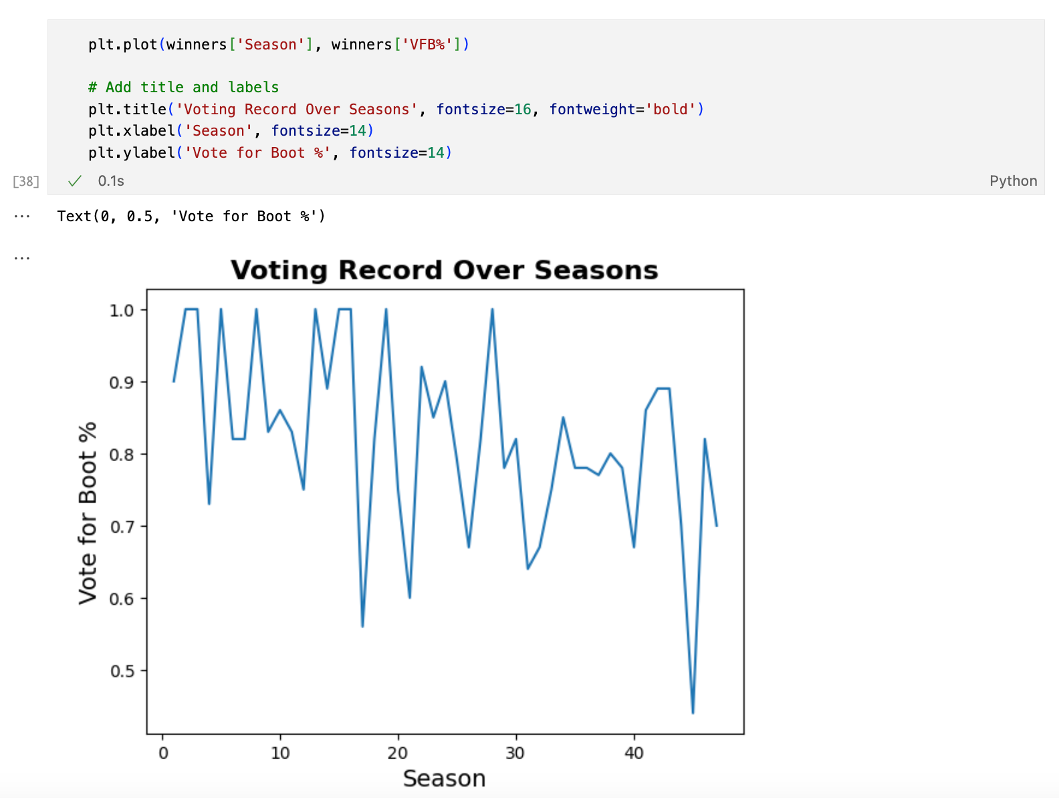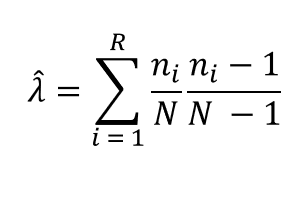
Calculate the Gini-Simpson diversity index in SAS

An article by David Corliss in Amstat News (Corliss D. (2025) "Quantifying Diversity: Calculating the Gini-Simpson Diversity Index") discusses a new statistical measure of diversity that was adopted by the US Census Bureau. The statistic is called the Gini-Simpson diversity index. The Census Bureau has published an article about how