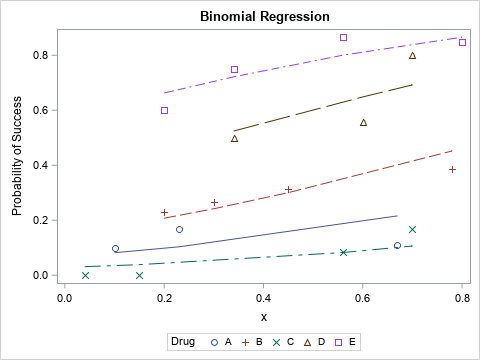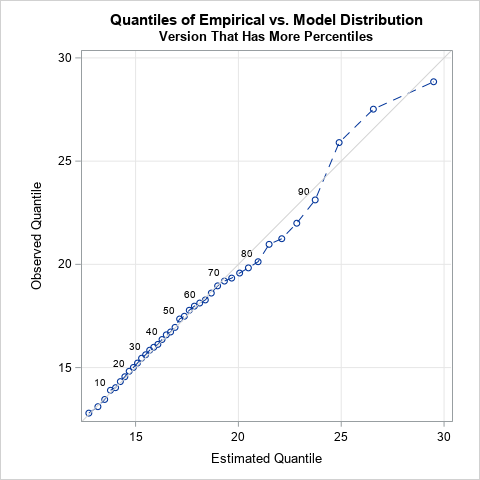
The quantile fit plot: Comparing empirical and predicted quantiles for a univariate model

A common task in statistics is to model data by using a parametric probability distribution, such as the normal, lognormal, beta, or gamma distributions. There are many ways to assess how well the model fits the data, including graphical methods such as a Q-Q plot and formal statistical tests such