Double, double toil and trouble;
Fire burn, and caldron bubble.
Macbeth, Act IV, Scene I
For the cyptanalyst or recreational puzzle solver, "double double" does not lead to toil or trouble. Just the opposite: The occurrence of a double-letter bigram in an enciphered word puzzle is quite fortunate. Certain double letters appear more frequently in English text than other double letters, which means that double letters can help the cryptanalyst use frequency analysis to solve simple substitution ciphers.
For example, in the famous ten-word quote at the top of this article, the double letter 'BB' occurs in the word 'bubble.' Suppose we count all instances of double letters in the complete speech by the three witches at the beginning of Act IV of Macbeth. In the witches' 210-word incantation, the following double letters appear:
- OO: 8 times
- BB: 4 times
- LL: 3 times
- DD: 2 times
- EE, GG, NN, and MM: 1 time
Of course, 210 words is not a very long chunk of text, and the witches' incantation is not typical of modern English text. Nevertheless, we can see from this simple exercise that some double letters appear more frequently than others. Presumably some double letters never occur (QQ and JJ, anyone?).
The frequency of double letters in an English corpus
Are the double letters in the witches' speech representative of the frequency with which double letters occur in a typical English text? To find out, let's take another look at the frequency of bigrams in Peter Norvig's analysis of a huge 744-billion-word corpus of documents that were digitized at Google. The following SAS/IML statements continue the program that analyzes bigrams. The matrix M is a 26 x 26 matrix that contains the proportion of every bigram in the corpus:
/* separate post on double letter combinations */ Letters = "A":"Z"; Doublets = vecdiag(M); /* extract matrix diagonal */ call sortndx(ndx, Doublets, 1, 1); /* create sorting index */ D = Doublets[ndx]; L = Letters[ndx];/* sort the bigrams */ print (D`)[c=L F=percent8.3]; |

The diagonal elements of the bigram matrix contain the proportions of double-letter bigrams: AA, BB, CC, and so forth. By sorting the diagonal elements, you can find the double-letter combinations that appear most frequently in the corpus. The most common double letter is L, with LL accounting for 0.6% of all bigrams. Other common double-letter bigrams are SS, EE, OO, and TT. Some double letters did not appear in the corpus: JJ, KK, QQ, VV, WW, and YY.
How to make sense of certain rare bigram frequencies?
I find it puzzling that the bigrams AA appear as often as the bigram ZZ. I would think articles about blizzards, puzzles, jazz, and pizza would completely swamp the few articles about aardvarks. I think the resolution to this quandary is that the corpus includes proper nouns, not just dictionary words. The double-A bigram will show up every time that there is a mention of AA and AAA batteries, the American Automobile Association (AAA) and proper nouns such as Paas egg-dying kits, Alderaan, and any boy named Aaron, Isaac, Jamaal, or Rashaad.
Similarly, although not many English words contain a double-X, the XX bigram shows up as often as ZZ. Presumably there are many articles that discuss the ExxonMobil energy company and the Exxon Valdez oil spill. The double-X bigram can also occur in Roman numerals and sporting events like Super Bowl XXXIV. And let's not forget the ubiquitous use of 'XXX' on the internet, which contributes two double-X bigrams to the count each time that it appears!
The distribution of frequencies for common bigrams
The following SAS/IML statements create a graph that shows the most common double-letter bigrams:
idx = loc(D>0.0001); /* get rid of rare or impossible bigrams */
D = D[idx]; L = L[idx];
ods graphics / width=600px height=300px;
title "Relative Frequency of Double Letters in Corpus";
call scatter(L, D) grid={x y}
label={"Letter" "Proportion"} datalabel=rowcatc(L||L); |
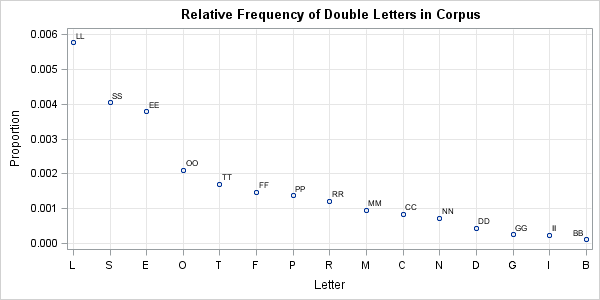
The graph (click to enlarge) shows that the top three double-letter bigrams are LL, SS, and EE. These occur more than twice as often as the next set of double-letter bigrams, which includes OO, TT, FF, PP, and RR.
Returning to the Three Witches' incantation in Macbeth, we note that the most common double letters in the speech are different from the most common letters in the Google corpus. This is to be expected: the frequencies in a small sample almost always deviate from the frequencies in a population or in a large sample. Nevertheless, there is some similarity. The OO bigram is the most frequent double-letter bigram in the witches' speech, and it is also fairly common (#4) among all double-letter bigrams in the Google corpus. The LL bigram also appears frequently in the incantation and in the corpus (#1). However, the BB bigram appears much more often in the incantation than would be expected by looking at the corpus because the "double double... caldron bubble" refrain is repeated four times in the short passage.
This leads to an interesting statistical question: how much variation is there in the frequencies? The Google corpus provides an estimate for frequencies "in the wild," which we can think of as being extremely close to the frequencies in the "population" of all written English text. Obviously a random passage of text of a certain length will exhibit sample variation. There is also variation due to the type of text. The distribution of words (and therefore letters) is different between scholarly writing, journalism, poetry, and Twitter messages. (U think? AFAIK, LOL!)
In a future blog post, I will discuss the variation in these frequencies. Then I think it is time to get "cracking" and apply all this frequency analysis to the problem of solving a simple substitution cipher such as you might encounter in the Cryptoquote word puzzle.

11 Comments
Some transliterations of Arabic words can be a rich source of double letters. The Oxford English Dictionary lists hajj, for a pilgrimage to Mecca, it was spelled with a double J in the 1910 edition of Encyclopaedia Britannica. The OED also lists riqq, which is a small tambourine and the only word with a double Q.
Pingback: The frequency of double-letters in Cryptoquotes - The DO Loop
Pingback: How to use frequency analysis to crack the Cryptoquote puzzle - The DO Loop
Hello
This is very interesting thank you. Just one question : some cypher texts are wrtitten without spaces. So we need to have the probability of bigrams across words. Ex : "I insist" has the "II" bigram in it. Does your statistics measure bigrams within words or within word and across words ?
Thank you
Great question! No, this is a simple analysis that does not include that complexity. This analysis is for recreational puzzle solvers; it can be the starting point for a more sophisticated analysis.
Thank you for your answer.
Nice info
What about bookkeeper? Isn't a dictionary a better place to find all bigrams, and then check their usage in a corpus?
You could do that. Novak was concerned with the empirical frequencies that appear in common English usage, which is quite different from the dictionary frequencies. I should stress that the summary statistics that I use in this article are rounded to 5 decimal places. Rather than saying that KK doesn't appear in the corpus, I should have said, "the proportion of the KK bigram is extremely small." I did better in the previous article when I said, "the grey cells are bigrams that were not found in the corpus or were extremely rare."
Just ran across your page as I was searching for statistics. Do you know of any for double letter bigrams relative to their placement in words? I would think the most common ending would be SS. There may be others that are more common in the center of words: BETTER, LETTER, WOOD, and others that appear near the beginning of words: ATTACHE, APPEAL, etc.
Great question. I do not know the answer. There are very few words with double first letters (aardvark, eerie, llama, ooze, ...). I like your guess that SS is the most frequent at the end, with LL being a close second?