It usually takes more than three weeks to prepare a good impromptu speech.
--Mark Twain
In the popular Cryptoquote puzzle, you are presented with an enciphered version of a quote by a famous person. One of the appeals of the puzzle for me is reading the deciphered quote, such as the witty aphorism by Mark Twain at the top of this post. Last week I discussed the frequency of double-letter bigrams in a huge English corpus. I asserted that a frequency analysis of "double letters can help the cryptanalyst ... to solve simple substitution ciphers."
In practice, double letters might not appear at all in a short quote. Even if they do appear, is the frequency distribution of double letters in short quotes the same as in Peter Norvig's analysis of a huge 744-billion-word corpus? If a certain double-letter bigram is expected to appear 0.05% of the time in lengthy texts, how often might it appear in pithy phrases that contains about 100 letters? Obviously the bigram will appear zero times for many phrases. Should we expect it to ever appear three times within a 100-letter quote? Four times?
To find out, I collected 120 (unenciphered) quotes. Some I took from Cryptoquote puzzles that I have been saving. Others I took from puzzles that appear on the DailyCryptogram.com web site. A few I sampled from the BrainyQuote web site. You can download the program that defines the data and produces the analyses in this article.
The quotes had an average length of 97 characters (mean=96.8; standard deviation 14.5). The minimum quote length was 66 characters; the maximum was 127 characters. The characters include spaces and punctuation. The average quote contains 59 bigrams, of which 1.8 were double-letter bigrams. The Mark Twain quote at the top of this article is atypical in that this 87-character quote contains five double-letter bigrams (out of 55).
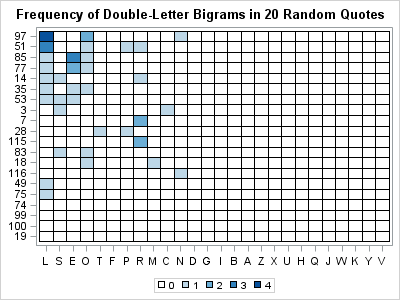
The heat map at the left shows the count for double-letter bigrams in 20 quotes that were chosen at random from the collection of 120 quotes. The vertical axis is ordered by the total count of bigrams. For example, the first row of the matrix says that the 97th quote in the data base has seven double letters: four are 'LL', two are 'OO', and one is 'NN'. The 51st quote has six double letters: three are 'LL' and the others are 'OO', 'PP', and 'RR'. Three of the quotes have only one double-letter combinations, and four have no double letters.
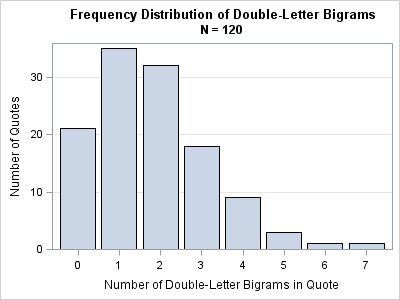
The bar chart at the left shows the distribution of counts for double-letter bigrams in the complete collection of 120 quotes. There are 21 quotes (18%) that do not contain a single double-letter. For these quotes, knowing the distribution of double-letter bigrams does not help to solve the puzzle. Most quotes contain one or two double-letters. For these puzzles you should probably guess that the double-letter bigram is a common one (LL, SS, EE, or OO) and see if your guess makes sense for the remainder of the puzzle. For quotes that have four or more double letters, it might be harder to guess which enciphered double-letter combinations corresponds to which common double-letter bigrams.
If you average the bigram counts, you can compute the proportion of times that 'AA', 'BB', 'CC', and so forth appear in the sample of 120 quotes. You can use statistics to compute a 95% confidence interval for the proportion of each double letter. The following graph (click to enlarge) displays the following information:
- An estimate for the proportion of each double-letter bigram. The estimate is the number of times that the bigram appears in the sample, divided by 120 (the sample size). These estimates are shown in the graph by a circle.
- A 95% confidence interval for each proportion, assuming that this sample of quotes is representative of the population of all quotes that have roughly 100 characters.
- The bigram proportions from Norvig's analysis of the Google corpus. These proportions are joined by a blue line to make it easier for your eye to traverse from one bigram to the next.
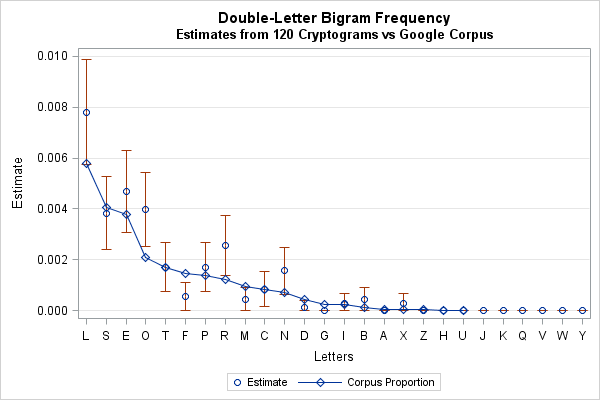
In this sample of quotes, the LL, OO, and RR bigrams appeared more often than you might expect from their frequencies in the corpus. The FF and HH bigrams appeared less often than expected.
So what have we learned?
- The heat map shows that there is considerable variation in the number and types of double-letter bigrams that appear in a short quote, such as is used in the Cryptoquote puzzle.
- The bar chart shows that one or two double-letter bigrams are expected in a short Cryptoquote. However, about 18% of the quotes did not contain any double letters.
- Although the frequency distribution of the double-letter bigrams was not identical to the distribution in longer texts, it is fairly close. For the purpose of solving word puzzles, you can safely use the frequency of double letters that I reported in my previous article.
