All Posts


I previously wrote an article about the Lambert W function. The Lambert W function is the inverse of the function g(x) = x exp(x). This means that you can use it to find the value of x such that g(x)=c for any value of c in the range of g, which


This article was written based off an interview. In the competitive world of data analytics, achieving a perfect score on the SAS certification exam is a remarkable feat. Dr. Jayeshkumar Kanani, a resolute data enthusiast from the Surat Municipal Institute of Medical Education and Research (SMIMER), recently accomplished this milestone.


Can tattooing's artistry survive the emergence of generative AI (GenAI) innovation? And what lessons does this hold for other industries navigating the blend of creativity and technology? When I was in Florida during my winter break, I got a new tattoo. After some conversation back and forth about the ideas


Every year, as Data Privacy Week sharpens the focus on protecting personal information, I’m reminded of a customer event a major North American bank hosted at SAS world headquarters. The bank’s chief data officer led a roundtable discussion on generative AI (GenAI) with a group of esteemed data and AI experts. The


SAS's Ann Kuo walks you through how SAS Tech Support developed an email classifier to clean up spam and misaddressed emails using SAS Viya's NLP-based text classifier


Let’s face it – early AI rollouts have been anything but smooth. Standout examples include McDonald’s attempt at using AI to take drive-through orders, which caused customers to plead with the AI to quit adding Chicken McNuggets to their orders. Or, Amazon’s AI-powered HR recruitment tool, which favored male job


Learn how insurers can combat AI-driven fraud, secure data and build trust in an increasingly digital world.

Many scientists compare the universe to a network of tiny vibrating strings, smaller than subatomic particles. String theory suggests that these strings, as they twist and vibrate give rise to everything around us – matter, energy and even forces like gravity. But this idea of interconnected threads isn’t just confined


SAS 9.4 will get a new maintenance release in 2025. Also, some older SAS releases and product versions will move to Limited Support.
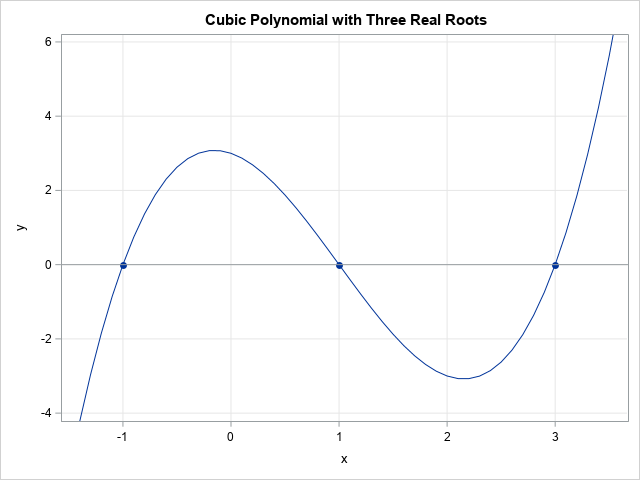
A SAS programmer had many polynomials for which he wanted to compute the real roots. By the Fundamental Theorem of Algebra, every polynomial of degree d has d complex roots. You can find these complex roots by using the POLYROOT function in SAS IML. The programmer only wanted to output


What happens if an employee unknowingly enters sensitive information into a public large language model (LLM)? Could that information then be leaked to other users of the same LLM? For example, if you ask ChatGPT or Claude to read and summarize a confidential contract, a patient record or a customer


Magnesium is the fourth most abundant element in the human body. This mineral plays a crucial role in well over 300 enzymatic reactions in the body, including energy production, muscle function, and DNA synthesis. Despite its importance, most of us don't get enough magnesium which can lead to potential health

Here's a SAS tip for you. Most SAS programmers know that SAS provides syntax that makes it easy to specify a list of variables. For example, you can use the hyphen and colon operators to specify lists of variables on many SAS statements: You can use the hyphen operator (-)
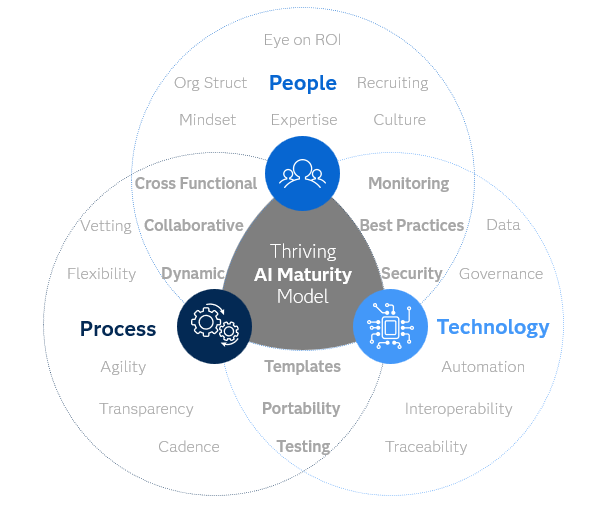

SAS' Sophia Rowland breaks down the roles of each team member in a long-term machine learning project and how they can better combine their efforts to increase efficiency and efficacy


Making a big purchase, such as a car or home, can be stressful for everyone involved, from doing the due diligence to identifying a good lender. Everyone wants to make the process smooth while mitigating risks. Banks and lenders also have more data to work with when making a lending