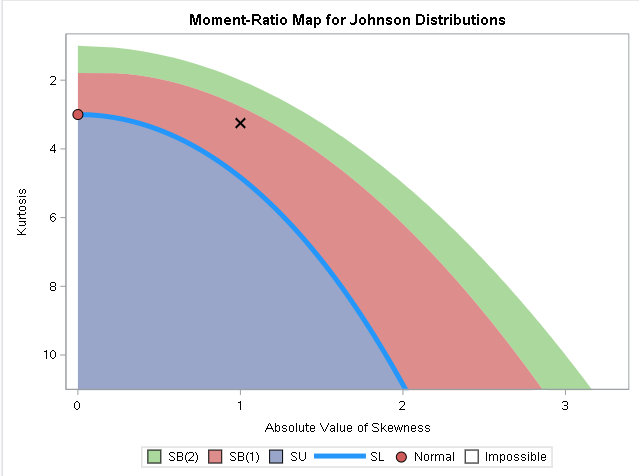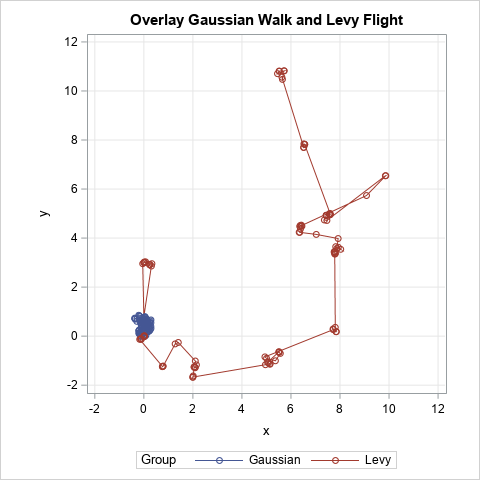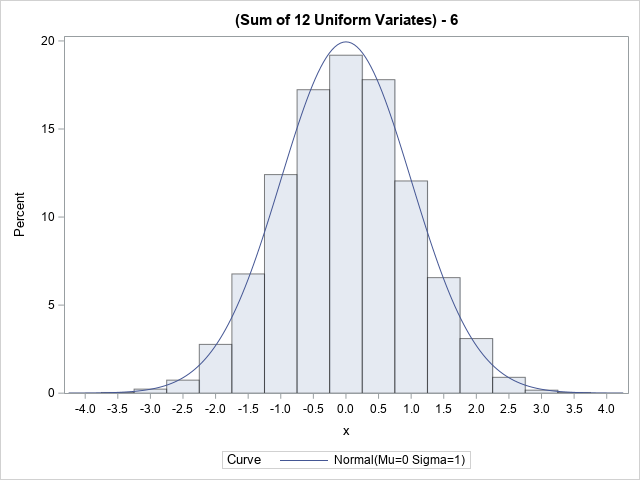
A historical method of generating random normal variates

Decades ago, it was a challenge to generate (pseudo-) random numbers that had good statistical properties. The proliferation of desktop computers in the 1980s and '90s led to many advances in computational mathematics, including better ways to generate pseudorandom variates from a wide range of probability distributions. (For brevity, I