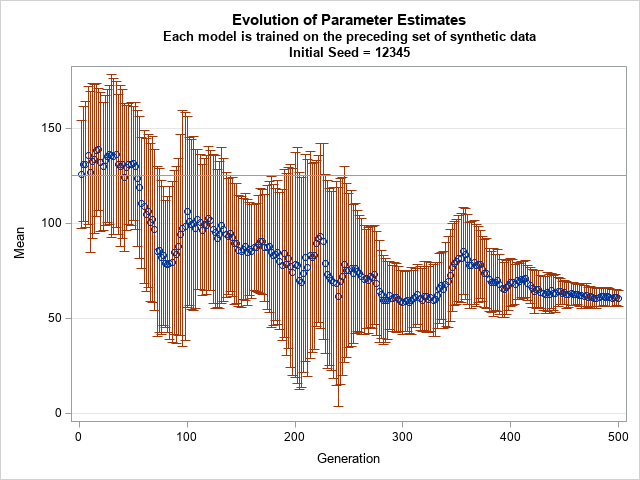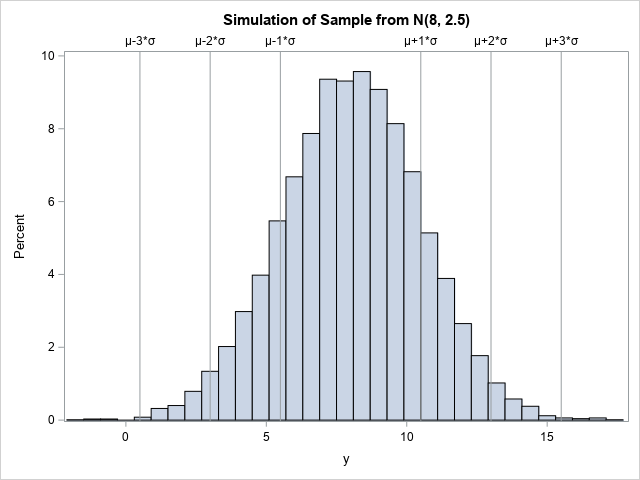
The three-sigma rule

A remarkable result in probability theory is the "three-sigma rule," which is a generic name for theorems that bound the probability that a univariate random variable will appear near the center of its distribution. This article discusses the familiar three-sigma rule for the normal distribution, a less-familiar rule for unimodal