Are you still using the old RANUNI, RANNOR, RANBIN, and other "RANXXX" functions to generate random numbers in SAS? If so, here are six reasons why you should switch from these older (1970s) algorithms to the newer (late 1990s) Mersenne-Twister algorithm, which is implemented in the RAND function. The newer RAND function (and the RANDGEN function in the SAS/IML language) provides the following advantages:
- A longer period. Thirty years ago, a "large" simulation might involve generating millions of random values. Today, you can generate millions of values in the blink of an eye. Correspondingly, today's large simulation studies generate billions of random values, and simulation studies are a standard tool for statistical programmers. The older RANXXX functions have a period that is less than 231, which is about two billion. (The period of a random number generator is the number of values that you can generate before the sequence starts to repeat.) In contrast, the RAND function implements the Mersenne-Twister algorithm, which has a period of about 219937 ≈ 4 x 106001. For comparison, the number of atoms in the observable universe is approximately 1080 and the number of seconds since the Big Bang is about 4 x 1017. Suffice it to say that if you use the RAND function you will never exceed the period and observe a repeated sequence.
- Superior statistical properties. Remember that what we call a "random number stream" is actually a pseudorandom stream that is created by running some algorithm. If you run statistical tests for randomness, the older RANXXX algorithms do not fare as well as the newer
Mersenne-Twister random number generator, which is known to have excellent statistical properties. For example, I recently wrote about the fact that a large uniformly distributed sample should contain duplicate values. I showed mathematically that 93% of samples of size 150,000 should contain at least one duplicate value, and I wrote a simulation that demonstrates that random samples from the RAND function have this property. In contrast, the RANUNI algorithm does not generate samples that have this property as shown by the following SAS/IML program:
proc iml; K = 150000; /* sample size */ s = j(K, 100, 1); /* create 100 samples; one per column */ u = ranuni(s); /* return random uniform values from RANUNI */ NumDups = K - countunique(u, "col"); /* number of dups in each sample */ call tabulate(vals, freq, NumDups); /* how many samples had duplicates? */ print freq[label="Sample size 150,000" colname=(char(vals))];
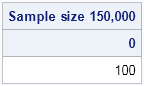
The RANUNI function generated 100 samples of size 150,000, but no sample contains a duplicate value. You can use similar code to show that the RANUNI function does not generate any duplicates in a sample of size one million, whereas the expected number of duplicates is 116 for a sample of that size. In contrast, the RAND function generates samples that are more "random," and therefore have the correct proportion of duplicate values.
- A simpler specification of the seed values. The syntax of the RANXXX functions requires that you provide a seed to each call, such as x = ranuni(1);. This leads some users to believe that changing the seed "midstream" results in a different stream. That is not correct: the first seed encountered determines the stream for the entire DATA step. The syntax for the RAND function makes it clearer that there is a single stream. You use the CALL STREAMINT routine to set the random number seed for the RAND function in the DATA step. Equivalently, you use the CALL RANDSEED routine in SAS/IML to set the random number seed for the CALL RANDGEN routine.
- A uniform syntax. The distributions that are supported by the RAND function agree in syntax with the other SAS functions for dealing with probability distributions: the PDF, CDF, and QUANTILE functions. The syntax for the RAND function is always x = RAND("Family", param1, param2, ...);
- Superior handling of certain regions of parameter space. In a parameterized family of distributions, sometimes very small or very large values of parameters are associated with degenerate or nearly degenerate distributions. For example, the beta distribution (which is continuous) approaches the Bernoulli distribution (which is discrete) in the limit as the shape parameters approach zero. Sometimes special algorithms are required to handle parameter values for which a distribution is nearly degenerate. The RAND function uses newer algorithms that handle these degenerate situations better than the older RANXXX algorithms.
- Continued development. When SAS adds support for a new distribution, it is added to the RAND (and RANDGEN) function. For example, in SAS/IML 12.1, the RANDGEN function added the Laplace, logistic, Pareto, Wald, and "NormalMixture" distributions. Although the older RANXXX functions are not going to vanish from traditional SAS, they are no longer being developed. New development is focused on enhancing features of the RAND and RANDGEN functions.
Edit: Here is a seventh reason: the old RANUNI and RANNOR functions are not supported in CAS. As of SAS 9.4M5, they are officially deprecated in SAS.
In summary, the old RANXXX function (and the aliases UNIFORM and NORMAL) are based on algorithms that were in vogue during the age of white leisure suits and shag carpeting. Better alternatives now exist. The older functions are fine for quickly generating data for an example or to illustrate a technique. However, if you are doing a serious simulation study, you should use the newer RAND function in Base SAS or the RANDGEN function in SAS/IML software.
P.S. Are you still using the older PROBNORM and other PROBXXX functions to compute the CDF of a distribution? Are you still using the older PROBIT and the XXXINV functions to compute the quantiles of a distribution? Do yourself a favor and switch to the newer CDF function and QUANTILE function, which are more accurate. See Reasons 5 and 6.

11 Comments
Rick, thank you for the explanation. It's time to go update some code...
Pingback: 13 popular articles from 2013 - The DO Loop
I'm gonna miss my white leisure suit. Great explanation of the Mersenne-Twister algo, Rick.
Can you comment on the time difference? Using the code below, my computer takes 13 seconds to get a billion random numbers using RANUNI and it takes 21 seconds to do the same thing with RAND. If the period is small enough and the difference in "statistical properties" is small enough, I'd prefer the function that takes less time.
data _null_;
do i=1 to 1e9;
x=ranuni(0);
end;
run;
data _null_;
do i=1 to 1e9;
x=rand('uniform');
end;
run;
The RANUNI function will be faster because the linear congruential function is so simple: X[n+1] = (aX[n]+c) mod m. If you are creating a small sample for test data, use whichever function you want. If you are doing a real scientific or statistical project, use RAND because the "difference in statistical properties" is significant and important.
Thanks for responding! I mainly use random numbers to do random sampling without replacement in a DATA step, as seen in http://blogs.sas.com/content/sastraining/2015/09/04/random-sampling-whats-efficient/
I'm trying to understand if the old algorithm is really so bad at, say, sampling ten million rows down to a random hundred thousand that I need to use the new function and wait longer for the output.
For sampling without replacement, the RANUNI function has a distinct advantage: it will never repeat a number until it is called 2^31 times, so you don't need to worry about adjusting the probabilities in the loop. You can simply write a DO loop:
For sampling WITH replacement, use PROC SURVEYSELECT or the RAND function.
That code does not work for sampling without replacement because it can output the same row multiple times. For example, when nobs=10 million, random values of 0.5 and 0.50000001 both point to the 5 millionth row.
Good point. I retract. Thus another reason I use PROC SURVEYSELECT: I am less likely to make stupid mistakes.
Pingback: How to choose a seed for generating random numbers in SAS - The DO Loop
Pingback: Implement five sampling methods in the SAS DATA step - The DO Loop