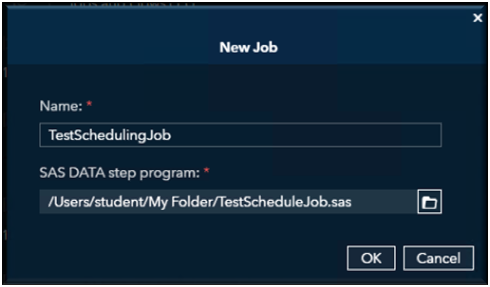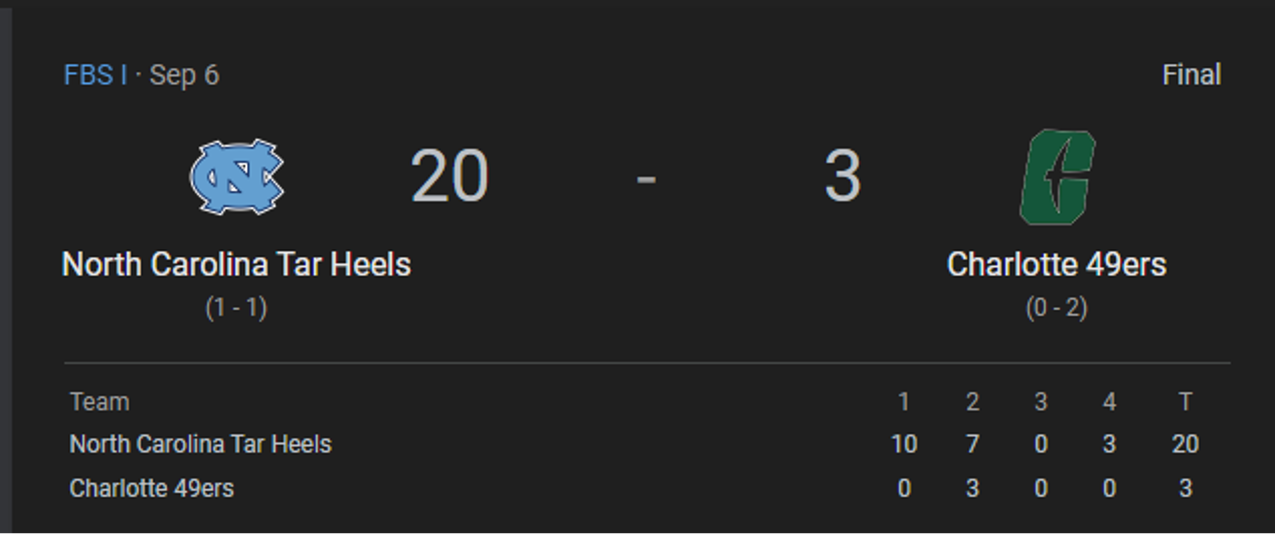
TouchDuck! Exploring unique features of SAS/ACCESS to DuckDB through college football

Using college football recruiting and talent data as an example, let's see how DuckDB’s flexibility and SAS integration streamline complex transformations and queries.