Uploading and visualizing custom shapefiles in SAS Viya

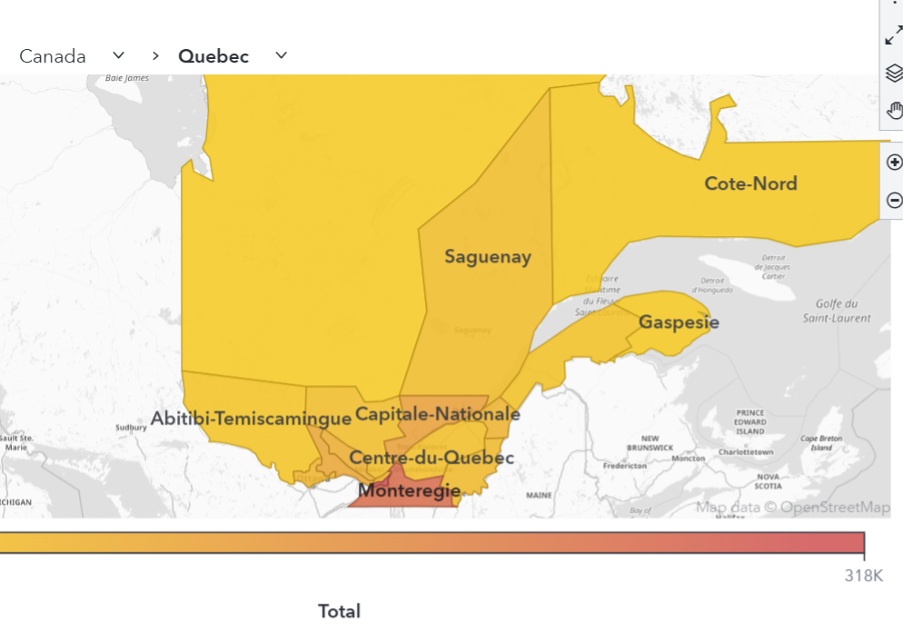
Learn how to create and visualize custom geographic regions in SAS Viya Visual Analytics, either by grouping existing map shapes or by uploading and configuring shapefiles to support regions with custom borders.