With the release of SAS Viya 3.4, you can easily build large-scale machine learning models and seamlessly publish and run models in Hadoop, or other external databases such as Teradata, without the data ever leaving the Hadoop environment. In this process, SAS Viya:
1) Converts the model into MapReduce Code.
2) Executes the MapReduce code.
3) Returns a new, scored dataset in Hadoop.
SAS Viya is a new, distributed in-memory product that allows users to easily build predictive models at scale. Using the SAS Model Studio interface, I can build complex models without the need to write large amounts of underlying code.
For this blog post, I'll go through the steps to build my model using a telecommunications dataset to predict customer churn. Under the “Data” tab, I can see all of my variables, assign the proper roles, and view the dataset.
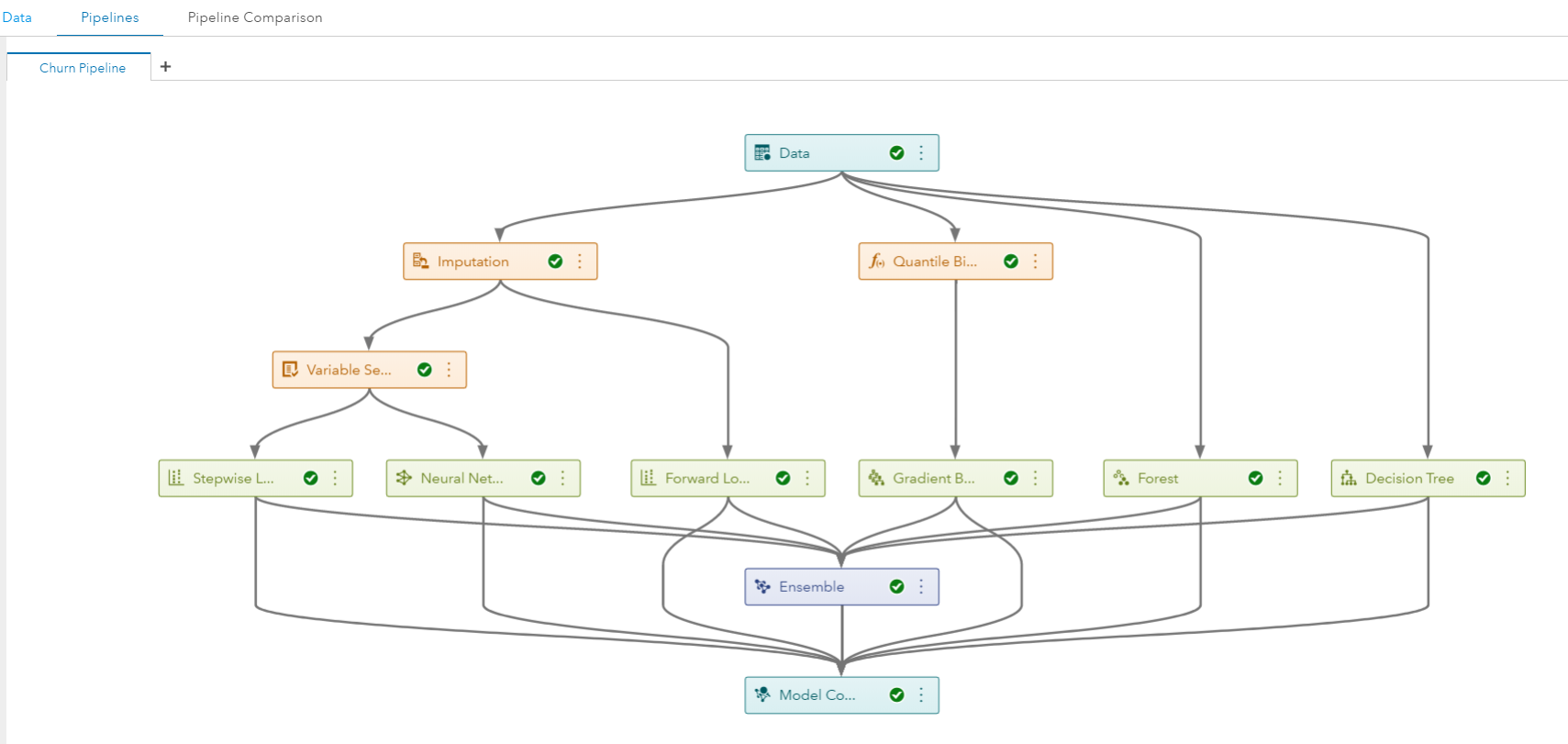
With the data prepared, I build a pipeline to perform data preprocessing steps such as imputation and binning and build several predictive models, including Regression, Neural Networks and Gradient Boosting. Pipelines are powerful because they automate the heavy lifting of the model building process, allowing you to solve problems faster. In addition, pipelines are re-usable across different users and datasets, allowing the adoption of best practices across an organization.
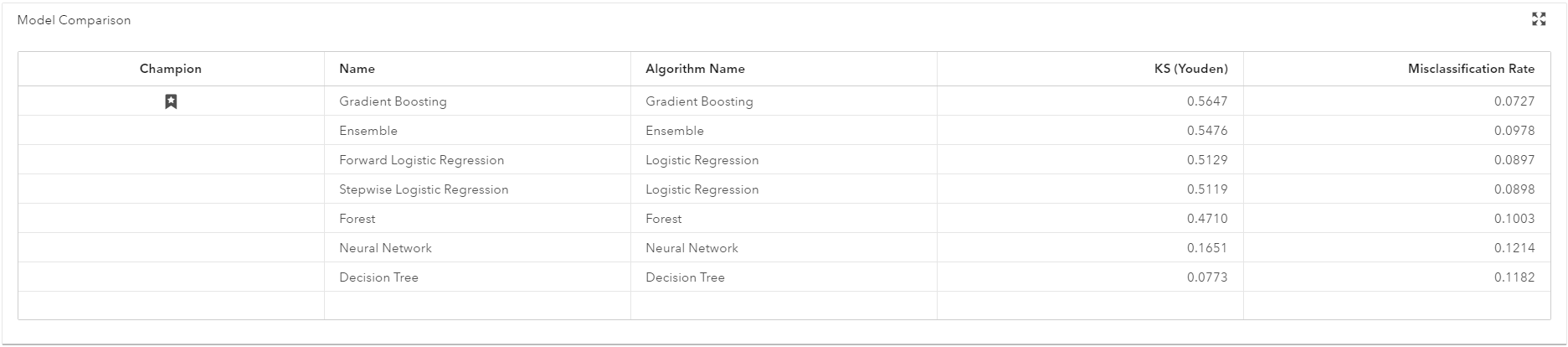
After building the models, I combine the models into one ensemble model with ease, and compare their performance on the validation sample. I determine that the gradient boosting model is the most accurate based on the misclassification rate. You can pick from a large number of accuracy criteria, including KS Statistic, AUC, MCR or F1.
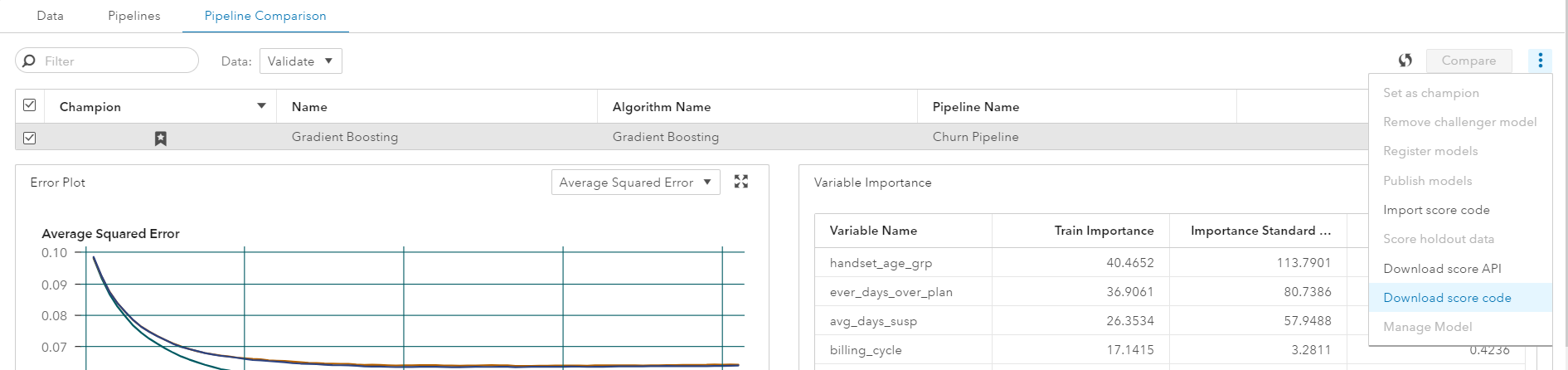
After having identified the best model, I publish the model to Hadoop. This allows me to perform future scoring at the data source, meaning data does not have to leave Hadoop. I could have configured the system to publish the model directly from SAS Model Studio; however, I publish and score the model via SAS code for maximum flexibility. With SAS Studio, I can easily control, and change, where I write my resulting models and datasets in Hadoop.
In the “Compare Models” tab, I then download the score code, which provides me with the following:
- sas file containing DS2 code that performs all the data preprocessing steps, such as binning and imputation, in the pipeline above. I load this .sas file into a location that can be viewed in SAS Studio.
- A .sashdat file in the “Models” Caslib, that is a binary representation of our model called ASTORE, used to score our model in Hadoop.
Opening up the dm_epscore.sas file in SAS Studio, the comments in the top tell me the ASTORE file needed to publish the model.

This scoring file allows the data preparation within the pipeline above to be published to Hadoop as well. In this case, the file is binning the variables before building the Gradient Boosting.

The scoring file then invokes the ASTORE file needed to score the model in Hadoop.

Now, I switch to SAS Studio to publish and score my model in Hadoop. The full code can be found here.
Below is the syntax to publish the model. I'm sure to set the classpath variable to the appropriate jar and config files for my Hadoop cluster. Note that you will need permission to read and write from the modeldir directory. Publishing the model converts the .sas scoring code and the ASTORE file into MapReduce code for execution in the cluster.
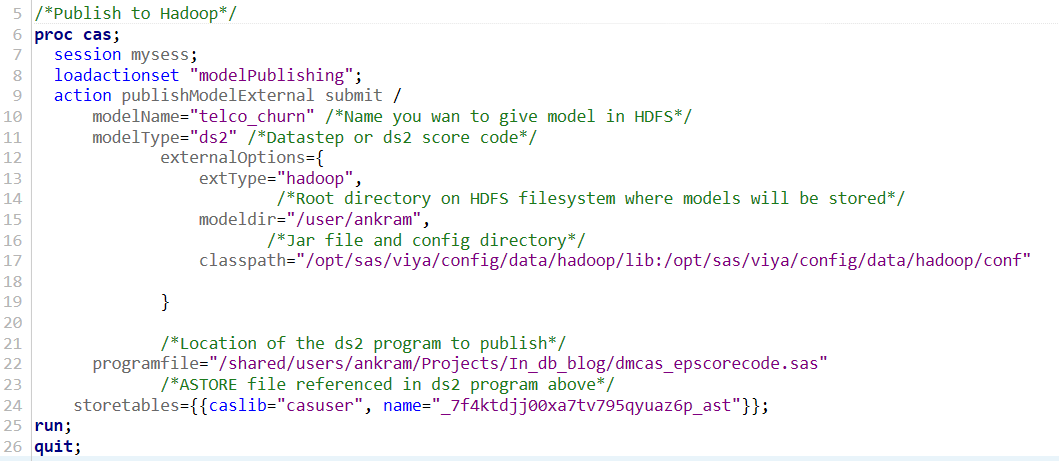
This publishing code will create a directory called “telco_churn” in my home directory in HDFS, /user/ankram. In a SAS Viya environment co-located with Hadoop, the “CASUSERHDFS” Caslib is by default pointed to this location, allowing me to ensure the “telco_churn” file was successfully published.

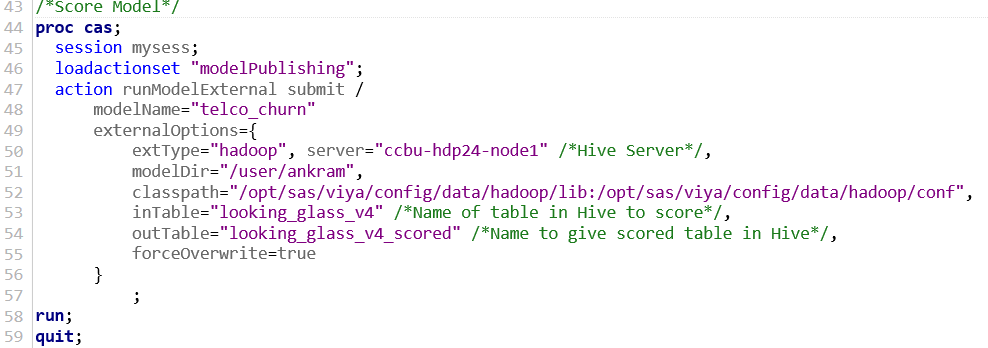
The next step is to score the model in Hadoop. The code below scores the “looking_glass_v4” table in Hive and create a new table called “looking_glass_v4_scored”, without the data ever leaving Hadoop.
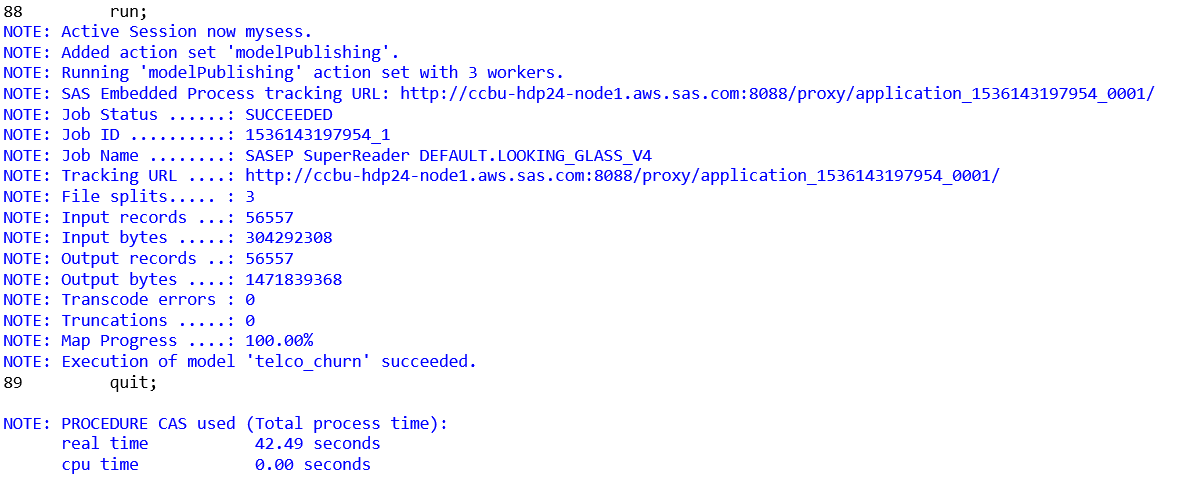
If everything is configured properly, the log should show that the SAS Embedded Process executed correctly.
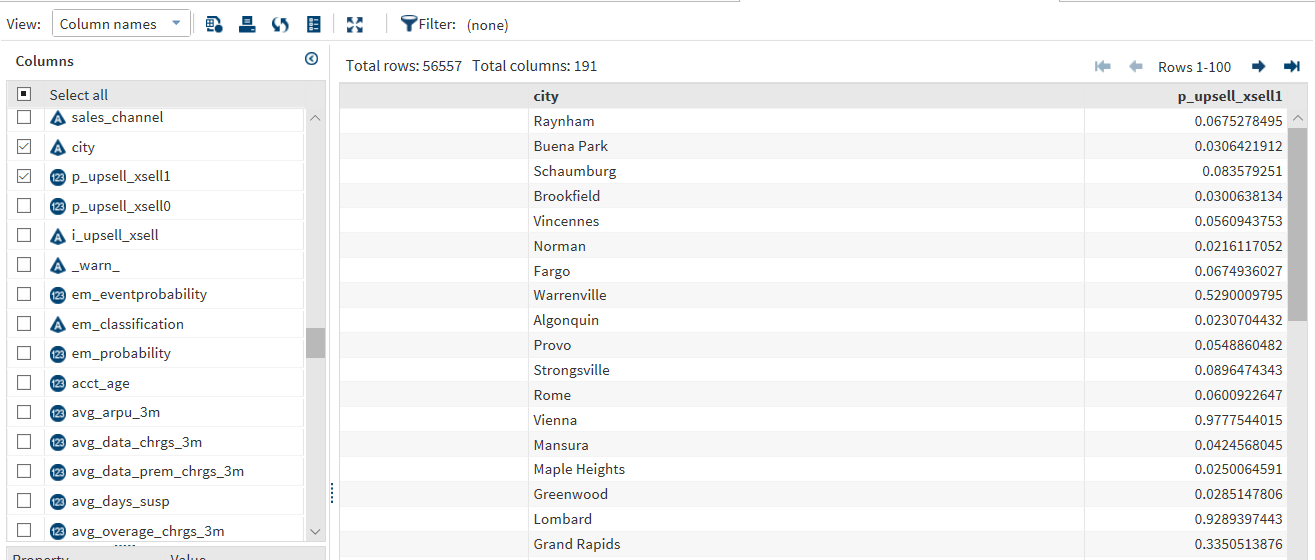
Using a previously setup Caslib called “Hivelib” that points to the default schema in the Hive Server, I can now load the “Looking_Glass_v4_scored” dataset into CAS to view the table.

Using the Table Viewer, I can then see the predicted probabilities of churn for each individual.
To conclude, many organizations have very large datasets, often times terabytes or larger, and often find that minimizing data movement is critical to successfully putting models into production. The in-database technologies for Hadoop on SAS Viya allow you and your fellow data scientists to easily prepare data and score large-scale models entirely in Hadoop, with the data never leaving the environment. You can now focus on solving more problems and are no longer at the mercy of large datasets and network latency.
