An important step of every analytics project is exploring and preprocessing the data. This transforms the raw data to make it useful and quality. It might be necessary, for example, to reduce the size of the data or to eliminate some columns. All these actions accelerate the analytical project that comes right after. But equally important is how you "productionize" your data science project. In other words, how you deploy your model so that the business processes can make use of it.
SAS Viya can help with that. Several SAS Viya applications have been engineered to directly add models to a model repository including SAS® Visual Data Mining and Machine Learning, SAS® Visual Text Analytics, and SAS® Studio. While the recent post on publishing and running models in Hadoop on SAS Viya outlined how to build models, this post will focus on the process to deploy your models with SAS Model Manager to Hadoop.
SAS Visual Data Mining and Machine Learning on SAS Viya contains a pipeline interface to assist data scientists in finding the most accurate model. In that pipeline interface, you can do several tasks such as import score code, score your data, download score API code or download SAS/BASE scoring code. Or you may decide – once you have a version ready - to store the model out of the development environment by registering your analytical model in a model repository.
Registered models will show up in SAS Model Manager and are copied to the model repository. That repository provides long-term storage and includes version control. It's a powerful tool for managing and governing your analytical models. A registered version of your model will never get lost, even it's deleted from your development environment. SAS models are not the only kind of models that SAS Model Manager can handle: Python, R, Matlab models can also be imported.
SAS Model Manager can read, write, and manage the model repository and provide actions for model editing, comparing, testing, publishing, validating, monitoring, lineage, and history of the models. It also allows you to easily demonstrate your compliance with regulations and policies. You can organize models into different projects. Within a project it's feasible to test, deploy and monitor the performance of the registered models.
Deploying your models
Deploying, a key step for any data scientist and model manager, can assist in bringing the models into production processes. Kick off deployment by publishing your models. SAS Model Manager can publish models to systems being used for batch processing or publish to applications where real-time execution of the models is required. Let's have a look at how to publish the analytical model to a Hadoop cluster and run the model into the Hadoop cluster. In doing so, you can score the data where it resides and avoid any data movement.
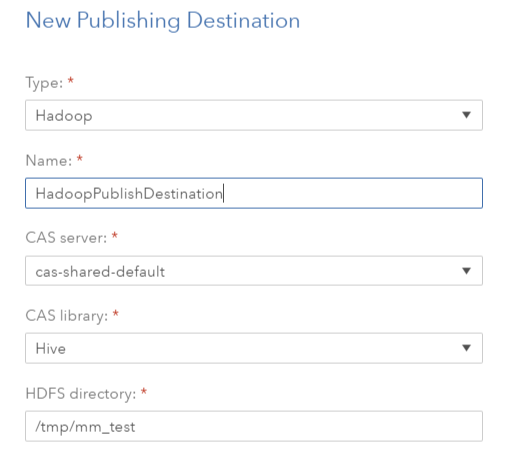
- Create the Hadoop public destination.
The easiest way to do this is via the Visual Interface. Go to SAS Environment Manager and click on the Publish destinations icon:
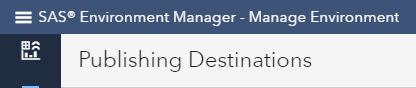

Click on the new destination icon:

Important:
- You will need Hadoop CAS library to create the Hadoop public destination.
- To run the scoring process in Hadoop you will also need SAS® Embedded Process installed on Hadoop cluster. Documentation how to do that can be found here.
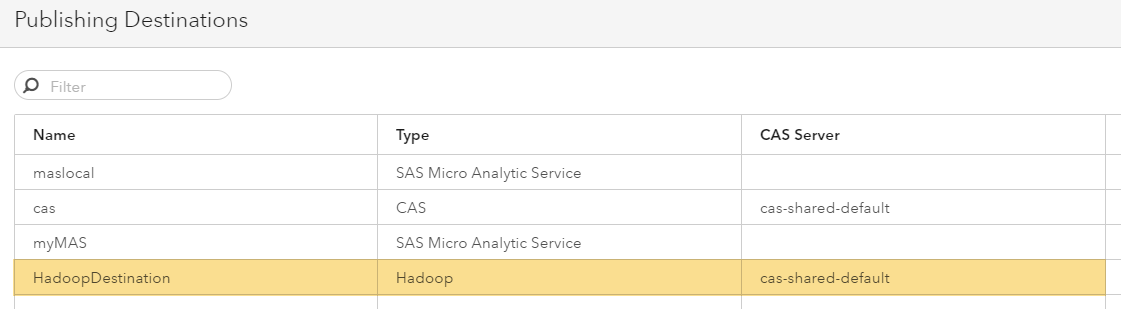
Now your newly created destination will show up and is available for publishing:
- Publish
Go to projects in SAS Model Manager and open the project from where you want to publish a model.
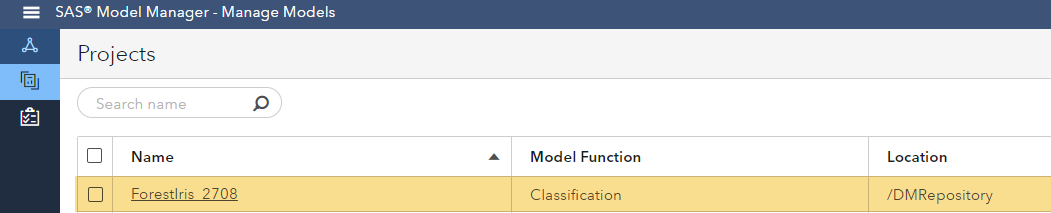
Within the models tab, select the models you want to publish:
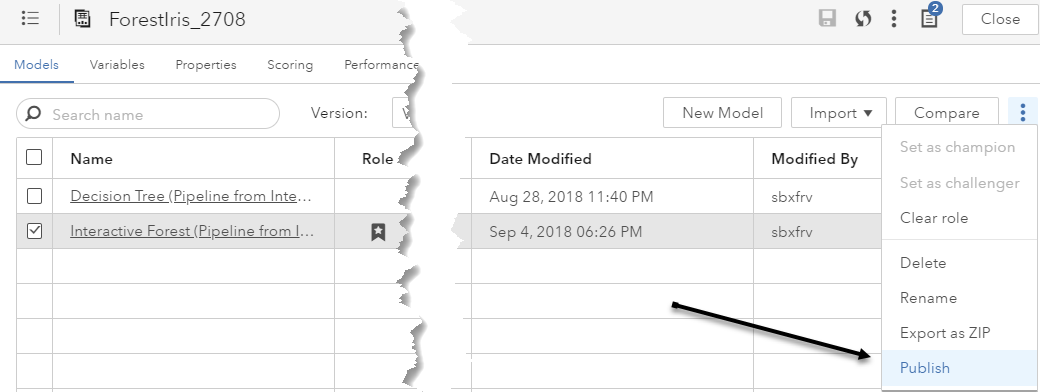
Select your newly created HadoopDestination as destination:
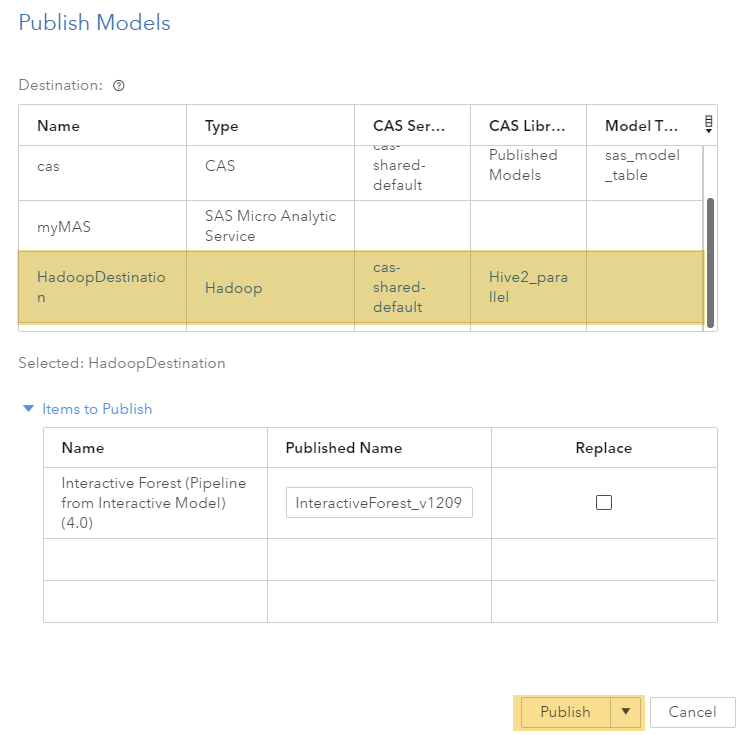
When you publish, the model score code is appropriately transformed and staged to the model scoring environment. A modelPublish service provides this functionality.
You have now published a new version directly into Hadoop and you can run the analytical model in Hadoop.
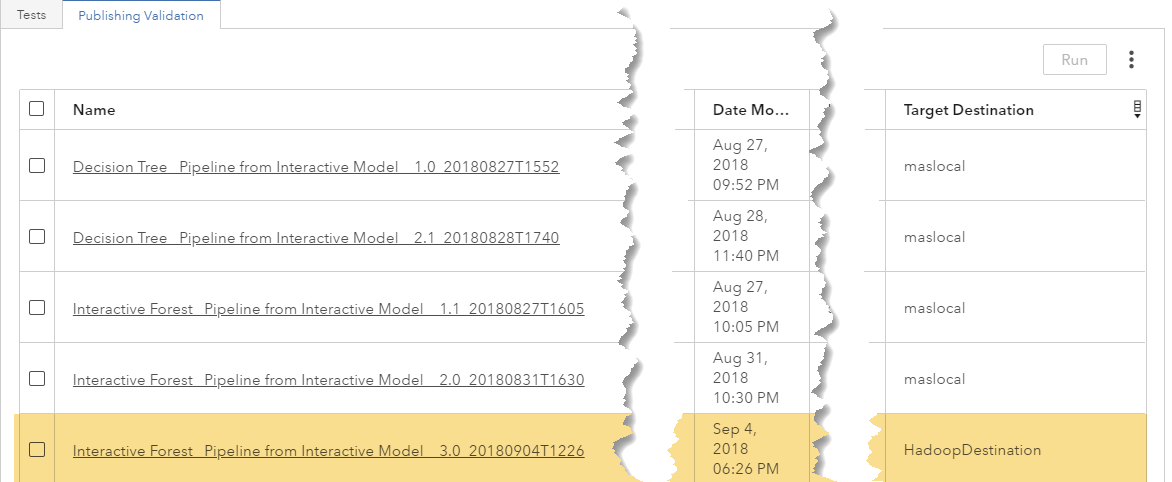
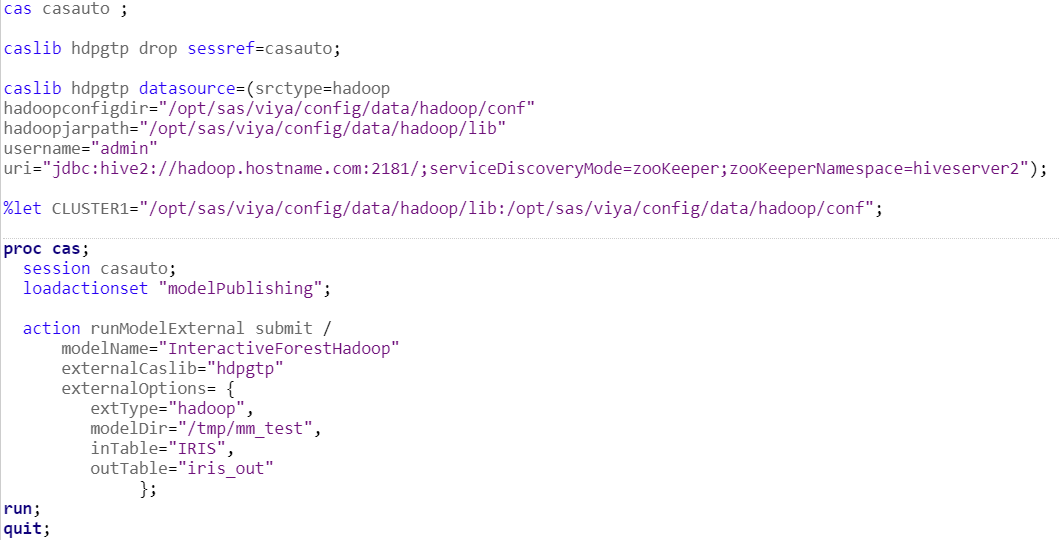
- Execution of the code directly in Hadoop.
Published models can be used for batch execution with a SAS program.
To do this, you can make use of modelPublising actionset and runModelExternal action.