최근 화두가 되는 빅데이터와 머신 러닝은 예측 모델의 성능을 올리기 위한 방안으로 시작된 것입니다. SAS VDMML(Visual Data Mining and Machine Learning)은 예측 모델 개발 시 텍스트 데이터를 이용하여 모델의 성능을 높여주는 텍스트 분석 툴로, 비즈니스 사용자와 데이터 사이언티스트, 예측 모델 개발자 모두가 활용할 수 있습니다.
텍스트 분석은 자연어 처리 과정이 필요합니다. 과정 또한 복잡하기 때문에 별도의 지식과 기술도 있어야 합니다. 하지만 SAS VDMML이 갖고 있는 다양한 머신러닝 알고리즘(랜덤 포레스팅, 그래디언 부스트 등)에 텍스트 마이닝 작업 노드를 추가하면 전처리 등의 과정을 자동으로 수행하고, 텍스트를 모델 개발에 쉽게 적용하여 상당한 수준으로 모델 성능을 개선할 수 있습니다.

활용 영역과 주요 사례
- 고객 관리 효율화
고객 게시글, 상담원과 대화 등 개인의 의도나 성향이 반영된 고객 텍스트 데이터는 연령, 성별, 직업, 자산 규모 등 정형 데이터와 함께, 고객의 성향을 파악하는 모형 개발에 활용할 수 있습니다. 고객의 관심 상품을 파악하여 이를 추천하는 추천 모형을 개발하거나, 고객의 불만 정보를 파악하고 이탈 가망 모델을 개발하여 고객 관리에 사용할 수 있습니다.
- 보험 사고 처리 효율화
사고 조사자의 메모 내용(텍스트 데이터)을 해당 청구 건의 정형 데이터와 통합하여 사고 청구에 대한 사기 감지 모델, 대위 청구 가망 모델 등을 개발하면, 보다 효율적으로 보험 사고 처리를 할 수 있으며 보험사의 수익성도 제고할 수 있습니다.

텍스트 데이터로 예측 모델 개발하기
SAS VDMML을 기반으로 보험 청구 데이터에 대한 예측 모델을 개발해보겠습니다. 해당 데이터에는 청구인의 연령, 직업 등의 정보와 사고 원인, 부상 위치 등 정형 데이터가 포함되어 있으며, 사고 조사자의 조사 메모가 텍스트 데이터로 포함되어 있습니다.
- 기본 알고리즘으로 예측 모델 개발
먼저, 텍스트 마이닝 예측 모델을 개발하기 위해 프로젝트를 생성합니다. 프로젝트에 사용되는 데이터는 보험 청구 건에 대한 사고 데이터입니다. 프로젝트가 생성되면 인포트된 데이터를 확인합니다.
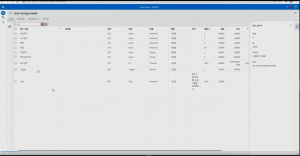
‘파이프라인’ 탭을 누르면 총 3개(2개의 회귀분석, 1개의 의사결정트리)의 기본 알고리즘이 학습되는 파이프라인을 확인할 수 있습니다. 이 3개 모델의 학습이 완료되면 ‘모델 비교’를 클릭하여 챔피언으로 선택된 모델을 확인합니다.
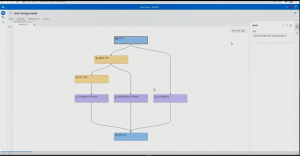
- 머신 러닝 알고리즘으로 예측 모델 개발
추가적으로 머신 러닝을 사용할 수 있는 파이프라인을 생성합니다. ‘고급 템플릿’을 선택하여 ‘확인’ 버튼을 누르면, 파이프라인이 생성되고, 3개의 머신 러닝 알고리즘(신경망, 포레스트, 그래디언부스팅)이 추가됩니다. 그리고 이 6개의 알고리즘 외에 알고리즘을 통합한 앙상블 모델까지 포함하여 총 7개의 모델이 학습됩니다.
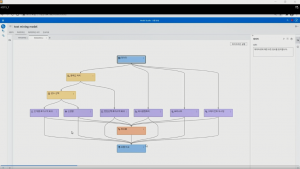
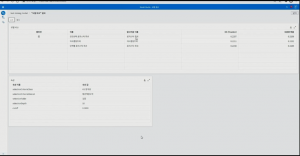
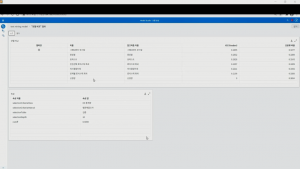
순서대로 학습이 완료되면 모델 비교 작업이 진행되고, ‘모델 비교’를 클릭하여 결과를 확인합니다. 그래디언 부스팅이 챔피언 모델로 선정됐으며, 전체적으로 기본 알고리즘에서는 23%대의 정확도 지표, 새로운 알고리즘에서는 26%의 정확도 지표를 보이고 있습니다.
- AutoML로 예측 모델 개발
SAS의 AutoML 기능 중 하나인 자동 파이프라인 생성은 인포트된 데이터들의 기본 프로파일링 작업을 통해 변수들의 분포, 타깃과의 관계 등을 파악하고, 후보 알고리즘을 적용하여 각각의 평가를 기초로 최선의 알고리즘을 추천합니다.
앞선 분석에서 그래디언 부스팅이 성능이 좋게 나왔으므로 자동 파이프라인에서도 그래디언 부스팅 위주로 파이프라인이 구성되었으며, 변수의 특성을 프로파일링하면서 변환 로직이 추가된 것을 확인할 수 있습니다. 회귀분석까지 포함하여 5개의 알고리즘과, 이들을 통합한 앙상블까지 총 6개의 모델이 학습됩니다. 모델 학습이 완료되고 모델을 비교하면 앙상블 모델이 29%의 정확도 지표로 챔피언 모델이 된 것을 알 수 있습니다.
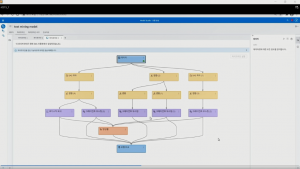
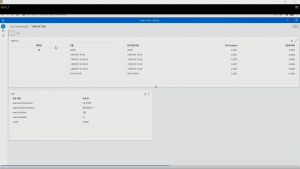
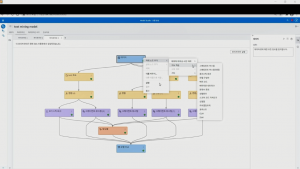
‘파이프라인 비교’ 탭을 눌러 지금까지 생성한 3가지 파이프라인을 비교해 보면 각 파이프라인의 챔피언 모델들끼리 비교할 수 있습니다.
- 텍스트 마이닝 알고리즘 반영
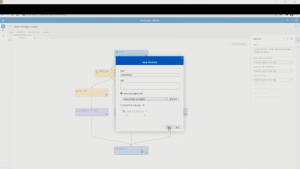
이제 자동 파이프라인의 잠금을 해제하고 텍스트를 사용한 모델을 추가해봅니다. 성능이 좋게 나왔던 그래디언 부스팅을 선택하여 추가하고, 그래디언 부스팅의 사전 작업으로 텍스트를 활용할 수 있는 텍스트 마이닝 노드를 추가하고 연결합니다. 테스트 마이닝의 언어를 한국어로 설정하고 ‘파이프라인 실행’을 클릭하면 기존 파이프라인에서 추가된 것만 작업이 이뤄집니다.
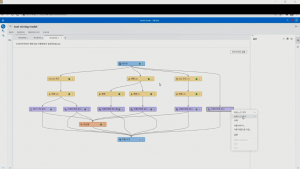
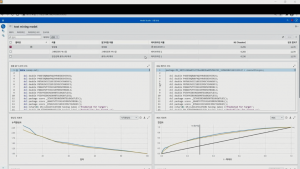
이 텍스트 마이닝 결과를 그래디언 부스팅이 받아서 학습을 수행합니다. 학습이 완료되면, 모델 비교 작업을 통해 기존 6개의 모델과 새로 작업한 텍스트 모델과의 성능을 비교합니다. 그 결과, 텍스트를 사용한 그래디언 부스팅이 챔피언 모델로 선정되었습니다. 기존 29%의 정확도 지표 대비 15%포인트 정도 증가한 높은 성능을 보이는 모델로 평가되었습니다.
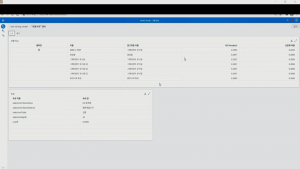
한편 ‘텍스트 마이닝의 결과’에서는 분석에 사용한 텍스트 단어, 분석에서 제외된 단어, 단어 토픽 등을 확인할 수 있습니다.
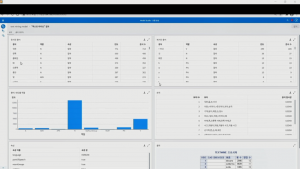
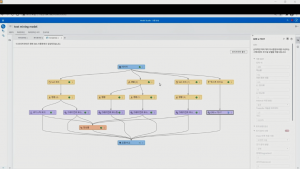
다시 파이프라인으로 돌아가서 텍스트를 사용한 그래디언 부스팅 결과를 보면, 그래디언 부스팅에 영향을 미친 중요 변수를 확인할 수 있습니다. 직업, 부상 위치, 사고 원인 등 정형 데이터보다는 자동차 사고와 관련된 단어, 손가락 부상과 관련된 단어가 학습 성능에 높은 영향을 주었으며, 이로 인해 모델의 성능이 개선되었음을 확인할 수 있습니다.
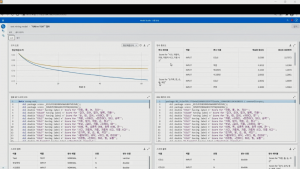
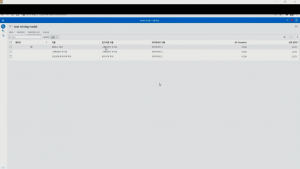
이처럼 SAS VDMML에는 비교적 손쉽게 모델의 성능을 개선할 수 있는 여러가지 기능이 있습니다. 복잡한 자연어 처리 기술과 지식 없이도 기본으로 탑재된 텍스트 분석 툴을 사용하여 텍스트 데이터를 모형 개발에 쉽게 사용할 수 있습니다.






