
Generative AI (GenAI) with large language models (LLMs) are now unlocking new levels of accuracy and scalability by providing a flexible and almost ready-to-go solution for extracting information.
Whenever LLMs come into the picture, there should be discussions about cost, security and privacy. Still, the main question as a data scientist is: “How can I trust an LLM (that is generative in nature) to provide a reliable, non-hallucinated result?”
Information extraction has proven to be a precious way to turn unstructured text into valuable structured data. For example, the resulting data can be used to improve predictive models, enrich an index to use in search or design interpretable categorization models.
The practice of information extraction dates back to the early 1970s and builds on solid foundations of natural language processing (NLP) and linguistics. Such an approach is robust and replicable, but depending on the complexity of the pattern to extract it might hit some barriers. For example, describing contextual dependencies with rules might be a daunting task if there is no standardization in the text documents. Moreover writing linguistic rules requires knowledge about the language and might not scale well in global scenarios. Then, how can we combine the best of two worlds?
Here is where the power of NLP in SAS Visual Text Analytics (VTA) comes into play!
Let’s assume I’ve been asked to extract undesirable effects from regulatory documents in the pharma industry. It’s hard to come up with a comprehensive list of undesirable effects, and even harder to do it for more than 20 languages (as required, for example, in the EU). So, we will use an LLM with a crafted prompt for extracting them, and then we will use SAS Visual Text Analytics to build a solid approach for trusting and verifying the quality of LLM extractions.
The approach is based on 5 main steps:
1. Tokenization and lemmatization of LLM extraction
2. Filter irrelevant or non-important terms
3. Leveraging noun groups identification
4. Automatic creation of linguistic rules
5. Rule inference and confidence score calculation
Let’s assume the LLM model extracted “Increase in liver transaminases” as an undesirable effect. Let’s go ahead and validate it.
Step 1: Tokenization and lemmatization
The extraction from the LLM is tokenized and lemmatization is applied to match each term with its lemma ( see _Parent_ column). Moreover, a part-of-speech message is attached to each token (see _Role_ column).

Step 2: Filter irrelevant or non-important terms
SAS VTA comes with predefined stoplists that can be used to filter out terms that can be ignored since they don’t carry specific information (articles, prepositions, etc.). If need be, the stoplist can also be customized.
Leveraging part-of-speech analysis, it’s also possible to filter out terms based on their role.
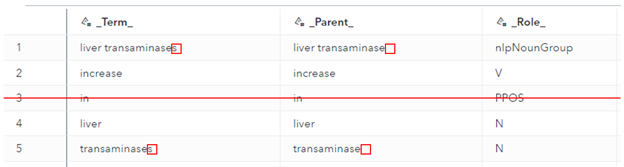
Step 3: Leveraging noun group identification
SAS VTA can extract noun groups, such as head nouns and closely tied modifiers. In this setting, it’s very useful to detect specific clinical concepts without prior knowledge (e.g., “liver transaminases” carry more information than “liver” or “transaminases” alone). In this step, the tokens that are part of a noun group are dropped when considered separately and just considered as part of the noun group.

Step 4: Automatic creation of linguistic rules
At this point, for each LLM extraction, we have subsets of only the most relevant terms, and we can build a weighted LITI rule that looks for those terms in a broader context. For more information about Language Interpretation for Textual Information (LITI) rules, see the SAS documentation link. Note that the LITI rule is automatically generated by concatenating the proper operators and the terms extracted in the previous steps.

Step 5: Rule inference and confidence score calculation
Finally, the same corpus that was used to extract information with the LLM can be scored against the LITI rule to check if the information is actually present. A confidence score is calculated based on the number of relevant terms matched by the rule. Confidence is a number between 0 and 1, where a higher value indicates a better quality of the extraction.
For example, see the matches identified by the LITI rules on text documents with some slight variations from the original extraction:

The process is robust enough to match documents with variations of the same concept. For example, “increased” and “increasing” instead of “increase”, or “transaminase” instead of “transaminases”. In the first document, the confidence is lower because it only matches “liver transaminase”. In that case, it might be required for a human to double-check the extraction, but still, the automation reduces a lot of the manual tasks to be completed.
Finally, this is an example where this approach can help identify cases of hallucination. Let’s assume the input document contains the following undesirable effects: “Changes of blood count such as thrombocytopenia and agranulocytosis,” and let’s assume that three different LLM models gave the results of the extractions in the table below:

The confidence score decreases if the LLM model hallucinates undesirable effects that were not present in the input document.
As a result, this methodology can also be used to evaluate different LLM models or different prompts by providing a quantifiable and robust metric of accuracy.
Note: This example is in English, but it can be replicated for all 33 languages supported by VTA, just setting the language parameter and re-using everything as is. See here a list of supported languages.
SAS Visual Text Analytics is a powerful tool that combines natural language processing, machine learning and linguistic rules. It can be used to build solid pipelines to process textual data such as quality check the information extracted by LLMs. It can also be used to measure confidence in the results and help build trust in your AI tools. The output is trustworthy, replicable and scalable, considering both the amount of data that can be seamlessly processed and the number of supported languages.
EXPLORE MORE | SAS Natural Language Processing Blog Posts